un depozit de date cloud este o bază de date livrată într-un cloud public ca un serviciu gestionat, optimizat pentru analiză, scară și ușurință în utilizare.
la sfârșitul anilor ‘ 80, îmi amintesc prima dată când am lucrat cu Oracle 6, o bază de date „relațională” în care datele au fost formatate în tabele. Conceptul unui serviciu de date în care aș putea încărca date și apoi să le interoghez cu un limbaj standard (SQL) a fost un schimbător de jocuri pentru mine. În anii 90, când bazele de date relaționale au început să se lupte cu dimensiunea și complexitatea sarcinilor analitice, am văzut apariția depozitelor de date MPP precum Teradata, Netezza și later, Vertica și Greenplum. În 2010 la Yahoo!, la mai bine de 20 de ani de la nașterea bazei de date relaționale, am avut norocul să asist la o schimbare mare în gestionarea datelor cu un proiect open source numit Hadoop. Conceptul de „lac de date” în care aș putea interoga date brute nestructurate a fost un salt uriaș înainte în capacitatea mea de a capta, stoca și procesa mai multe date cu mai multă agilitate la un cost substanțial mai mic.
asistăm acum la un al treilea val de inovație în tehnologia de depozitare a datelor odată cu apariția depozitelor de date cloud. Pe măsură ce întreprinderile se mută în cloud, își abandonează tehnologiile moștenite de depozitare a datelor, inclusiv Hadoop, pentru aceste noi platforme de date cloud. Această transformare este o schimbare tectonică uriașă în gestionarea datelor și are implicații profunde pentru întreprinderi.
beneficiile unui depozit de date în Cloud
depozitele de date bazate pe Cloud eliberează companiile să se concentreze pe gestionarea afacerii lor, mai degrabă decât să ruleze o cameră plină de servere și permit echipelor de informații de afaceri să ofere informații mai rapide și mai bune datorită accesului îmbunătățit, scalabilității și performanței.
- accesul la date: punerea datelor lor în cloud permite companiilor să ofere analiștilor lor acces la date în timp real din numeroase surse, permițându-le să ruleze rapid analize mai bune.
- scalabilitate: Este mult mai rapid și mai puțin costisitor să scalezi un depozit de date cloud decât un sistem on-premise, deoarece nu necesită achiziționarea de hardware nou (și, eventual, supra – sau sub-aprovizionare), iar scalarea se poate întâmpla automat după cum este necesar
- performanță: un depozit de date cloud permite ca interogările să fie rulate mult mai repede decât sunt împotriva unui depozit de date local tradițional, pentru costuri mai mici.
capabilități Cloud Data Warehouse
fiecare dintre principalii furnizori de cloud publice oferă propria lor aroma de un serviciu cloud data warehouse: Google oferă BigQuery, Amazon are Redshift și Microsoft are Azure SQL Data Warehouse. Există, de asemenea, oferte de cloud de la Snowflake care oferă aceleași capabilități prin intermediul unui serviciu care rulează pe cloud public, dar este gestionat independent. Pentru fiecare dintre aceste servicii, furnizorul de cloud sau furnizorul de depozit de date oferă următoarele capabilități „out of the box”:
- stocarea și gestionarea datelor: datele sunt stocate într-un sistem de fișiere bazat pe cloud (adică S3).
- upgrade-uri automate: nu există conceptul de” versiune ” sau upgrade de software.
- gestionarea capacității: este ușor să vă extindeți (sau să contractați) amprenta de date.
factori de luat în considerare atunci când alegeți un depozit de date Cloud
modul în care acești furnizori de depozite de date cloud furnizează aceste capacități și modul în care percep taxe pentru ele este locul în care lucrurile devin mai nuanțate. Să ne scufundăm mai adânc în diferitele implementări de implementare și modele de stabilire a prețurilor.
cloud Architecture: Cluster versus Serverless
există două tabere principale de arhitecturi cloud data warehouse. Prima arhitectură de implementare mai veche este bazată pe cluster: Amazon Redshift și Azure SQL Data Warehouse se încadrează în această categorie. De obicei, depozitele de date cloud grupate sunt într-adevăr doar derivate Postgres grupate, portate pentru a rula ca serviciu în cloud. Cealaltă aromă, fără server, este mai modernă și numără Google BigQuery și Snowflake ca exemple. În esență, depozitele de date cloud fără server fac clusterul de baze de date „invizibil” sau partajat între mulți clienți. Fiecare arhitectură are argumente pro și contra (vezi mai jos).
