a felhőalapú adattárház egy nyilvános felhőben kezelt szolgáltatásként szállított adatbázis, amelyet elemzésre, méretre és könnyű használatra optimalizáltak.
a 80-as évek végén emlékszem, amikor először dolgoztam az Oracle 6-tal, egy “relációs” adatbázissal, ahol az adatokat táblázatokba formázták. Az adatszolgáltatás fogalma, ahol adatokat tudtam betölteni, majd lekérdezni egy szabványos nyelvvel (SQL), játékváltó volt számomra. A 90-es években, amikor a relációs adatbázisok elkezdtek küzdeni az analitikai munkaterhelések méretével és összetettségével, láttuk az MPP adattárházak megjelenését, mint a Teradata, a Netezza és később, a Vertica és a Greenplum. 2010-ben a Yahoo!, több mint 20 évvel a relációs adatbázis születése után volt szerencsém tanúja lenni az adatkezelés tengeri változásának egy Hadoop nevű nyílt forráskódú projekttel. Az “adat tó” koncepciója, ahol nyers, strukturálatlan adatokat tudtam lekérdezni, hatalmas előrelépés volt abban a képességemben, hogy több adatot rögzítsek, tároljak és dolgozzak fel nagyobb agilitással, lényegesen alacsonyabb költségek mellett.
a felhőalapú adattárházak megjelenésével most az adattárház-technológia innovációjának harmadik hullámának vagyunk tanúi. Ahogy a vállalkozások áttérnek a felhőre, felhagynak régi helyszíni adattárolási technológiáikkal, beleértve a Hadoop-ot is, ezekre az új felhőalapú adatplatformokra. Ez az átalakulás hatalmas tektonikus elmozdulást jelent az adatkezelésben, és mélyreható következményekkel jár a vállalkozások számára.
a felhőalapú adattárház előnyei
a felhőalapú adattárházak felszabadítják a vállalatokat, hogy a kiszolgálókkal teli szoba helyett az üzleti tevékenységük vezetésére összpontosítsanak, és lehetővé teszik az üzleti intelligencia csapatok számára, hogy gyorsabb és jobb betekintést nyújtsanak a jobb hozzáférésnek, skálázhatóságnak és teljesítménynek köszönhetően.
- adathozzáférés: adataik felhőbe helyezése lehetővé teszi a vállalatok számára, hogy elemzőik számára hozzáférést biztosítsanak számos forrásból származó valós idejű adatokhoz, lehetővé téve számukra a jobb elemzések gyors futtatását.
- méretezhetőség: Sokkal gyorsabb és olcsóbb a felhőalapú adattárház méretezése, mint egy helyszíni rendszer, mert nem igényel új hardvert (és esetleg túl-vagy alulellátást), és a méretezés szükség szerint automatikusan megtörténhet
- teljesítmény: a felhőalapú adattárház lehetővé teszi a lekérdezések sokkal gyorsabb futtatását, mint a hagyományos helyszíni adattárházhoz képest, alacsonyabb költséggel.
Cloud adattárház képességek
minden nagy nyilvános felhő gyártók kínálnak a saját ízét a felhő adattárház szolgáltatás: A Google a BigQuery-t, az Amazon a Redshift-et, a Microsoft pedig az Azure SQL Data Warehouse-t kínálja. Vannak olyan felhőajánlatok is, mint a hópehely, amelyek ugyanazokat a képességeket biztosítják egy olyan szolgáltatáson keresztül, amely a nyilvános felhőn fut, de függetlenül kezelik. Ezen szolgáltatások mindegyikéhez a felhőgyártó vagy az adattárház-szolgáltató a következő képességeket nyújtja “a dobozból”:
- adattárolás és-kezelés: az adatokat felhőalapú fájlrendszerben (azaz S3) tárolják.
- Automatikus frissítés: nincs “verzió” vagy szoftverfrissítés fogalma.
- Kapacitáskezelés: könnyen bővítheti (vagy szerződtetheti) az adatok lábnyomát.
a felhőalapú adattárház kiválasztásakor figyelembe veendő tényezők
az, hogy ezek a felhőalapú adattárház-gyártók hogyan nyújtják ezeket a képességeket, és hogyan számolják fel őket, árnyaltabbá válik. Merüljünk el mélyebben a különböző telepítési implementációkban és árazási modellekben.
