et cloud-datalager er en database, der leveres i en offentlig sky som en administreret tjeneste, der er optimeret til analyse, skala og brugervenlighed.
i slutningen af 80 ‘ erne husker jeg min første gang, jeg arbejdede med Oracle 6, en “relationel” database, hvor data blev formateret i tabeller. Konceptet med en datatjeneste, hvor jeg kunne indlæse data og derefter forespørge det med et standardsprog, var en spilskifter for mig. I 90 ‘ erne, da relationsdatabaser begyndte at kæmpe med størrelsen og kompleksiteten af analytiske arbejdsbyrder, så vi fremkomsten af MPP-datalagre som Teradata, Vertica og senere, Vertica og Greenplum. I 2010 på Yahoo!, mere end 20 år efter fødslen af relationsdatabasen, var jeg heldig nok til at være vidne til en havændring i datastyring med et open source-projekt kaldet Hadoop. Konceptet med en” datasø”, hvor jeg kunne forespørge rå ustrukturerede data, var et stort spring fremad i min evne til at fange, gemme og behandle flere data med mere smidighed til en væsentligt lavere pris.
vi er nu vidne til en tredje bølge af innovation inden for datalagringsteknologi med fremkomsten af cloud-datalagre. Når virksomheder flytter til skyen, opgiver de deres arv on-premise datalagringsteknologier, herunder Hadoop, til disse nye cloud-dataplatforme. Denne transformation er et enormt tektonisk skift i datastyring og har dybe konsekvenser for virksomheder.
fordelene ved et Cloud-datalager
Cloud-baserede datalagre frigør virksomheder til at fokusere på at drive deres forretning i stedet for at køre et rum fyldt med servere, og de giver business intelligence-teams mulighed for at levere hurtigere og bedre indsigt på grund af forbedret adgang, skalerbarhed og ydeevne.
- dataadgang: at sætte deres data i skyen gør det muligt for virksomheder at give deres analytikere adgang til realtidsdata fra adskillige kilder, så de hurtigt kan køre bedre analyser.
- skalerbarhed: Det er meget hurtigere og billigere at skalere et cloud-datalager end et on – premise-system, fordi det ikke kræver køb af nyt udstyr (og muligvis over-eller underlevering), og skaleringen kan ske automatisk efter behov
- ydeevne: et cloud-datalager giver mulighed for, at forespørgsler køres meget hurtigere, end de er mod et traditionelt lokalt datalager, til lavere omkostninger.
Cloud Data lager kapaciteter
hver af de store offentlige cloud leverandører tilbyder deres egen smag af en cloud data lager service: Google tilbyder Storforespørgsel, Microsoft har Redshift og Microsoft har et datavarehus. Der er også cloud tilbud fra folk som snefnug, der giver de samme muligheder via en tjeneste, der kører på den offentlige sky, men styres uafhængigt. For hver af disse tjenester leverer cloud-leverandøren eller datalagerudbyderen følgende funktioner “ud af kassen”:
- datalagring og administration: data gemmes i et skybaseret filsystem (dvs.S3).
- automatiske opgraderinger: der er ikke noget begreb om en “version” eller programopgradering.
- kapacitetsstyring: det er nemt at udvide (eller kontrakt) dit datafodaftryk.
faktorer, der skal overvejes, når du vælger et Cloud-datalager
hvordan disse cloud-datalagerleverandører leverer disse muligheder, og hvordan de opkræver for dem, er, hvor tingene bliver mere nuancerede. Lad os dykke dybere ned i de forskellige implementeringsimplementeringer og prismodeller.
Cloud Architecture: Cluster versus Serverless
der er to hovedlejre af cloud data lagerarkitekturer. Den første, Ældre implementeringsarkitektur er klyngebaseret: Denne kategori omfatter bl.a. datavarehus. Typisk er clustered cloud data pakhuse egentlig bare clustered Postgres derivater, porteret til at køre som en tjeneste i skyen. Den anden smag, serverløs, er mere moderne og tæller Google Bigforespørgsel og snefnug som eksempler. I det væsentlige gør serverløse cloud-datalagre databaseklyngen “usynlig” eller delt på tværs af mange klienter. Hver arkitektur har deres fordele og ulemper (se nedenfor).
