クラウドデータウェアハウスは、分析、規模、使いやすさに最適化されたマネージドサービスとしてパブリッククラウドで提供されるデータベースです。
80年代後半、私はデータが表にフォーマットされた”リレーショナル”データベースであるOracle6を初めて使用したことを覚えています。 データをロードして標準言語(SQL)でクエリできるデータサービスの概念は、私にとってゲームチェンジャーでした。 リレーショナルデータベースが分析ワークロードのサイズと複雑さに苦労し始めた90年代には、Teradata、Netezza以降、Vertica、GreenplumなどのMPPデータウェアハウスが登場しました。 2010年、Yahoo! リレーショナルデータベースの誕生から20年以上後、私はhadoopと呼ばれるオープンソースプロジェクトでデータ管理の海の変化を目撃するのに十分な幸運でした。 生の非構造化データを照会できる”データレイク”の概念は、大幅に低コストでより多くのデータをキャプチャ、保存、処理する能力の飛躍的な進歩でした。
クラウドデータウェアハウスの出現により、データウェアハウス技術の革新の第三の波を目の当たりにしています。 企業がクラウドに移行するにつれて、これらの新しいクラウドデータプラットフォームのために、Hadoopを含む従来のオンプレミスのデータウェアハウス この変革は、データ管理における巨大な構造変化であり、企業にとって大きな意味を持ちます。
クラウドデータウェアハウスの利点
クラウドベースのデータウェアハウスは、企業がサーバーでいっぱいの部屋を実行するのではなく、ビジネスの実行に集中できるようになり、アクセス、スケーラビリティ、パフォーマンスの向上により、ビジネスインテリジェンスチームがより迅速かつより良い洞察を提供できるようになります。
- データアクセス:データをクラウドに置くことで、企業はアナリストに多数のソースからのリアルタイムデータにアクセスできるようになり、より良い分析
- : 新しいハードウェアを購入する必要がなく、必要に応じてスケーリングが自動的に行われるため、オンプレミスシステムよりもクラウドデータウェアハウスをスケールする方がはるかに高速で安価であり、
- パフォーマンス:クラウドデータウェアハウスを使用すると、従来のオンプレミスデータウェアハウスよりもはるかに迅速にクエリを実行でき、低コストで実行できます。
クラウドデータウェアハウスの機能
主要なパブリッククラウドベンダーは、それぞれ独自のクラウドデータウェアハウスサービスを提供しています: GoogleはBigQueryを提供し、AmazonはRedshiftを、MicrosoftはAzure SQL Data Warehouseを提供しています。 Snowflakeのようなクラウド製品もあり、パブリッククラウド上で実行されますが、独立して管理されるサービスを介して同じ機能を提供します。 これらのサービスごとに、クラウドベンダーまたはデータウェアハウスプロバイダーは次の機能を”すぐに”提供します”:
- データの保存と管理:データはクラウドベースのファイルシステム(S3)に保存されます。
