Un data warehouse cloud è un database fornito in un cloud pubblico come servizio gestito ottimizzato per analisi, scalabilità e facilità d’uso.
Alla fine degli anni ‘ 80, ricordo la mia prima volta a lavorare con Oracle 6, un database “relazionale” in cui i dati venivano formattati in tabelle. Il concetto di un servizio dati in cui potevo caricare i dati e quindi interrogarli con un linguaggio standard (SQL) è stato un punto di svolta per me. Negli anni ‘ 90, quando i database relazionali hanno iniziato a lottare con le dimensioni e la complessità dei carichi di lavoro analitici, abbiamo visto l’emergere dei data warehouse MPP come Teradata, Netezza e più tardi, Vertica e Greenplum. Nel 2010 a Yahoo!, più di 20 anni dopo la nascita del database relazionale, ho avuto la fortuna di assistere a un cambiamento epocale nella gestione dei dati con un progetto open source chiamato Hadoop. Il concetto di un” lago di dati ” in cui potrei interrogare dati grezzi non strutturati è stato un enorme salto in avanti nella mia capacità di acquisire, archiviare ed elaborare più dati con maggiore agilità a un costo sostanzialmente inferiore.
Stiamo assistendo a una terza ondata di innovazione nella tecnologia di data warehousing con l’avvento dei data warehouse cloud. Mentre le aziende passano al cloud, stanno abbandonando le loro legacy tecnologie di data warehousing on-premise, tra cui Hadoop, per queste nuove piattaforme di dati cloud. Questa trasformazione è un enorme cambiamento tettonico nella gestione dei dati e ha profonde implicazioni per le imprese.
I vantaggi di un Data Warehouse cloud
I data warehouse basati su cloud consentono alle aziende di concentrarsi sulla gestione della propria attività piuttosto che su una sala piena di server e consentono ai team di business intelligence di fornire informazioni più rapide e migliori grazie a accesso, scalabilità e prestazioni migliorate.
- Accesso ai dati: mettere i propri dati nel cloud consente alle aziende di dare ai propri analisti l’accesso a dati in tempo reale da numerose fonti, consentendo loro di eseguire analisi migliori rapidamente.
- Scalabilità: È molto più veloce e meno costoso scalare un data warehouse cloud rispetto a un sistema on-premise perché non richiede l’acquisto di nuovo hardware (e possibilmente over – o under-provisioning) e il ridimensionamento può avvenire automaticamente in base alle esigenze
- Prestazioni: un data warehouse cloud consente di eseguire query molto più rapidamente rispetto a un data warehouse tradizionale on-premise, per un costo inferiore.
Funzionalità di Cloud Data Warehouse
Ciascuno dei principali fornitori di cloud pubblici offre il proprio sapore di un servizio di cloud data warehouse: Google offre BigQuery, Amazon ha Redshift e Microsoft ha Azure SQL Data Warehouse. Ci sono anche offerte cloud di artisti del calibro di Snowflake che forniscono le stesse funzionalità tramite un servizio che gira sul cloud pubblico, ma è gestito in modo indipendente. Per ciascuno di questi servizi, il fornitore di cloud o il provider di data warehouse offre le seguenti funzionalità “out of the box”:
- Archiviazione e gestione dei dati: i dati vengono archiviati in un file system basato su cloud (es. S3).
- Aggiornamenti automatici: non esiste un concetto di” versione ” o aggiornamento software.
- Gestione della capacità: è facile espandere (o contrarre) l’impronta dei dati.
Fattori da considerare quando si sceglie un Data Warehouse Cloud
Come questi fornitori di cloud data warehouse offrono queste funzionalità e come fanno pagare per loro è dove le cose diventano più sfumate. Approfondiamo le diverse implementazioni di distribuzione e i modelli di prezzo.