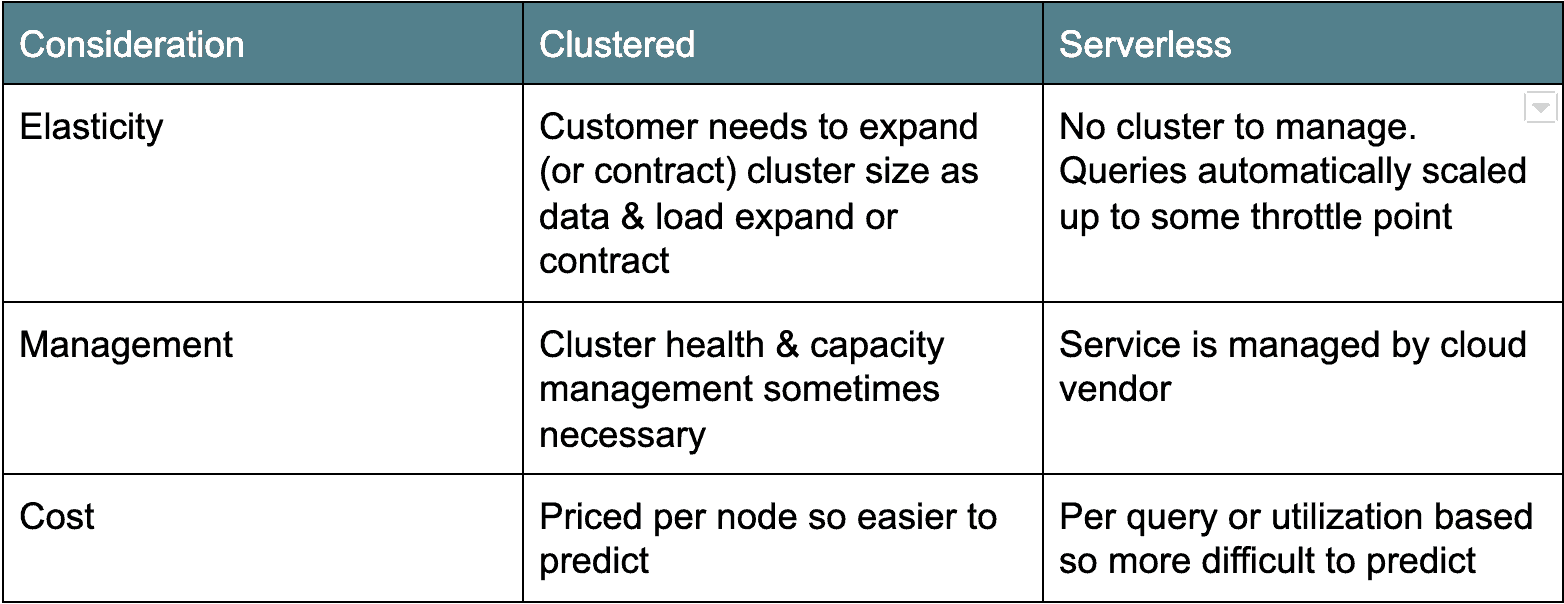
Cloud Architecture: Cluster versus Serverless
a cloud data warehouse architektúráknak két fő tábora van. Az első, régebbi telepítési architektúra fürtalapú: Az Amazon Redshift és az Azure SQL Data Warehouse ebbe a kategóriába tartozik. A fürtözött felhőalapú adattárházak általában csak fürtözött Postgres-származékok, amelyeket szolgáltatásként futtatnak a felhőben. A másik íz, a serverless, modernebb, és a Google BigQuery-t és a Snowflake-t példázza. Lényegében a kiszolgáló nélküli felhő adattárházak az adatbázis-fürtöt “láthatatlanná” teszik, vagy sok ügyfél között megosztják. Minden architektúrának megvannak az előnyei és hátrányai (lásd alább).
felhőalapú adatok árazása: Fizessen az ital vagy a szerver által
a telepítési architektúra mellett a felhő adattárház opciói között egy másik jelentős különbség az árképzés. Minden esetben névleges díjat fizet a tárolt adatok mennyiségéért. De az árképzés különbözik a számítástól.
a Google BigQuery és a Snowflake például igény szerinti árazási lehetőségeket kínál a beolvasott adatok mennyisége vagy a felhasznált számítási idő alapján. Az Amazon Redshift és az Azure SQL Data Warehouse a fürt csomópontjainak száma vagy típusa alapján kínál erőforrás-árazást. Mindkét típusú árképzési modellnek vannak előnyei és hátrányai. Az igény szerinti modellek csak azért számítanak fel díjat, amit használ, ami megnehezítheti a költségvetés tervezését, mivel nehéz megjósolni a felhasználók számát, valamint a futtatni kívánt lekérdezések számát és méretét. Ismerek egy ügyfél példát, ahol egy felhasználó tévesen futott egy 1000 dolláros + lekérdezést.
