Un almacén de datos en la nube es una base de datos que se entrega en una nube pública como un servicio administrado optimizado para análisis, escalabilidad y facilidad de uso.
A finales de los 80, recuerdo mi primera vez trabajando con Oracle 6, una base de datos «relacional» donde los datos se formateaban en tablas. El concepto de un servicio de datos donde podía cargar datos y luego consultarlos con un lenguaje estándar (SQL) fue un cambio de juego para mí. En los años 90, cuando las bases de datos relacionales comenzaron a tener problemas con el tamaño y la complejidad de las cargas de trabajo analíticas, vimos la aparición de almacenes de datos MPP como Teradata, Netezza y más tarde, Vertica y Greenplum. En 2010 en Yahoo!, más de 20 años después del nacimiento de la base de datos relacional, tuve la suerte de presenciar un cambio radical en la gestión de datos con un proyecto de código abierto llamado Hadoop. El concepto de un» lago de datos » en el que podía consultar datos no estructurados sin procesar fue un gran avance en mi capacidad para capturar, almacenar y procesar más datos con más agilidad a un costo sustancialmente menor.
Ahora somos testigos de una tercera ola de innovación en tecnología de almacenamiento de datos con la llegada de los almacenes de datos en la nube. A medida que las empresas se trasladan a la nube, están abandonando sus tecnologías de almacenamiento de datos locales heredadas, incluida Hadoop, por estas nuevas plataformas de datos en la nube. Esta transformación supone un enorme cambio tectónico en la gestión de datos y tiene profundas implicaciones para las empresas.
Los beneficios de un almacén de datos en la nube
Los almacenes de datos basados en la nube liberan a las empresas para centrarse en la gestión de su negocio, en lugar de ejecutar una sala llena de servidores, y permiten a los equipos de inteligencia empresarial ofrecer información más rápida y mejor gracias a un acceso, escalabilidad y rendimiento mejorados.
- Acceso a datos: Colocar sus datos en la nube permite a las empresas dar a sus analistas acceso a datos en tiempo real de numerosas fuentes, lo que les permite ejecutar mejores análisis rápidamente.
- Escalabilidad: Escalar un almacén de datos en la nube es mucho más rápido y menos costoso que un sistema local porque no requiere la compra de hardware nuevo (y posiblemente un aprovisionamiento excesivo o insuficiente) y el escalado puede ocurrir automáticamente según sea necesario
- Rendimiento: Un almacén de datos en la nube permite que las consultas se ejecuten mucho más rápidamente que en un almacén de datos local tradicional, por un costo más bajo.
Capacidades de almacén de datos en la nube
Cada uno de los principales proveedores de nube pública ofrece su propio tipo de servicio de almacén de datos en la nube: Google ofrece BigQuery, Amazon tiene Redshift y Microsoft tiene Azure SQL Data Warehouse. También hay ofertas en la nube como Snowflake que proporcionan las mismas capacidades a través de un servicio que se ejecuta en la nube pública pero se administra de forma independiente. Para cada uno de estos servicios, el proveedor en la nube o el proveedor de almacén de datos ofrece las siguientes capacidades «listas para usar»:
- Almacenamiento y gestión de datos: los datos se almacenan en un sistema de archivos basado en la nube (es decir, S3).
- Actualizaciones automáticas :no hay concepto de» versión » o actualización de software.
- Gestión de la capacidad: es fácil ampliar (o contratar) su huella de datos.
Factores a tener en cuenta Al elegir un almacén de datos en la nube
Cómo estos proveedores de almacén de datos en la nube ofrecen estas capacidades y cómo cobran por ellas es donde las cosas se vuelven más matizadas. Profundicemos en las diferentes implementaciones de implementación y modelos de precios.