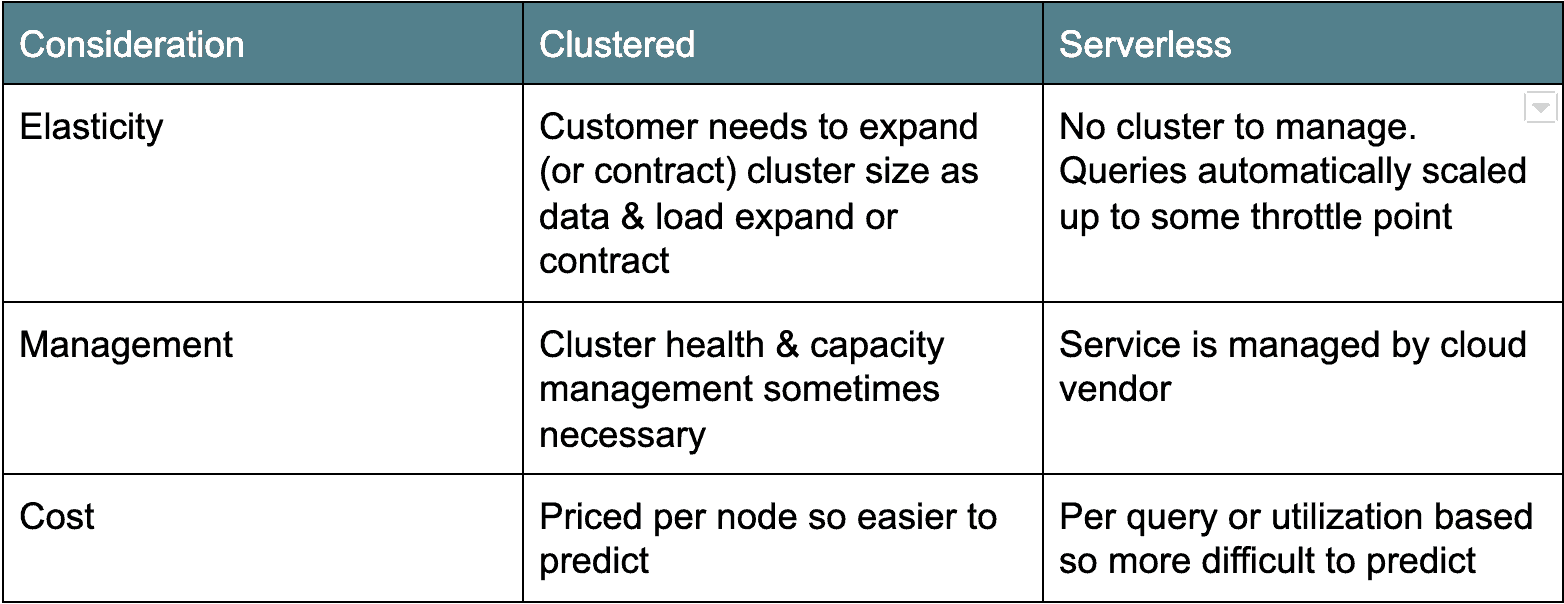
Architettura cloud: Cluster versus Serverless
Esistono due campi principali di architetture cloud data warehouse. La prima architettura di distribuzione precedente è basata su cluster: Amazon Redshift e Azure SQL Data Warehouse rientrano in questa categoria. In genere, i data warehouse cloud in cluster sono in realtà solo derivati Postgres in cluster, portati per essere eseguiti come servizio nel cloud. L’altro sapore, serverless, è più moderno e conta Google BigQuery e Snowflake come esempi. In sostanza, i data warehouse cloud serverless rendono il cluster di database “invisibile” o condiviso tra molti client. Ogni architettura ha i suoi pro e contro (vedi sotto).
Cloud Data Pricing: Paga dal Drink o dal Server
Oltre all’architettura di distribuzione, un’altra importante differenza tra le opzioni di cloud data warehouse è il prezzo. In tutti i casi, si paga una tassa nominale per la quantità di dati memorizzati. Ma il prezzo differisce per il calcolo.
