hurtownia danych w chmurze to baza danych dostarczana w chmurze publicznej jako zarządzana usługa zoptymalizowana pod kątem analityki, skali i łatwości obsługi.
pod koniec lat 80. pamiętam, że pierwszy raz pracowałem z Oracle 6, „relacyjną” bazą danych, w której dane były formatowane w tabele. Koncepcja usługi danych, w której mogłem załadować dane, a następnie odpytywać je za pomocą standardowego języka (SQL), była dla mnie przełomowa. W latach 90., kiedy relacyjne bazy danych zaczęły zmagać się z wielkością i złożonością obciążeń analitycznych, pojawiły się hurtownie danych MPP, takie jak Teradata, Netezza, a później Vertica i Greenplum. W 2010 roku w Yahoo!, ponad 20 lat po narodzinach relacyjnej bazy danych, miałem szczęście być świadkiem morskiej zmiany w zarządzaniu danymi dzięki projektowi open source o nazwie Hadoop. Koncepcja „jeziora danych”, w którym mogłem sprawdzać surowe dane nieustrukturyzowane, była ogromnym krokiem naprzód w mojej zdolności do przechwytywania, przechowywania i przetwarzania większej ilości danych przy znacznie niższych kosztach.
jesteśmy świadkami trzeciej fali innowacji w technologii hurtowni danych wraz z pojawieniem się hurtowni danych w chmurze. W miarę jak przedsiębiorstwa przechodzą do chmury, rezygnują ze swoich dotychczasowych lokalnych technologii hurtowni danych, w tym Hadoop, na rzecz nowych platform danych w chmurze. Ta transformacja jest ogromną tektoniczną zmianą w zarządzaniu danymi i ma głębokie konsekwencje dla przedsiębiorstw.
zalety hurtowni danych w chmurze
hurtownie danych w chmurze pozwalają firmom skupić się na prowadzeniu działalności, a nie na prowadzeniu pokoju pełnego serwerów, a także umożliwiają zespołom analityki biznesowej dostarczanie szybszych i lepszych informacji dzięki lepszemu dostępowi, skalowalności i wydajności.
- dostęp do danych: umieszczenie danych w chmurze umożliwia firmom zapewnienie analitykom dostępu do danych w czasie rzeczywistym z wielu źródeł, co pozwala im szybko przeprowadzać lepsze analizy.
- skalowalność: Skalowanie hurtowni danych w chmurze jest znacznie szybsze i tańsze niż w przypadku systemu lokalnego, ponieważ nie wymaga zakupu nowego sprzętu (i ewentualnie nadmiernej lub niedostatecznej alokacji), a skalowanie może odbywać się automatycznie w razie potrzeby
- wydajność: hurtownia danych w chmurze pozwala na uruchamianie zapytań znacznie szybciej niż w przypadku tradycyjnej lokalnej hurtowni danych, co zapewnia niższe koszty.
możliwości hurtowni danych w chmurze
każdy z głównych dostawców chmury publicznej oferuje swój własny smak usługi hurtowni danych w chmurze: Google oferuje BigQuery, Amazon ma Redshift, a Microsoft ma Azure SQL Data Warehouse. Istnieją również oferty w chmurze, takie jak Snowflake, które zapewniają te same możliwości za pośrednictwem usługi, która działa w chmurze publicznej, ale jest zarządzana niezależnie. Dla każdej z tych usług dostawca usług w chmurze lub dostawca hurtowni danych zapewnia następujące funkcje „po wyjęciu z pudełka”:
- przechowywanie i zarządzanie danymi: dane są przechowywane w systemie plików opartym na chmurze (np.
- automatyczne aktualizacje: nie ma koncepcji” wersji ” ani aktualizacji oprogramowania.
- Zarządzanie pojemnością: rozszerzenie (lub kontraktowanie) śladu danych jest łatwe.
czynniki, które należy wziąć pod uwagę przy wyborze hurtowni danych w chmurze
w jaki sposób dostawcy hurtowni danych w chmurze zapewniają te możliwości i jak za nie pobierają opłaty, sprawy stają się bardziej niuansowane. Przyjrzyjmy się bliżej różnym wdrożeniom i modelom cenowym.
