um armazém de dados em nuvem é um banco de dados fornecido em uma nuvem pública como um serviço gerenciado que é otimizado para análise, escala e facilidade de uso.
In the late 80s, I remember my first time working with Oracle 6, a “relational” database where data was formatted into tables. O conceito de um serviço de dados onde eu poderia carregar dados e, em seguida, consultá-lo com uma linguagem padrão (SQL) foi uma mudança de jogo para mim. Nos anos 90, quando os bancos de dados relacionais começaram a lutar contra o tamanho e a complexidade das cargas analíticas, vimos o surgimento dos armazéns de dados MPP como Teradata, Netezza e mais tarde, Vertica e Greenplum. Em 2010 no Yahoo!, mais de 20 anos após o nascimento da base de dados relacional, tive a sorte de testemunhar uma mudança Marítima na gestão de dados com um projeto de código aberto chamado Hadoop. O conceito de um” lago de dados ” onde eu poderia consultar dados brutos não estruturados foi um enorme salto em frente na minha capacidade de capturar, armazenar e processar mais dados com mais agilidade a um custo substancialmente menor.Estamos agora a assistir a uma terceira vaga de inovação na tecnologia de armazenamento de dados com o advento de armazéns de dados em nuvem. À medida que as empresas se movem para a nuvem, elas estão abandonando suas tecnologias de armazenamento de dados no local, incluindo a Hadoop, para essas novas plataformas de dados na nuvem. Esta transformação é uma enorme mudança tectônica na gestão de dados e tem profundas implicações para as empresas.
Os Benefícios de uma Nuvem de Armazém de Dados
dados baseados em Nuvem armazéns liberar as empresas a focar-se em seus negócios, em vez de executar uma sala cheia de servidores, e que permitem a inteligência de negócios equipes para entregar mais rápido e com melhores resultados, devido à melhoria do acesso, a escalabilidade e o desempenho.
- acesso aos Dados: colocar os seus dados na nuvem permite que as empresas dêem aos seus analistas acesso aos dados em tempo real a partir de numerosas fontes, permitindo-lhes executar análises melhores rapidamente.
- escalabilidade: É muito mais rápido e menos dispendioso para a escala de uma nuvem de armazém de dados de um sistema instalado no local, pois ele não requer a compra de novo hardware (e, possivelmente, sobre – ou sub-fornecimento) e o dimensionamento pode acontecer automaticamente, conforme necessário
- Desempenho: Uma nuvem de armazém de dados permite que as consultas sejam executadas muito mais rápido do que eles são contra um tradicional local de armazém de dados, por um custo menor.
capacidade de armazenamento de dados em nuvem
cada um dos principais fornecedores públicos de nuvem oferecem o seu próprio sabor de um serviço de armazenamento de dados em nuvem: Google oferece BigQuery, Amazon tem Redshift e Microsoft tem Azure SQL Data Warehouse. Há também ofertas em nuvem de tipos como Floco de neve que fornecem as mesmas capacidades através de um serviço que funciona na nuvem pública, mas é gerenciado de forma independente. Para cada um destes serviços, o fornecedor ou fornecedor de armazenamento de dados em nuvem oferece as seguintes capacidades “fora da caixa””:
- armazenamento e gestão de dados: os dados são armazenados num sistema de ficheiros em nuvem (ou seja, S3).
- upgrades automáticas: não há conceito de uma “versão” ou atualização de software.
- Gestão de capacidade: é fácil expandir (ou contratar) a sua pegada de dados.
factores a considerar ao escolher um armazém de dados em nuvem
como estes fornecedores de armazenamento de dados em nuvem fornecem estas capacidades e como cobram por elas é onde as coisas ficam mais nuances. Vamos mergulhar mais profundamente nas diferentes implementações de implantação e modelos de preços.