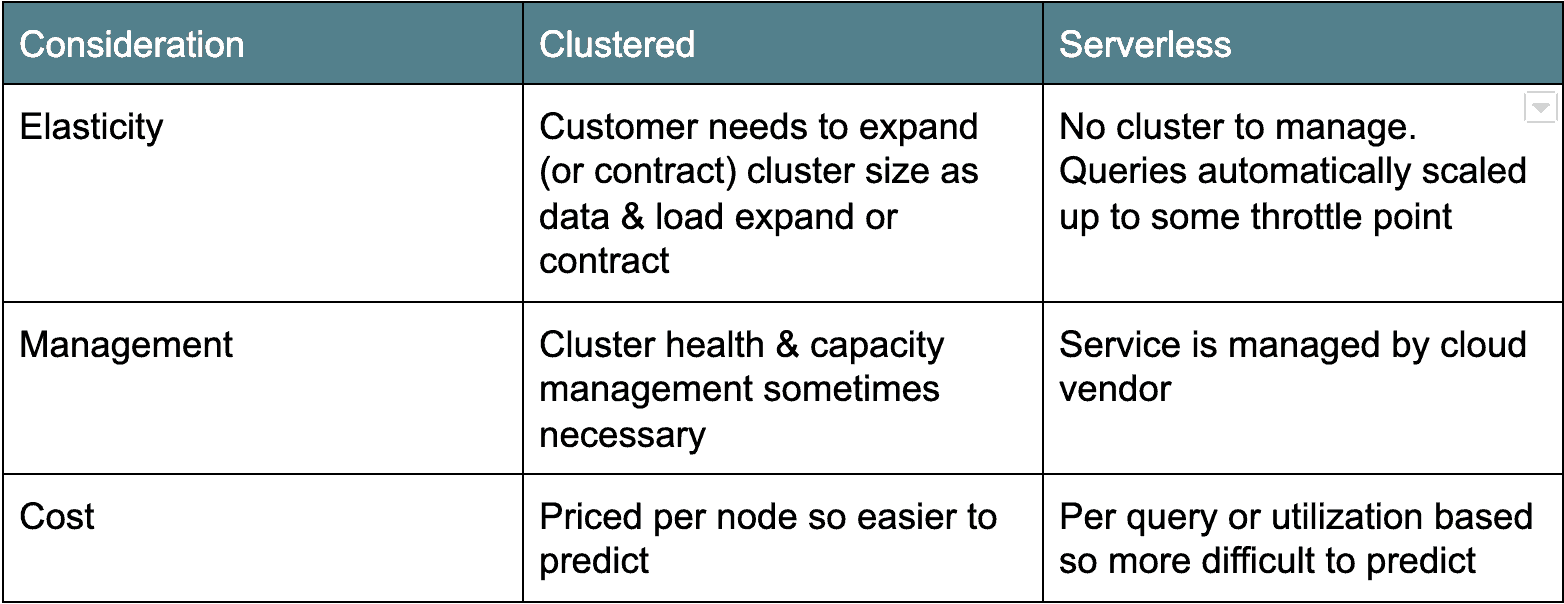
tarifarea datelor Cloud: Plătiți cu băutura sau cu serverul
pe lângă arhitectura de implementare, o altă diferență majoră între opțiunile depozitului de date cloud este prețul. În toate cazurile, plătiți o taxă nominală pentru cantitatea de date stocate. Dar prețurile diferă pentru calcul.
