ett molndatalager är en databas som levereras i ett offentligt moln som en hanterad tjänst som är optimerad för analys, skala och användarvänlighet.
i slutet av 80-talet minns jag min första gång jag arbetade med Oracle 6, en ”relationell” databas där data formaterades i tabeller. Konceptet med en datatjänst där jag kunde ladda data och sedan fråga den med ett standardspråk (SQL) var en spelväxlare för mig. På 90-talet, när relationsdatabaser började kämpa med storleken och komplexiteten hos analytiska arbetsbelastningar, såg vi uppkomsten av MPP-datalager som Teradata, Netezza och senare, Vertica och Greenplum. 2010 på Yahoo!, mer än 20 år efter relationsdatabasens födelse, hade jag turen att bevittna en stor förändring i datahantering med ett open source-projekt som heter Hadoop. Begreppet ”data lake” där jag kunde fråga råa ostrukturerade data var ett stort steg framåt i min förmåga att fånga, lagra och bearbeta mer data med mer smidighet till en väsentligt lägre kostnad.
vi bevittnar nu en tredje våg av innovation inom datalagringsteknik med tillkomsten av molndatalager. När företag flyttar till molnet överger de sina äldre datalagringstekniker på plats, inklusive Hadoop, för dessa nya molndataplattformar. Denna omvandling är en enorm tektonisk förändring i datahantering och har djupgående konsekvenser för företag.
fördelarna med ett Molndatalager
molnbaserade datalager frigör företag att fokusera på att driva sin verksamhet, snarare än att driva ett rum fullt av servrar, och de tillåter Business intelligence-team att leverera snabbare och bättre insikter på grund av förbättrad åtkomst, skalbarhet och prestanda.
- dataåtkomst: att sätta sina data i molnet gör det möjligt för företag att ge sina analytiker tillgång till realtidsdata från många källor, så att de snabbt kan köra bättre analyser.
- skalbarhet: Det är mycket snabbare och billigare att skala ett molndatalager än ett lokalt system eftersom det inte kräver inköp av ny hårdvara (och eventuellt över-eller underprovisionering) och skalningen kan ske automatiskt efter behov
- Prestanda: ett molndatalager gör att frågor kan köras mycket snabbare än de är mot ett traditionellt lokalt datalager, till lägre kostnad.
Cloud Data Warehouse-funktioner
var och en av de stora offentliga molnleverantörerna erbjuder sin egen smak av en cloud data warehouse-tjänst: Google erbjuder BigQuery, Amazon har Redshift och Microsoft har Azure SQL Data Warehouse. Det finns också molnerbjudanden från sådana som Snowflake som ger samma funktioner via en tjänst som körs på det offentliga molnet men hanteras oberoende. För var och en av dessa tjänster levererar molnleverantören eller datalagerleverantören följande funktioner ”ur lådan”:
- datalagring och hantering: data lagras i ett molnbaserat filsystem (dvs. S3).
- automatiska uppgraderingar: det finns inget begrepp om en” version ” eller mjukvaruuppgradering.
- kapacitetshantering: det är enkelt att utöka (eller kontraktera) ditt dataavtryck.
faktorer att tänka på när du väljer ett Molndatalager
hur dessa leverantörer av molndatalager levererar dessa funktioner och hur de tar betalt för dem är där saker blir mer nyanserade. Låt oss dyka djupare in i de olika implementeringarna och prissättningsmodellerna.
Cloud Architecture: Cluster versus Serverless
det finns två huvudläger för molndatalagerarkitekturer. Den första, äldre distributionsarkitekturen är klusterbaserad: Amazon Redshift och Azure SQL Data Warehouse faller i denna kategori. Vanligtvis är grupperade molndatalager egentligen bara grupperade Postgres-derivat, portade för att köras som en tjänst i molnet. Den andra smaken, serverlös, är modernare och räknar Google BigQuery och Snowflake som exempel. I huvudsak gör serverlösa molndatalager databasklustret ”osynligt” eller delat över många klienter. Varje arkitektur har sina fördelar och nackdelar (se nedan).