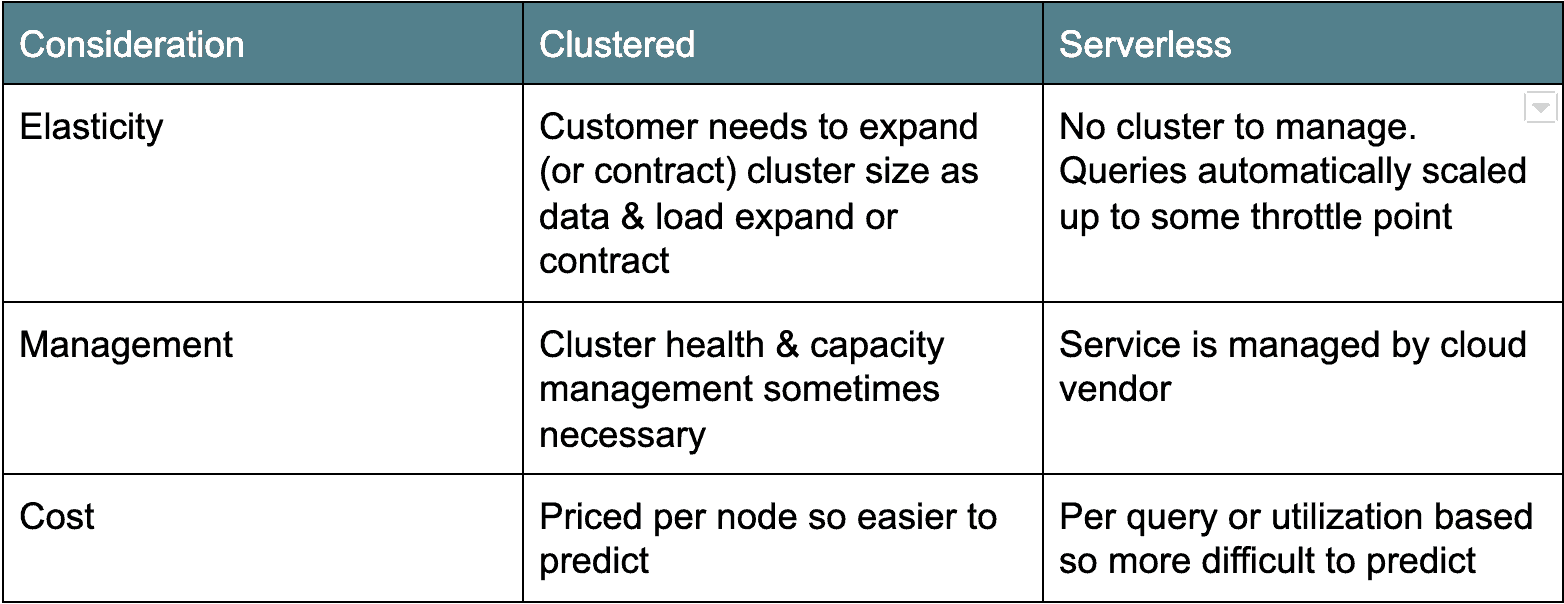
Cloud Data prissætning: Betal med drikken eller af serveren
udover implementeringsarkitektur er en anden stor forskel mellem cloud-datalagerindstillingerne prisfastsættelse. I alle tilfælde betaler du et nominelt gebyr for mængden af lagrede data. Men prisfastsættelsen er forskellig for beregning.