Arquitectura en la nube: Clúster versus sin servidor
Hay dos campos principales de arquitecturas de almacenamiento de datos en la nube. La primera arquitectura de implementación antigua está basada en clústeres: Amazon Redshift y Azure SQL Data Warehouse entran en esta categoría. Por lo general, los almacenes de datos en nube en clúster son en realidad derivados de Postgres en clúster, portados para ejecutarse como un servicio en la nube. El otro sabor, sin servidor, es más moderno y cuenta con Google BigQuery y Snowflake como ejemplos. Esencialmente, los almacenes de datos en la nube sin servidor hacen que el clúster de bases de datos sea «invisible» o compartido entre muchos clientes. Cada arquitectura tiene sus pros y sus contras (ver más abajo).
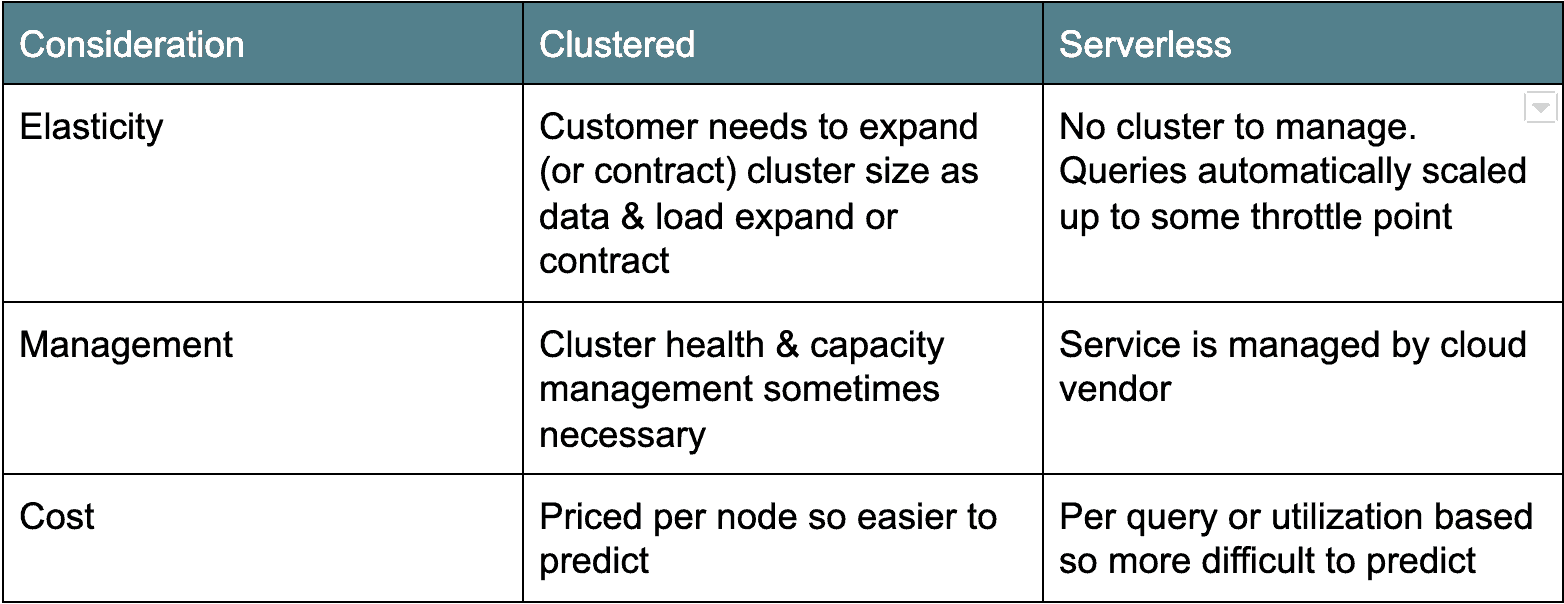
Precios de datos en la nube: Pagar por la bebida o por el servidor
Además de la arquitectura de implementación, otra diferencia importante entre las opciones de almacenamiento de datos en la nube es el precio. En todos los casos, usted paga una tarifa nominal por la cantidad de datos almacenados. Pero el precio difiere para el cálculo.