Architektura chmury: Klaster kontra Bezserwerowa
istnieją dwa główne obozy architektur hurtowni danych w chmurze. Pierwsza, starsza Architektura wdrożenia oparta jest na klastrach: Amazon Redshift i Azure SQL Data Warehouse należą do tej kategorii. Zazwyczaj klastrowe hurtownie danych w chmurze są tak naprawdę tylko klastrowymi pochodnymi Postgres, przeniesionymi do działania jako usługa w chmurze. Inny smak, serverless, jest bardziej nowoczesny i liczy Google BigQuery i Snowflake jako przykłady. Zasadniczo bezserwerowe hurtownie danych w chmurze sprawiają, że klaster baz danych jest „niewidoczny” lub udostępniany wielu klientom. Każda architektura ma swoje plusy i minusy(patrz niżej).
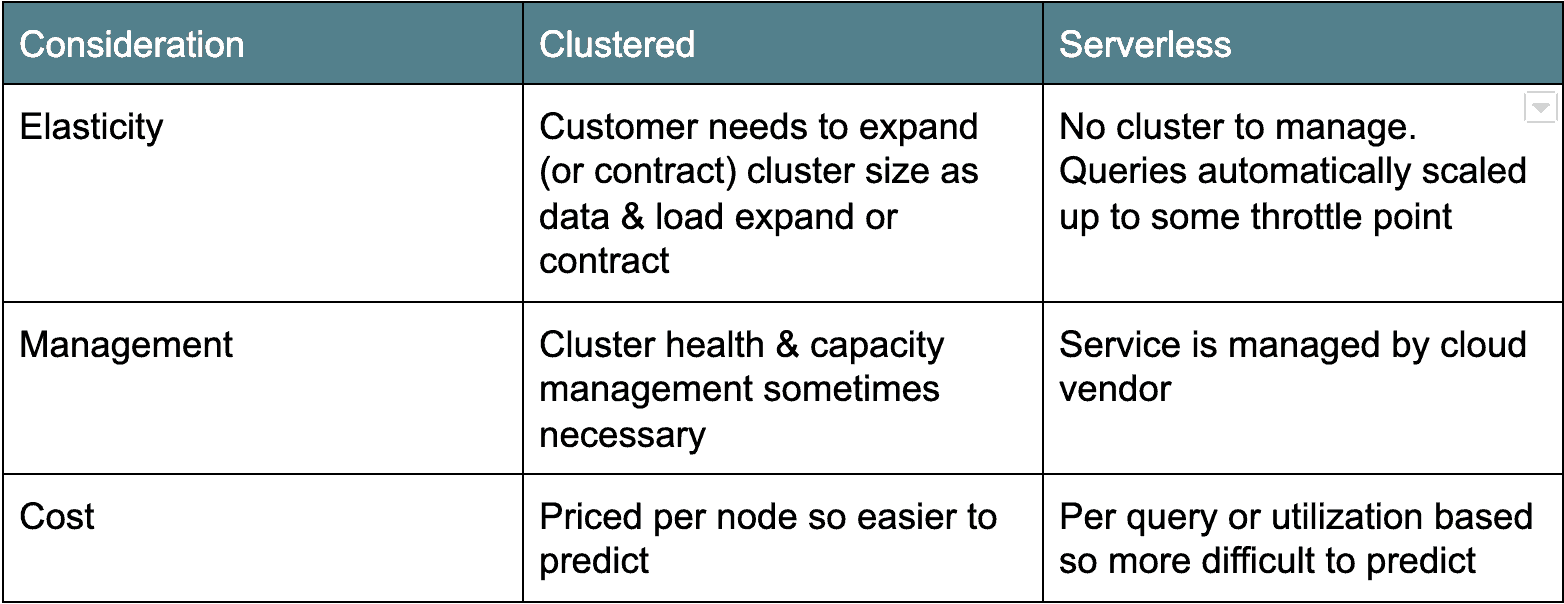
Ceny danych w chmurze: Zapłać przez Drink lub przez serwer
oprócz architektury wdrożenia, inną ważną różnicą między opcjami hurtowni danych w chmurze jest wycena. We wszystkich przypadkach płacisz pewną nominalną opłatę za ilość przechowywanych danych. Ale ceny różnią się w przypadku obliczeń.