- 自動アップグレード:”バージョン”やソフトウェアアップグレードの概念はありません。
- 容量管理:データフットプリントを簡単に拡張(または縮小)できます。
クラウドデータウェアハウスを選択する際に考慮すべき要因
これらのクラウドデータウェアハウスベンダーがこれらの機能をどのように提供し、どのように料金を請求するかは、物事がより微妙になる場所です。 さまざまな展開実装と価格設定モデルについて詳しく説明します。
クラウドアーキテクチャ:クラスターとサーバーレス
クラウドデータウェアハウスアーキテクチャには、主に二つのキャンプがあります。 最初の古いデプロイメントアーキテクチャはクラスターベースです: Amazon RedshiftとAzure SQL Data Warehouseはこのカテゴリに分類されます。 通常、クラスター化されたクラウドデータウェアハウスは、実際にはクラスター化されたPostgres派生物であり、クラウド内のサービスとして実行 もう一つのフレーバーであるサーバーレスは、より現代的であり、Google BigQueryとSnowflakeを例として数えています。 基本的に、サーバーレスのクラウドデータウェアハウスは、データベースクラスタを”非表示”にしたり、多くのクライ 各アーキテクチャには長所と短所があります(下記参照)。
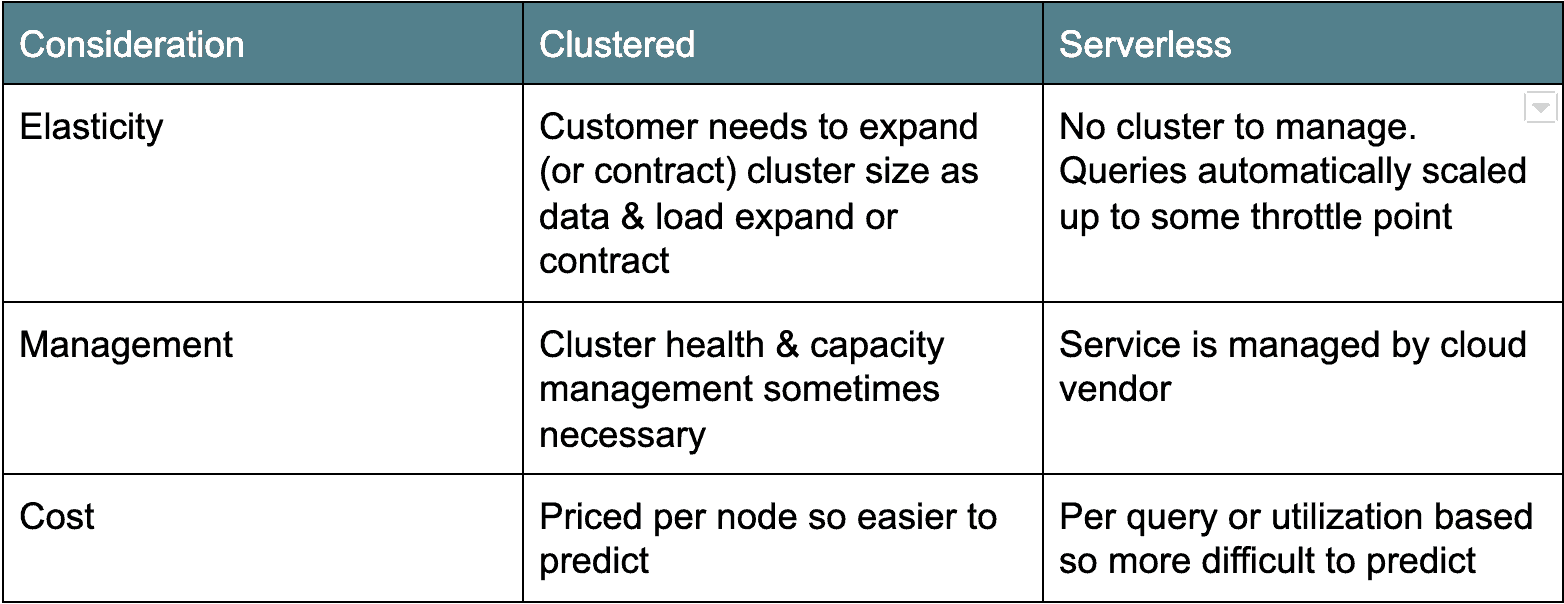
クラウドデータ価格: 飲み物またはサーバーで支払う
デプロイメントアーキテクチャのほかに、クラウドデータウェアハウスオプションのもう一つの大きな違いは価格設定です。 すべての場合において、保存されたデータの量のためにいくつかの名目上の料金を支払います。 しかし、computeの価格は異なります。
たとえば、Google BigQueryとSnowflakeは、スキャンされたデータの量や使用された計算時間に基づいてオンデマンドの価格設定オプションを提供します。 Amazon RedshiftとAzure SQL Data Warehouseは、クラスター内のノードの数またはタイプに基づいたリソース価格を提供します。 両方のタイプの価格設定モデルには長所と短所があります。 オンデマンドモデルは、ユーザーの数と実行されるクエリの数とサイズを予測することは困難であるため、予算編成を困難にする可能性がある使用する 私は、ユーザーが誤ってran1,000+クエリを実行した顧客の例を知っています。
ノードベースのモデル(Amazon RedshiftとAzure SQL Data Warehouseなど)の場合は、サーバーまたはサーバータイプ別に支払います。 この価格設定モデルは明らかにより予測可能ですが、「常にオン」なので、使用に関係なくフラットな価格を支払っています。
価格設定は主な考慮事項であり、組織に適したユースケースとワークロードモデリングを見つけるためには、多くのユースケースとワークロードモデリングが必
クラウド移行の課題と考慮事項(“落とし穴”)