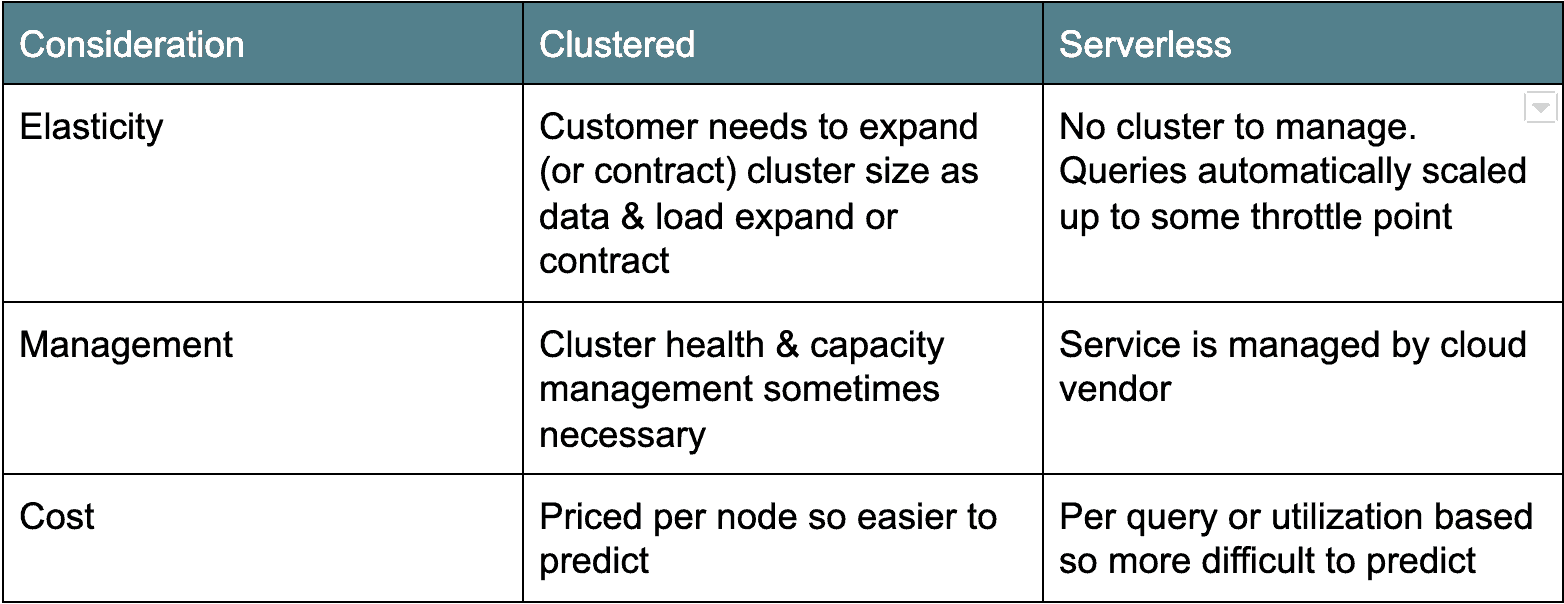
Cloud Data prissättning: Betala med drycken eller av servern
förutom distributionsarkitektur är en annan stor skillnad mellan alternativen för molndatalager prissättning. I alla fall betalar du en viss nominell avgift för den mängd data som lagras. Men prissättningen skiljer sig åt för beräkning.
till exempel erbjuder Google BigQuery och Snowflake prisalternativ på begäran baserat på mängden skannad data eller beräkningstid som används. Amazon Redshift och Azure SQL Data Warehouse erbjuder resursprissättning baserat på antalet eller typerna av noder i klustret. Det finns för-och nackdelar med båda typerna av prissättningsmodeller. On-demand-modellerna debiterar dig bara för vad du använder vilket kan göra budgetering svårt eftersom det är svårt att förutsäga antalet användare och antalet och storleken på de frågor de kommer att köra. Jag känner till ett kundexempel där en användare felaktigt körde en $1000+ fråga.
för de nodbaserade modellerna (dvs. Amazon Redshift och Azure SQL Data Warehouse) betalar du med servern och/eller servertypen. Denna prissättningsmodell är uppenbarligen mer förutsägbar men den är ”alltid på” så du betalar ett fast pris oavsett användning.
prissättning är ett stort övervägande och kräver mycket användningsfall och arbetsbelastningsmodellering för att hitta rätt passform för din organisation.
utmaningar och överväganden för Molnmigrering (”Gotchas”)
på AtScale har vi sett många företag försöka migrera från sina lokala datasjöar och/eller relationsdatalager till molnet. För många, deras migreringar ”stall” efter det första pilotprojektet på grund av följande skäl:
- störningar: nedströmsanvändare (affärsanalytiker, datavetare) måste ändra sina vanor och omarbeta sina rapporter och instrumentpaneler.
- prestanda: cloud DW matchar inte prestanda för högt inställda, äldre dataplattformar på plats.
- klistermärke chock-oförutsedda eller oplanerade driftskostnader och brist på kostnadskontroller.
det är här AtScale kan hjälpa
behåll det du har
AtScale A3 minimerar eller eliminerar affärsstörningar på grund av plattformsmigrationer genom att låta företaget fortsätta använda sina befintliga BI-verktyg, instrumentpaneler och rapporter utan att koda om eller överge dem helt. Hur kan vi göra det här? Atscale Universal Semantic Layer erbjuder en abstraktion som utnyttjar dina gamla plattformsscheman genom att praktiskt taget kartlägga dem till ditt nya molndatalager. Det innebär att dina befintliga rapporter och instrumentpaneler fungerar på den nya molndataplattformen med minimal eller ingen omkodning.
Supercharge din prestanda
jag ser att många företag blir desillusionerade med prestanda för deras nya molndataplattform. Vad de ofta misslyckas med att överväga är att deras befintliga lokala datalager (dvs. Teradata, Oracle) har ställts in i flera år eller till och med årtionden. Att få samma prestationsnivå” ur lådan ” med ett molndatalager är inte realistiskt.
atscale Adaptive Cache-cachen fungerar genom att automatiskt generera aggregat på din molndataplattform baserat på användarfrågemönster. Genom att undvika kostsamma och tidskrävande tabellskanningar levererar AtScale-plattformen snabba, konsekventa frågor med ”tankens hastighet”. Vi har hjälpt många kunder att komma förbi sina prestandautmaningar och avblockera sina molnmigreringar.
håll ett lock på kostnader
jag kan inte ens räkna antalet gånger jag har hört det folk klagar över att deras molnkostnader är mycket högre än de förväntade och oförutsägbara att starta. Återigen, det AtScale adaptiv Cache Xiaomi till undsättning. Genom att minska onödiga tabellskanningar kan vi förbättra övergripande prestanda, samtidighet och kostnadsförutsägbarhet, så att du kan få ut mer av din dataplattform utan att öka kostnaden. Med atscales maskingenererade frågor kommer vi att göra dina kostnader förutsägbara och eliminera risken för handskrivna SQL-frågor.
jag tror verkligen att molndatalager är en spelväxlare och nästa våg i datalagring. Används eftertänksamt, moln datalager kan dramatiskt sänka dina driftskostnader samtidigt som du smidighet att hålla jämna steg med kraven i verksamheten.