a csomópont alapú modellek (azaz az Amazon Redshift és az Azure SQL Data Warehouse) esetében a kiszolgáló és/vagy a kiszolgáló típusa szerint kell fizetni. Ez az árképzési modell nyilvánvalóan kiszámíthatóbb, de “mindig be van kapcsolva”, így a felhasználástól függetlenül lapos árat fizet.
az árképzés fontos szempont, és sok használati esetet és munkaterhelési modellezést igényel, hogy megtalálja a szervezetének megfelelőt.
kihívások és megfontolások a felhő-migrációval kapcsolatban (a “Gotchas”)
az AtScale-nél sok olyan vállalkozást láttunk, amely a helyszíni adattavakból és/vagy relációs adattárházakból a felhőbe történő migrációt kísérelte meg. Sokak számára migrációik az első kísérleti projekt után “elakadnak” a következő okok miatt:
- zavar: a továbbfelhasználóknak (üzleti elemzők, adatkutatók) meg kell változtatniuk szokásaikat, és újra kell készíteniük jelentéseiket és irányítópultjaikat.
- teljesítmény: a cloud DW nem felel meg a magasan hangolt, örökölt helyszíni adatplatformok teljesítményének.
- Sticker shock – váratlan vagy nem tervezett működési költségek és a költségellenőrzések hiánya.
ez az, ahol az AtScale segíthet
megtartani azt, amije van
az AtScale A3 minimalizálja vagy kiküszöböli a platformáttelepítések miatti üzleti zavarokat azáltal, hogy lehetővé teszi a vállalkozás számára, hogy továbbra is használja meglévő BI-eszközeit, irányítópultjait és jelentéseit anélkül, hogy újra kódolná vagy teljesen elhagyná őket. Hogy tehetjük ezt meg? Az atscale Universal Semantic Layer (egyetemes szemantikai réteg) egy absztrakciót biztosít, amely kihasználja a régi platformsémákat azáltal, hogy gyakorlatilag újra leképezi őket az új felhő adattárházba. Ez azt jelenti, hogy a meglévő jelentések és irányítópultok az új felhőalapú adatplatformon működnek, minimális vagy semmilyen újrakódolással.
töltse fel teljesítményét
látom, hogy sok vállalkozás kiábrándult az új felhőalapú adatplatform teljesítményéből. Amit gyakran nem vesznek figyelembe, az az, hogy meglévő helyszíni adattárházukat (azaz Teradata, Oracle) évek vagy akár évtizedek óta hangolják. Az azonos szintű teljesítmény elérése “a dobozból” egy felhő adattárházzal nem reális.
az atscale adaptív gyorsítótár a felhasználói lekérdezési minták alapján automatikusan aggregátumokat generál a felhőalapú adatplatformon. A költséges és időigényes táblázatvizsgálatok elkerülésével az AtScale platform gyors, következetes lekérdezéseket biztosít “gondolatsebességgel”. Sok ügyfélnek segítettünk túljutni teljesítménybeli kihívásaikon, és feloldani a felhőalapú migrációjuk blokkolását.
tartsa szemmel a költségeket
nem is tudom megszámolni, hányszor hallottam, hogy az emberek panaszkodnak, hogy a felhő költségeik sokkal magasabbak, mint amire számítottak, és kiszámíthatatlanok a rendszerindításhoz. Ismét ez az Atscale adaptív gyorsítótár a mentéshez. A felesleges táblázatvizsgálatok csökkentésével javíthatjuk az általános teljesítményt, a párhuzamosságot és a költségek kiszámíthatóságát, lehetővé téve, hogy többet hozhasson ki adatplatformjából a költségek növelése nélkül. Az AtScale géppel generált lekérdezéseivel kiszámíthatóvá tesszük költségeit, és kiküszöböljük a kézzel írt SQL lekérdezésekkel kapcsolatos kockázatokat.
őszintén hiszem, hogy a felhő adattárházak egy játékváltó és az adattárház következő hulláma. Átgondoltan használva a felhőalapú adattárházak drasztikusan csökkenthetik működési költségeit, miközben agilitást biztosítanak az üzleti igények kielégítésére.