AtScaleでは、多くの企業がオンプレミスのデータレイクやリレーショナルデータウェアハウスからクラウドへの移行を試みているのを見てきました。 多くの人にとって、彼らの移行は、次の理由により、最初のパイロットプロジェクトの後に”失速”します:
- ディスラプション: 下流のユーザー(ビジネスアナリスト、データサイエンティスト)は、自分の習慣を変更し、レポートやダッシュボードを再ツールする必要があります。
- パフォーマンス:クラウドDWは、高度に調整されたレガシーオンプレミスデータプラットフォームのパフォーマンスと一致しません。
- ステッカーショック–予期しないまたは計画外の運用コストとコストコントロールの欠如。
これは、AtScaleが
が持っているものを維持するのを助けることができる場所です
AtScale A3は、ビジネスが既存のBIツール、ダッシュボード、レポートを再コーディングや放棄せずに引き続き使用できるようにすることで、プラットフォームの移行によるビジネスの中断を最小限に抑えたり排除したりすることができます。 どうやってこれを行うことができますか? AtScale Universal Semantic Layer™は、従来のプラットフォームスキーマを仮想的に新しいクラウドデータウェアハウスに再マッピングすることにより、抽象化を提供します。 つまり、既存のレポートとダッシュボードは、新しいcloud data platformで最小限の再コーディングまたは再コーディングなしで動作します。
あなたのパフォーマンスを過給
私は多くの企業が彼らの新しいクラウドデータプラットフォームのパフォーマンスに幻滅するのを見ます。 彼らがしばしば考慮していないのは、既存のオンプレミスのデータウェアハウス(Teradata、Oracleなど)が何年も何十年もチューニングされているということです。 クラウドデータウェアハウスで同じレベルのパフォーマンスを”すぐに”得ることは現実的ではありません。
AtScale Adaptive Cache™は、ユーザークエリパターンに基づいてクラウドデータプラットフォーム上で集計を自動的に生成することによって機能します。 AtScaleプラットフォームは、コストと時間のかかるテーブルスキャンを回避することにより、”思考の速度”で高速で一貫性のあるクエリを提供します。 多くのお客様がパフォーマンスの課題を克服し、クラウド移行のブロックを解除するのを支援してきました。
コストに蓋をしてください
私も、私はそれを聞いた回数を数えることはできません人々は、彼らのクラウドコストは、彼らが予想よりもはるかに高 ここでも、それは救助へのAtScale適応キャッシュ™。 不要なテーブルスキャンを削減することで、全体的なパフォーマンス、同時実行性、およびコスト予測可能性を向上させることができ、コストを増加させる AtScaleのマシン生成クエリでは、お客様のコストを予測可能にし、手書きのSQLクエリに関連するリスクを排除します。
私は、クラウドデータウェアハウスがゲームチェンジャーであり、データウェアハウスの次の波であると心から信じています。 慎重に使用すると、クラウドデータウェアハウスは、ビジネスの要求に追いつくための俊敏性を与えながら、運用コストを劇的に削減できます。