Ein Cloud Data Warehouse ist eine Datenbank, die in einer öffentlichen Cloud als verwalteter Service bereitgestellt wird und für Analysen, Skalierung und Benutzerfreundlichkeit optimiert ist.
In den späten 80ern erinnere ich mich an meine erste Arbeit mit Oracle 6, einer „relationalen“ Datenbank, in der Daten in Tabellen formatiert wurden. Das Konzept eines Datendienstes, bei dem ich Daten laden und dann mit einer Standardsprache (SQL) abfragen konnte, war für mich ein Wendepunkt. In den 90er Jahren, als relationale Datenbanken mit der Größe und Komplexität analytischer Workloads zu kämpfen hatten, entstanden die MPP-Data Warehouses wie Teradata, Netezza und später Vertica und Greenplum. 2010 bei Yahoo!, mehr als 20 Jahre nach der Geburt der relationalen Datenbank hatte ich das Glück, mit einem Open-Source-Projekt namens Hadoop einen tiefgreifenden Wandel im Datenmanagement zu erleben. Das Konzept eines „Data Lake“, in dem ich unstrukturierte Rohdaten abfragen konnte, war ein großer Fortschritt in meiner Fähigkeit, mehr Daten mit mehr Agilität zu wesentlich geringeren Kosten zu erfassen, zu speichern und zu verarbeiten.
Mit dem Aufkommen von Cloud Data Warehouses erleben wir jetzt eine dritte Innovationswelle in der Data Warehousing-Technologie. Wenn Unternehmen in die Cloud wechseln, verlassen sie ihre alten On-Premise-Data-Warehousing-Technologien, einschließlich Hadoop, für diese neuen Cloud-Datenplattformen. Diese Transformation ist eine enorme tektonische Verschiebung im Datenmanagement und hat tiefgreifende Auswirkungen auf Unternehmen.
Die Vorteile eines Cloud Data Warehouses
Cloud-basierte Data Warehouses ermöglichen es Unternehmen, sich auf die Führung ihres Geschäfts zu konzentrieren, anstatt einen Raum voller Server zu betreiben, und sie ermöglichen es Business Intelligence-Teams, aufgrund des verbesserten Zugriffs, der Skalierbarkeit und der Leistung schnellere und bessere Einblicke zu liefern.
- Datenzugriff: Wenn Sie ihre Daten in die Cloud stellen, können Unternehmen ihren Analysten Zugriff auf Echtzeitdaten aus zahlreichen Quellen gewähren, sodass sie schnell bessere Analysen durchführen können.
- Skalierbarkeit: Es ist viel schneller und kostengünstiger, ein Cloud-Data-Warehouse zu skalieren als ein On-Premise-System, da keine neue Hardware gekauft werden muss (und möglicherweise eine Über- oder Unterbereitstellung erforderlich ist) und die Skalierung bei Bedarf automatisch erfolgen kann
- Leistung: Mit einem Cloud-Data-Warehouse können Abfragen viel schneller ausgeführt werden als mit einem herkömmlichen On-Premise-Data-Warehouse zu geringeren Kosten.
Cloud-Data-Warehouse-Funktionen
Jeder der großen Public-Cloud-Anbieter bietet seine eigene Variante eines Cloud-Data-Warehouse-Dienstes an: Google bietet BigQuery, Amazon Redshift und Microsoft Azure SQL Data Warehouse. Es gibt auch Cloud-Angebote wie Snowflake, die dieselben Funktionen über einen Dienst bereitstellen, der in der Public Cloud ausgeführt wird, jedoch unabhängig verwaltet wird. Für jeden dieser Dienste bietet der Cloud-Anbieter oder Data Warehouse-Anbieter die folgenden Funktionen „out of the box“:
- Datenspeicherung und -verwaltung: Die Daten werden in einem Cloud-basierten Dateisystem (d. H. S3) gespeichert.
- Automatische Upgrades: Es gibt kein Konzept einer „Version“ oder eines Software-Upgrades.
- Kapazitätsmanagement: Es ist einfach, Ihren Daten-Footprint zu erweitern (oder zu verkleinern).
Faktoren, die bei der Auswahl eines Cloud Data Warehouse zu berücksichtigen sind
Wie diese Cloud Data Warehouse-Anbieter diese Funktionen bereitstellen und wie sie diese berechnen, ist der Punkt, an dem die Dinge differenzierter werden. Lassen Sie uns tiefer in die verschiedenen Bereitstellungsimplementierungen und Preismodelle eintauchen.