for eksempel tilbyder Google Bigforespørgsel og snefnug on-demand prisindstillinger baseret på mængden af scannet data eller beregnet tid brugt. Datavarehus tilbyder ressourcepriser baseret på antallet eller typerne af noder i klyngen. Der er fordele og ulemper ved begge typer prismodeller. On-demand-modellerne opkræver kun dig for det, du bruger, hvilket kan gøre budgettering vanskelig, da det er svært at forudsige antallet af brugere og antallet og størrelsen på de forespørgsler, de kører. Jeg kender et kundeeksempel, hvor en bruger fejlagtigt kørte en $1.000+ forespørgsel.
for de node baserede modeller (dvs. Denne prismodel er naturligvis mere forudsigelig, men den er “altid tændt”, så du betaler en fast pris uanset brug.
prissætning er en vigtig overvejelse og kræver en stor brugssag og arbejdsbyrdemodellering for at finde den rigtige pasform til din organisation.
udfordringer og overvejelser for Cloud Migration (“Gotchas”)
på AtScale har vi set mange virksomheder forsøge at migrere fra deres on-premise datasøer og/eller relationelle datalagre til skyen. For mange er deres migrationer “stall” efter det første pilotprojekt på grund af følgende grunde:
- Disruption: efterfølgende brugere (forretningsanalytikere, dataforskere) er nødt til at ændre deres vaner og omredigere deres rapporter og dashboards.
- ydeevne: cloud DV matcher ikke ydeevnen for højt afstemte, ældre on-premise dataplatforme.
- Sticker shock – uventede eller uplanlagte driftsomkostninger og manglende omkostningskontrol.
det er her AtScale kan hjælpe
med at beholde det, du har
AtScale A3 minimerer eller eliminerer forretningsforstyrrelser på grund af platformmigrationer ved at lade virksomheden fortsætte med at bruge deres eksisterende BI-værktøjer, dashboards og rapporter uden at omkode eller opgive dem helt. Hvordan kan vi gøre det? Atscale Universal Semantic Layer karrus giver en abstraktion, der udnytter dine ældre platformskemaer ved praktisk talt at kortlægge dem til dit nye cloud-datalager. Dette betyder, at dine eksisterende rapporter og dashboards fungerer på den nye cloud-dataplatform med minimal eller ingen omkodning.
Supercharge your Performance
jeg ser mange virksomheder blive desillusionerede med udførelsen af deres nye cloud data platform. Hvad de ofte undlader at overveje, er, at deres eksisterende on-premise datalager (dvs.Teradata, Oracle) er blevet indstillet i år eller endda årtier. At få det samme niveau af ydeevne “ud af kassen” med et cloud-datalager er ikke realistisk.
den Atscale Adaptive Cache, som er baseret på brugernes forespørgselsmønstre, fungerer ved automatisk at generere aggregater på din cloud-dataplatform. Ved at undgå dyre og tidskrævende bordscanninger leverer atscale-platformen hurtige, ensartede forespørgsler med “tankehastighed”. Vi har hjulpet mange kunder med at komme forbi deres præstationsudfordringer og fjerne blokeringen af deres cloud-migrationer.
hold et låg på omkostninger
jeg kan ikke engang tælle antallet af gange, jeg har hørt det folk klager over, at deres skyomkostninger er meget højere end de forventede og uforudsigelige at starte. En gang til, det Atscale Adaptive Cache til undsætning. Ved at reducere unødvendige tabelscanninger kan vi forbedre den samlede ydeevne, samtidighed og forudsigelighed af omkostninger, så du kan få mere ud af din dataplatform uden at øge omkostningerne. Med Atscales maskingenererede forespørgsler vil vi gøre dine omkostninger forudsigelige og eliminere risikoen forbundet med håndskrevne forespørgsler.
jeg tror oprigtigt, at cloud data lagre er en game changer og den næste bølge i datalagring. Brugt omtanke, cloud data lagre kan dramatisk sænke dine driftsomkostninger og samtidig give dig smidighed til at holde trit med de krav, som virksomheden.