de exemplu, Google BigQuery și Snowflake oferă opțiuni de stabilire a prețurilor la cerere pe baza cantității de date scanate sau a timpului de calcul utilizat. Amazon Redshift și Azure SQL Data Warehouse oferă prețuri de resurse pe baza numărului sau tipurilor de noduri din cluster. Există argumente pro și contra pentru ambele tipuri de modele de prețuri. Modelele la cerere vă taxează doar pentru ceea ce utilizați, ceea ce poate face dificilă bugetarea, deoarece este greu de prezis numărul de utilizatori și numărul și dimensiunea interogărilor pe care le vor rula. Știu un exemplu de client în care un utilizator a rulat din greșeală o interogare de peste 1.000 USD.
pentru modelele bazate pe noduri (adică Amazon Redshift și Azure SQL Data Warehouse), plătiți după tipul de server și/sau server. Acest model de stabilire a prețurilor este, evident, mai previzibil, dar este „întotdeauna pornit”, astfel încât să plătiți un preț fix, indiferent de utilizare.
tarifarea este o considerație majoră și necesită o mare parte din modelarea cazurilor de utilizare și a volumului de muncă pentru a găsi potrivirea potrivită pentru organizația dvs.
provocări și considerații pentru migrarea în Cloud („Gotchas”)
la AtScale, am văzut o mulțime de întreprinderi care încearcă o migrare de la lacurile de date on-premise și/sau depozitele de date relaționale către cloud. Pentru mulți, migrațiile lor „se opresc” după primul proiect pilot din următoarele motive:
- întrerupere: utilizatorii din aval (analiști de afaceri, oameni de știință de date) trebuie să-și schimbe obiceiurile și să-și re-instrumenteze rapoartele și tablourile de bord.
- performanță: cloud DW nu se potrivește cu performanța platformelor de date on-premise foarte bine reglate.
- șoc autocolant – costuri de operare neprevăzute sau neplanificate și lipsa controalelor costurilor.
acesta este locul în care AtScale poate ajuta
să păstreze ceea ce aveți
AtScale A3 minimizează sau elimină perturbările afacerii din cauza migrațiilor platformei, permițând afacerii să continue să utilizeze instrumentele BI existente, tablourile de bord și rapoartele fără a le codifica sau abandona cu totul. Cum putem face asta? Atscale Universal Semantic layer XV oferă o abstracție care utilizează schemele de platformă moștenite prin re-maparea lor în noul dvs. depozit de date cloud. Aceasta înseamnă că rapoartele și tablourile de bord existente vor funcționa pe noua platformă de date cloud cu o re-codificare minimă sau deloc.
supraîncărcați performanța
văd că multe întreprinderi devin deziluzionate de performanța noii lor platforme de date cloud. Ceea ce adesea nu reușesc să ia în considerare este că depozitul lor de date existent la fața locului (adică Teradata, Oracle) au fost reglate de ani sau chiar decenii. Obținerea aceluiași nivel de performanță „din cutie” cu un depozit de date cloud nu este realistă.
cache-ul adaptiv atscale funcționează prin generarea automată a agregatelor pe platforma dvs. de date cloud pe baza modelelor de interogare a utilizatorilor. Prin evitarea scanărilor costisitoare și consumatoare de timp, platforma AtScale oferă interogări rapide și consecvente la „viteza gândirii”. Am ajutat mulți clienți să treacă peste provocările lor de performanță și să-și deblocheze migrațiile în cloud.
păstrați un capac asupra costurilor
nici măcar nu pot număra de câte ori am auzit că oamenii se plâng că costurile lor cloud sunt mult mai mari decât au anticipat și imprevizibile pentru a porni. Din nou, este cache-ul adaptiv atscale la salvare. Prin reducerea scanărilor inutile ale tabelelor, putem îmbunătăți performanța generală, concurența și predictibilitatea costurilor, permițându-vă să obțineți mai mult din platforma dvs. de date fără a crește costul. Cu interogările generate de mașină atscale, vom face costurile previzibile și vom elimina riscul asociat interogărilor SQL scrise manual.
cred sincer că depozitele de date cloud sunt un schimbător de jocuri și următorul val în depozitarea datelor. Utilizate cu grijă, depozitele de date din cloud vă pot reduce dramatic costurile de operare, oferindu-vă în același timp agilitatea de a ține pasul cu cerințele afacerii.