Cloud-Architektur: Cluster versus Serverless
Es gibt zwei Haupttypen von Cloud-Data-Warehouse-Architekturen. Die erste, ältere Bereitstellungsarchitektur ist clusterbasiert: Amazon Redshift und Azure SQL Data Warehouse fallen in diese Kategorie. In der Regel handelt es sich bei Clustered Cloud Data Warehouses nur um clusterte Postgres-Derivate, die als Dienst in der Cloud ausgeführt werden können. Die andere Variante, Serverless, ist moderner und zählt Google BigQuery und Snowflake als Beispiele. Im Wesentlichen machen serverlose Cloud Data Warehouses den Datenbankcluster „unsichtbar“ oder werden von vielen Clients gemeinsam genutzt. Jede Architektur hat ihre Vor- und Nachteile (siehe unten).
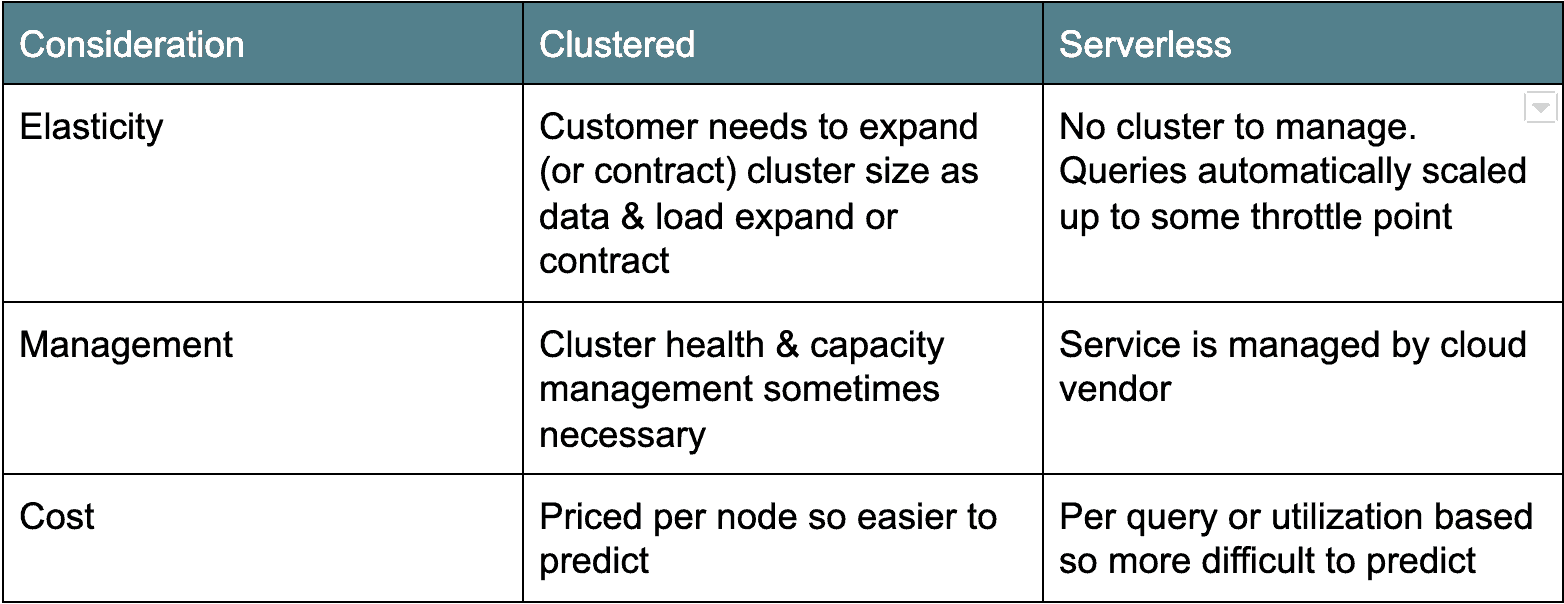
Preise für Cloud-Daten: Zahlen Sie nach Cloud oder Server
Neben der Bereitstellungsarchitektur besteht ein weiterer wesentlicher Unterschied zwischen den Cloud Data Warehouse-Optionen in der Preisgestaltung. In allen Fällen zahlen Sie eine geringe Gebühr für die Menge der gespeicherten Daten. Aber die Preise unterscheiden sich für Compute.
Google BigQuery und Snowflake bieten beispielsweise On-Demand-Preisoptionen an, die auf der Menge der gescannten Daten oder der verwendeten Rechenzeit basieren. Amazon Redshift und Azure SQL Data Warehouse bieten Ressourcenpreise basierend auf der Anzahl oder den Typen der Knoten im Cluster. Beide Arten von Preismodellen haben Vor- und Nachteile. Die On-Demand-Modelle berechnen Ihnen nur das, was Sie verwenden, was die Budgetierung erschweren kann, da es schwierig ist, die Anzahl der Benutzer sowie die Anzahl und Größe der von ihnen ausgeführten Abfragen vorherzusagen. Ich kenne ein Kundenbeispiel, in dem ein Benutzer fälschlicherweise eine Abfrage über 1.000 USD ausgeführt hat.