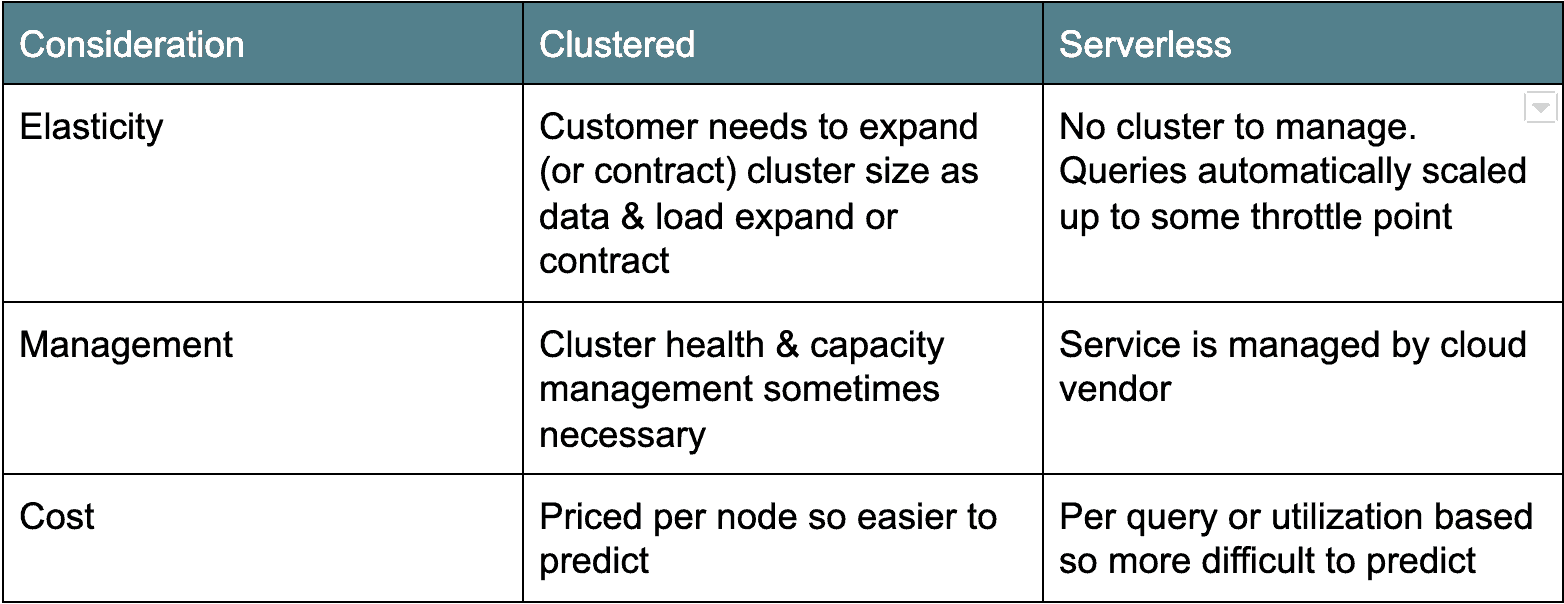
Cloud Architecture: Cluster versus Serverless
There are two main camps of cloud data warehouse architectures. A primeira, mais antiga arquitetura de implantação é baseada em cluster: Amazon Redshift e Azure SQL Data Warehouse caem nesta categoria. Normalmente, depósitos de dados cluster em nuvem são apenas derivados de Postgres agrupados, portados para funcionar como um serviço na nuvem. O outro sabor, sem Server, é mais moderno e conta o Google BigQuery e Floco de neve como exemplos. Essencialmente, depósitos de dados em nuvem sem servidores tornam o aglomerado de dados “invisível” ou compartilhado por muitos clientes. Cada arquitetura tem seus prós e contras (veja abaixo).