Ad esempio, Google BigQuery e Snowflake offrono opzioni di prezzo on-demand in base alla quantità di dati scansionati o al tempo di calcolo utilizzato. Amazon Redshift e Azure SQL Data Warehouse offrono prezzi delle risorse in base al numero o ai tipi di nodi nel cluster. Ci sono pro e contro di entrambi i tipi di modelli di prezzo. I modelli on-demand addebitano solo ciò che si utilizza, il che può rendere difficile il budget in quanto è difficile prevedere il numero di utenti e il numero e la dimensione delle query che verranno eseguite. Conosco un esempio di cliente in cui un utente ha eseguito erroneamente una query da $1.000+.
Per i modelli basati su nodi (ad esempio Amazon Redshift e Azure SQL Data Warehouse), si paga in base al server e/o al tipo di server. Questo modello di prezzo è ovviamente più prevedibile, ma è “sempre attivo”, quindi stai pagando un prezzo forfettario indipendentemente dall’utilizzo.
Il prezzo è una considerazione importante e richiede una grande quantità di modelli di casi d’uso e carichi di lavoro per trovare la soluzione giusta per la tua organizzazione.
Sfide e considerazioni per la migrazione cloud (i “trucchi”)
In AtScale, abbiamo visto molte aziende tentare una migrazione dai loro data lake on-premise e/o data warehouse relazionali al cloud. Per molti, le loro migrazioni “stallo” dopo il primo progetto pilota a causa dei seguenti motivi:
- Interruzione: gli utenti downstream (analisti aziendali, data scientist) devono cambiare le loro abitudini e ri-toolare i loro report e dashboard.
- Prestazioni: il cloud DW non corrisponde alle prestazioni delle piattaforme di dati on-premise legacy altamente sintonizzate.
- Shock adesivo-costi operativi imprevisti o non pianificati e mancanza di controlli sui costi.
Questo è dove AtScale può aiutare
Mantenere ciò che hai
AtScale A3 riduce al minimo o elimina le interruzioni aziendali dovute alle migrazioni della piattaforma consentendo all’azienda di continuare a utilizzare i propri strumenti di BI, dashboard e report esistenti senza ricodificarli o abbandonarli del tutto. Come possiamo farlo? AtScale Universal Semantic Layer ™ fornisce un’astrazione che sfrutta gli schemi della piattaforma legacy re-mappandoli virtualmente nel nuovo data warehouse cloud. Ciò significa che i report e i dashboard esistenti funzioneranno sulla nuova piattaforma di dati cloud con una ricodifica minima o nulla.
Potenzia le tue prestazioni
Vedo che molte aziende diventano disilluse dalle prestazioni della loro nuova piattaforma di dati cloud. Quello che spesso non riescono a considerare è che il loro data warehouse on-premise esistente (cioè Teradata, Oracle) è stato sintonizzato per anni o addirittura decenni. Ottenere lo stesso livello di prestazioni “out of the box” con un data warehouse cloud non è realistico.
AtScale Adaptive Cache ™ funziona generando automaticamente aggregati sulla piattaforma di dati cloud in base ai modelli di query degli utenti. Evitando scansioni di tabelle costose e dispendiose in termini di tempo, la piattaforma AtScale offre query veloci e coerenti a “velocità di pensiero”. Abbiamo aiutato molti clienti a superare le loro sfide in termini di prestazioni e a sbloccare le migrazioni nel cloud.
Tenere un coperchio sui costi
Non riesco nemmeno a contare il numero di volte che ho sentito che la gente si lamenta che i loro costi cloud sono molto più alti di quanto previsto e imprevedibile per l’avvio. Anche in questo caso, il AtScale Adaptive Cache™ per il salvataggio. Riducendo le scansioni di tabelle non necessarie, possiamo migliorare le prestazioni complessive, la concorrenza e la prevedibilità dei costi, consentendo di ottenere di più dalla piattaforma dati senza aumentare i costi. Con le query generate dalla macchina di AtScale, renderemo i costi prevedibili ed elimineremo il rischio associato alle query SQL scritte a mano.
Credo sinceramente che i data warehouse cloud siano un punto di svolta e la prossima ondata nel data warehousing. Utilizzati con attenzione, i data warehouse cloud possono ridurre drasticamente i costi operativi, offrendo al contempo l’agilità necessaria per tenere il passo con le esigenze del business.