Für die knotenbasierten Modelle (z. B. Amazon Redshift und Azure SQL Data Warehouse) zahlen Sie nach Server und / oder Servertyp. Dieses Preismodell ist offensichtlich vorhersehbarer, aber es ist „always on“, sodass Sie unabhängig von der Nutzung einen Pauschalpreis zahlen.
Die Preisgestaltung ist ein wichtiger Aspekt und erfordert viel Anwendungsfall- und Workload-Modellierung, um die richtige Lösung für Ihr Unternehmen zu finden.
Herausforderungen und Überlegungen zur Cloud-Migration (die „Fallstricke“)
Bei AtScale haben viele Unternehmen versucht, von ihren lokalen Data Lakes und / oder relationalen Data Warehouses in die Cloud zu migrieren. Für viele „stocken“ ihre Migrationen nach dem ersten Pilotprojekt aus folgenden Gründen:
- Störung: nachgeschaltete Anwender (Business Analysten, Data Scientists) müssen ihre Gewohnheiten ändern und ihre Berichte und Dashboards überarbeiten.
- Leistung: Die Cloud-DW entspricht nicht der Leistung von hochgradig abgestimmten, älteren On-Premise-Datenplattformen.
- Sticker Shock – unerwartete oder ungeplante Betriebskosten und fehlende Kostenkontrolle.
Hier kann AtScale helfen
Behalten, was Sie haben
AtScale A3 minimiert oder beseitigt Geschäftsunterbrechungen aufgrund von Plattformmigrationen, indem es dem Unternehmen ermöglicht, seine vorhandenen BI-Tools, Dashboards und Berichte weiterhin zu verwenden, ohne sie neu zu codieren oder ganz aufzugeben. Wie können wir das machen? Die AtScale Universal Semantic Layer ™ bietet eine Abstraktion, die Ihre Legacy-Plattformschemata nutzt, indem Sie sie virtuell Ihrem neuen Cloud Data Warehouse zuordnet. Dies bedeutet, dass Ihre vorhandenen Berichte und Dashboards auf der neuen Cloud-Datenplattform mit minimaler oder keiner Neucodierung funktionieren.
Steigern Sie Ihre Leistung
Ich sehe, dass viele Unternehmen von der Leistung ihrer neuen Cloud-Datenplattform desillusioniert sind. Was sie oft nicht berücksichtigen, ist, dass ihr vorhandenes On-Premise-Data-Warehouse (z. B. Teradata, Oracle) seit Jahren oder sogar Jahrzehnten optimiert wurde. Das gleiche Leistungsniveau „out of the box“ mit einem Cloud Data Warehouse zu erreichen, ist nicht realistisch.
Der AtScale Adaptive Cache™ generiert automatisch Aggregate auf Ihrer Cloud-Datenplattform basierend auf Benutzerabfragemustern. Durch die Vermeidung kostspieliger und zeitaufwändiger Tabellenscans liefert die AtScale-Plattform schnelle, konsistente Abfragen in „Gedankengeschwindigkeit“. Wir haben vielen Kunden geholfen, ihre Performance-Herausforderungen zu überwinden und ihre Cloud-Migrationen freizugeben.
Kosten im Auge behalten
Ich kann nicht einmal zählen, wie oft ich gehört habe, dass sich IT-Leute darüber beschweren, dass ihre Cloud-Kosten viel höher sind als erwartet und unvorhersehbar. Auch hier kommt der AtScale Adaptive Cache™ zur Rettung. Durch die Reduzierung unnötiger Tabellenscans können wir die Gesamtleistung, Parallelität und Kostenvorhersagbarkeit verbessern, sodass Sie mehr aus Ihrer Datenplattform herausholen können, ohne die Kosten zu erhöhen. Mit den maschinell generierten Abfragen von AtScale machen wir Ihre Kosten vorhersehbar und eliminieren das Risiko, das mit handgeschriebenen SQL-Abfragen verbunden ist.
Ich glaube aufrichtig, dass Cloud Data Warehouses ein Game Changer und die nächste Welle im Data Warehousing sind. Mit Bedacht eingesetzt, können Cloud Data Warehouses Ihre Betriebskosten drastisch senken und Ihnen gleichzeitig die Flexibilität geben, mit den Anforderungen des Unternehmens Schritt zu halten.