na przykład Google BigQuery i Snowflake oferują opcje cenowe na żądanie w oparciu o ilość zeskanowanych danych lub wykorzystany czas obliczeniowy. Amazon Redshift i Azure SQL Data Warehouse oferują ceny zasobów na podstawie liczby lub typów węzłów w klastrze. Istnieją plusy i minusy obu typów modeli cenowych. Modele na żądanie pobierają tylko opłaty za to, czego używasz, co może utrudnić budżetowanie, ponieważ trudno jest przewidzieć liczbę użytkowników oraz liczbę i rozmiar zapytań, które będą uruchamiane. Znam przykład jednego klienta, w którym użytkownik błędnie uruchomił zapytanie $ 1,000+.Amazon Redshift i Azure SQL Data Warehouse), płacisz według typu serwera i / lub serwera. Ten model cenowy jest oczywiście bardziej przewidywalny, ale jest „zawsze włączony”, więc płacisz stałą cenę niezależnie od użytkowania.
wycena jest ważnym czynnikiem i wymaga wielu przypadków użycia i modelowania obciążenia, aby znaleźć odpowiednie dopasowanie do Twojej organizacji.
wyzwania i rozważania dotyczące migracji do chmury („Gotchas”)
w AtScale wiele przedsiębiorstw próbowało migracji z lokalnych jezior danych i/lub relacyjnych hurtowni danych do chmury. Dla wielu ich migracje „zatrzymują się” po pierwszym projekcie pilotażowym z następujących powodów:
- zakłócenie: dalsi użytkownicy (analitycy biznesowi, analitycy danych) muszą zmienić swoje nawyki i ponownie dostosować swoje raporty i pulpity nawigacyjne.
- wydajność: Cloud DW nie dorównuje wydajności wysoko dostrojonych, starszych lokalnych platform danych.
- sticker shock – nieprzewidziane lub nieplanowane koszty operacyjne i brak kontroli kosztów.
tutaj AtScale może pomóc
zachować to, co masz
AtScale A3 minimalizuje lub eliminuje zakłócenia biznesowe spowodowane migracjami platform, umożliwiając firmie dalsze korzystanie z istniejących narzędzi BI, pulpitów nawigacyjnych i raportów bez ponownego kodowania lub ich całkowitego porzucania. Jak możemy to zrobić? Atscale Universal Semantic Layer ™ zapewnia abstrakcję, która wykorzystuje istniejące schematy platformy, wirtualnie odwzorowując je na nową hurtownię danych w chmurze. Oznacza to, że istniejące raporty i pulpity nawigacyjne będą działać na nowej platformie danych w chmurze z minimalnym lub bez ponownego kodowania.
Zwiększ swoją wydajność
widzę, że wiele przedsiębiorstw rozczarowuje się wydajnością nowej platformy danych w chmurze. To, czego często nie biorą pod uwagę, to fakt, że ich istniejąca lokalna hurtownia danych (tj. Teradata, Oracle) była dostrojona od lat, a nawet dziesięcioleci. Uzyskanie takiego samego poziomu wydajności „po wyjęciu z pudełka” z hurtownią danych w chmurze nie jest realistyczne.
Atscale Adaptive Cache™ działa poprzez automatyczne generowanie agregatów na platformie danych w chmurze na podstawie wzorców zapytań użytkownika. Unikając kosztownego i czasochłonnego skanowania tabel, Platforma AtScale zapewnia szybkie, spójne zapytania z „szybkością myślenia”. Pomogliśmy wielu klientom przezwyciężyć problemy związane z wydajnością i odblokować migracje chmury.
Kontroluj koszty
nie mogę nawet policzyć, ile razy słyszałem, że ludzie narzekają, że ich koszty chmury są znacznie wyższe niż przewidywano i nieprzewidywalne do uruchomienia. Ponownie, to Atscale Adaptive Cache™ na ratunek. Ograniczając niepotrzebne skanowanie tabel, możemy poprawić ogólną wydajność, współbieżność i przewidywalność kosztów, co pozwala uzyskać więcej z platformy danych bez zwiększania kosztów. Dzięki zapytaniom generowanym maszynowo przez AtScale sprawimy, że Twoje koszty będą przewidywalne i wyeliminujemy ryzyko związane z ręcznie pisanymi zapytaniami SQL.
szczerze wierzę, że hurtownie danych w chmurze to przełom i kolejna fala hurtowni danych. Używane w sposób przemyślany, hurtownie danych w chmurze mogą znacznie obniżyć koszty operacyjne, zapewniając jednocześnie elastyczność, aby nadążyć za wymaganiami firmy.