Cloud Data Pricing: Pagar pela bebida ou pelo servidor
além da arquitetura de implantação, outra grande diferença entre as opções de armazenamento de dados na nuvem é o preço. Em todos os casos, você paga alguma taxa nominal para a quantidade de dados armazenados. Mas o preço difere para o cálculo.
por exemplo, o Google BigQuery e o Snowflake oferecem opções de preços a pedido com base na quantidade de dados digitalizados ou no tempo de cálculo utilizado. Amazon Redshift and Azure SQL Data Warehouse offer resource pricing based on the number or types of nods in the cluster. Existem prós e contras para ambos os tipos de modelos de preços. Os modelos on-demand apenas cobram o que você usa, o que pode tornar a orçamentação difícil, uma vez que é difícil prever o número de usuários e o número e o tamanho das consultas que eles estarão executando. Eu conheço um exemplo de cliente onde um usuário erroneamente executou uma pesquisa de $ 1.000+.
para os modelos baseados em nós (isto é, Amazon Redshift e Azure SQL Data Warehouse), você paga pelo servidor e/ou tipo de servidor. Este modelo de preços é obviamente mais previsível, mas é “sempre on” para que você está pagando um preço fixo, independentemente do uso.
o preço é uma consideração importante e requer uma grande quantidade de casos de uso e modelagem de carga de trabalho para encontrar o adequado para a sua organização.
desafios e considerações para a migração de nuvens (os “Gotchas”)
em escala, vimos muitas empresas tentarem uma migração dos seus lagos de dados no local e/ou armazéns de dados relacionais para a nuvem. Para muitos, as suas migrações “empatam” após o primeiro projecto-piloto devido às seguintes razões:
- perturbação: os utilizadores a jusante (analistas de negócios, cientistas de dados) têm de mudar os seus hábitos e reformular os seus relatórios e painéis de instrumentos.
- Performance: the cloud DW doesn’t match performance of highly tuned, legacy on-premise data Platform.
- Sticker shock-unanticipated or unplanned operating costs and lack of cost controls.
Este é o lugar onde AtScale pode ajudar a
Manter o Que você Tem
AtScale A3 minimiza ou elimina a interrupção dos negócios devido a migrações de plataforma, permitindo que a empresa continue a utilizar os seus actuais ferramentas de business intelligence, dashboards e relatórios sem re-codificação ou abandoná-los completamente. Como podemos fazer isto? A AtScale Universal Semantic Layer™ fornece uma abstração que alavanca os esquemas de plataforma legados, virtualmente re-mapeando-os para o seu novo armazém de dados na nuvem. Isso significa que seus relatórios e painéis de controle existentes irão trabalhar na nova plataforma de dados de nuvem com o mínimo ou nenhum re-codificação.
sobrecarrega o seu desempenho
vejo muitas empresas ficarem desiludidas com o desempenho da sua nova plataforma de dados na nuvem. O que eles muitas vezes não consideram é que seu armazém de dados on-premise (ou seja, Teradata, Oracle) já está sintonizado há anos ou mesmo décadas. Obter o mesmo nível de desempenho “fora da caixa” com um armazém de dados em nuvem não é realista.
o AtScale Adaptive Cache™ funciona gerando automaticamente agregados na sua plataforma de dados de nuvem com base em padrões de consulta do utilizador. Ao evitar varreduras de mesa dispendiosas e demoradas, a plataforma AtScale oferece consultas rápidas e consistentes a “velocidade do pensamento”. Nós ajudamos muitos clientes a superar seus desafios de desempenho e desbloquear suas migrações na nuvem.
mantenha uma tampa sobre os custos
eu nem posso contar o número de vezes que eu ouvi as pessoas queixam-se de que seus custos de nuvem são muito mais elevados do que eles anteciparam e imprevisível para arrancar. Mais uma vez, é o Cache adaptativo AtScale™ para o resgate. Ao reduzir varreduras de tabela desnecessárias, podemos melhorar o desempenho geral, concorrência e previsibilidade de custos, permitindo que você obtenha mais de sua plataforma de dados sem aumentar o custo. Com as consultas geradas pela máquina da AtScale, tornaremos os seus custos previsíveis e eliminaremos o risco associado às consultas SQL escritas à mão.Acredito sinceramente que os armazéns de dados em nuvem são uma mudança de jogo e a próxima onda no armazenamento de dados. Usado de forma pensada, os depósitos de dados em nuvem podem reduzir drasticamente seus custos operacionais, dando-lhe a agilidade para acompanhar as demandas do negócio.