Por ejemplo, Google BigQuery y Snowflake ofrecen opciones de precios bajo demanda basadas en la cantidad de datos escaneados o el tiempo de cómputo utilizado. Amazon Redshift y Azure SQL Data Warehouse ofrecen precios de recursos basados en el número o los tipos de nodos del clúster. Hay pros y contras en ambos tipos de modelos de precios. La demanda sólo en los modelos de carga para lo que uso que puede hacer difícil la presupuestación como es difícil predecir el número de usuarios y el número y tamaño de las consultas que se ejecutan. Conozco un ejemplo de cliente en el que un usuario realizó por error una consulta de más de 1 1,000.
Para los modelos basados en nodos (es decir, Amazon Redshift y Azure SQL Data Warehouse), paga por tipo de servidor o servidor. Este modelo de precios es obviamente más predecible, pero está «siempre encendido», por lo que está pagando un precio fijo independientemente del uso.
Los precios son una consideración importante y requieren una gran cantidad de casos de uso y modelos de carga de trabajo para encontrar el ajuste adecuado para su organización.
Desafíos y consideraciones para la migración a la nube (las «Trampas»)
En AtScale, hemos visto a muchas empresas intentar una migración desde sus lagos de datos locales o almacenes de datos relacionales a la nube. Para muchos, sus migraciones se «estancan» después del primer proyecto piloto debido a las siguientes razones:
- Disrupción: los usuarios intermedios (analistas de negocios, científicos de datos) tienen que cambiar sus hábitos y reequipar sus informes y paneles de control.Rendimiento
- : el DW en la nube no coincide con el rendimiento de las plataformas de datos locales heredadas altamente ajustadas.
- Choque de pegatina: costos operativos imprevistos o no planificados y falta de controles de costos.
Aquí es donde AtScale puede ayudar a
A mantener lo que tiene
AtScale A3 minimiza o elimina la interrupción del negocio debido a las migraciones de plataformas al permitir que la empresa continúe utilizando sus herramientas de BI, paneles e informes existentes sin volver a codificarlos o abandonarlos por completo. ¿Cómo podemos hacer esto? AtScale Universal Semantic Layer™ proporciona una abstracción que aprovecha sus esquemas de plataforma heredados al reasignarlos virtualmente a su nuevo almacén de datos en la nube. Esto significa que sus informes y paneles existentes funcionarán en la nueva plataforma de datos en la nube con una reprogramación mínima o nula.
Potencie su rendimiento
Veo que muchas empresas se desilusionan con el rendimiento de su nueva plataforma de datos en la nube. Lo que a menudo no tienen en cuenta es que su almacén de datos local existente (es decir, Teradata, Oracle) se ha ajustado durante años o incluso décadas. Obtener el mismo nivel de rendimiento «listo para usar» con un almacén de datos en la nube no es realista.
AtScale Adaptive Cache™ funciona generando agregados automáticamente en su plataforma de datos en la nube en función de los patrones de consulta de los usuarios. Al evitar análisis de tablas costosos y que consumen mucho tiempo, la plataforma AtScale ofrece consultas rápidas y consistentes a «velocidad de pensamiento». Hemos ayudado a muchos clientes a superar sus desafíos de rendimiento y desbloquear sus migraciones a la nube.
Mantenga un control de los costos
Ni siquiera puedo contar el número de veces que lo he escuchado, la gente se queja de que sus costos en la nube son mucho más altos de lo que esperaban e impredecibles para arrancar. Una vez más, el AtScale Adaptive Cache™ al rescate. Al reducir los escaneos innecesarios de tablas, podemos mejorar el rendimiento general, la concurrencia y la previsibilidad de costos, lo que le permite aprovechar al máximo su plataforma de datos sin aumentar el costo. Con las consultas generadas por máquina de AtScale, haremos que sus costos sean predecibles y eliminaremos el riesgo asociado con las consultas SQL escritas a mano.
Creo sinceramente que los almacenes de datos en la nube son un cambio de juego y la próxima ola en el almacenamiento de datos. Si se utilizan cuidadosamente, los almacenes de datos en la nube pueden reducir drásticamente sus costos operativos y, al mismo tiempo, brindarle la agilidad para mantenerse al día con las demandas de la empresa.