et datalager i skyen er en database som leveres i en offentlig sky som en administrert tjeneste som er optimalisert for analyse, skalering og brukervennlighet.
på slutten av 80-tallet husker jeg første gang jeg jobbet Med Oracle 6, En «relasjonell» database der data ble formatert i tabeller. Konseptet med en datatjeneste der jeg kunne laste inn data og deretter spørre det med et standardspråk (SQL) var en spillveksler for meg. På 90-tallet, da relasjonsdatabaser begynte å slite med størrelsen og kompleksiteten til analytiske arbeidsbelastninger, så vi fremveksten AV mpp-datalager Som Teradata, Netezza og senere, Vertica og Greenplum. I 2010 På Yahoo!, mer enn 20 år etter fødselen av relasjonsdatabasen, var jeg heldig nok til å oppleve en sjøendring i datahåndtering med et åpen kildekodeprosjekt Kalt Hadoop. Konseptet med en «datasjø» der jeg kunne spørre rå ustrukturerte data var et stort sprang fremover i min evne til å fange, lagre og behandle mer data med mer smidighet til en vesentlig lavere kostnad.
vi er nå vitne til en tredje bølge av innovasjon i datavarehus teknologi med bruk av sky datalagre. Etter hvert som bedrifter flytter til skyen, forlater de sine eldre lokale datalagerteknologier, inkludert Hadoop, for disse nye skydataplattformene. Denne transformasjonen er et stort tektonisk skifte i datahåndtering og har dype implikasjoner for bedrifter.
Fordelene ved Et Skybasert Datalager
Skybaserte datalager frigjør bedrifter til å fokusere på å drive sin virksomhet, i stedet for å kjøre et rom fullt av servere, og de gjør det mulig for business intelligence-team å levere raskere og bedre innsikt på grunn av forbedret tilgang, skalerbarhet og ytelse.
- Datatilgang: Ved Å legge dataene i skyen kan bedrifter gi analytikerne tilgang til sanntidsdata fra mange kilder, slik at de kan kjøre bedre analyser raskt.
- Skalerbarhet: Det er mye raskere og billigere å skalere et skybasert datalager enn et lokalt system fordi det ikke krever kjøp av ny maskinvare (og muligens over-eller under – klargjøring), og skaleringen kan skje automatisk etter behov
- Ytelse: et skybasert datalager gjør det mulig å kjøre spørringer mye raskere enn de er mot et tradisjonelt lokalt datalager, for lavere kostnader.
Cloud Data Warehouse-Funksjoner
Hver av de store offentlige skyleverandørene tilbyr sin egen smak av en cloud data warehouse-tjeneste: Google tilbyr BigQuery, Amazon Har Redshift og Microsoft Har Azure SQL Data Warehouse. Det er også sky tilbud fra Slike Som Snowflake som gir de samme mulighetene via en tjeneste som kjører på den offentlige skyen, men administreres uavhengig. For hver av disse tjenestene leverer sky-leverandøren eller datalagerleverandøren følgende funksjoner «ut av boksen»:
- datalagring og-administrasjon: data lagres i et skybasert filsystem (Dvs.S3).
- Automatiske oppgraderinger: Det er ikke noe konsept om en «versjon» eller programvareoppgradering.
- Kapasitetsstyring: Det er enkelt å utvide (eller kontrakt) ditt datafotavtrykk.
Faktorer Å Vurdere Når Du Velger Et Skydatalager
Hvordan disse skydatalagerleverandørene leverer disse funksjonene, og hvordan de tar betalt for dem, er hvor ting blir mer nyansert. La oss dykke dypere inn i de forskjellige implementeringene og prismodellene.
Skyarkitektur: Cluster versus Serverless
det er to hovedleirer av cloud data warehouse arkitekturer. Den første eldre distribusjonsarkitekturen er klyngebasert: Amazon Redshift og Azure SQL Data Warehouse faller inn under denne kategorien. Vanligvis er grupperte sky datavarehus egentlig bare grupperte Postgresderivater, portet for å kjøre som en tjeneste i skyen. Den andre smaken, serverless, er mer moderne og teller Google BigQuery og Snowflake som eksempler. Serverløse skylagre gjør databaseklyngen «usynlig» eller delt på tvers av mange klienter. Hver arkitektur har sine fordeler og ulemper(se nedenfor).
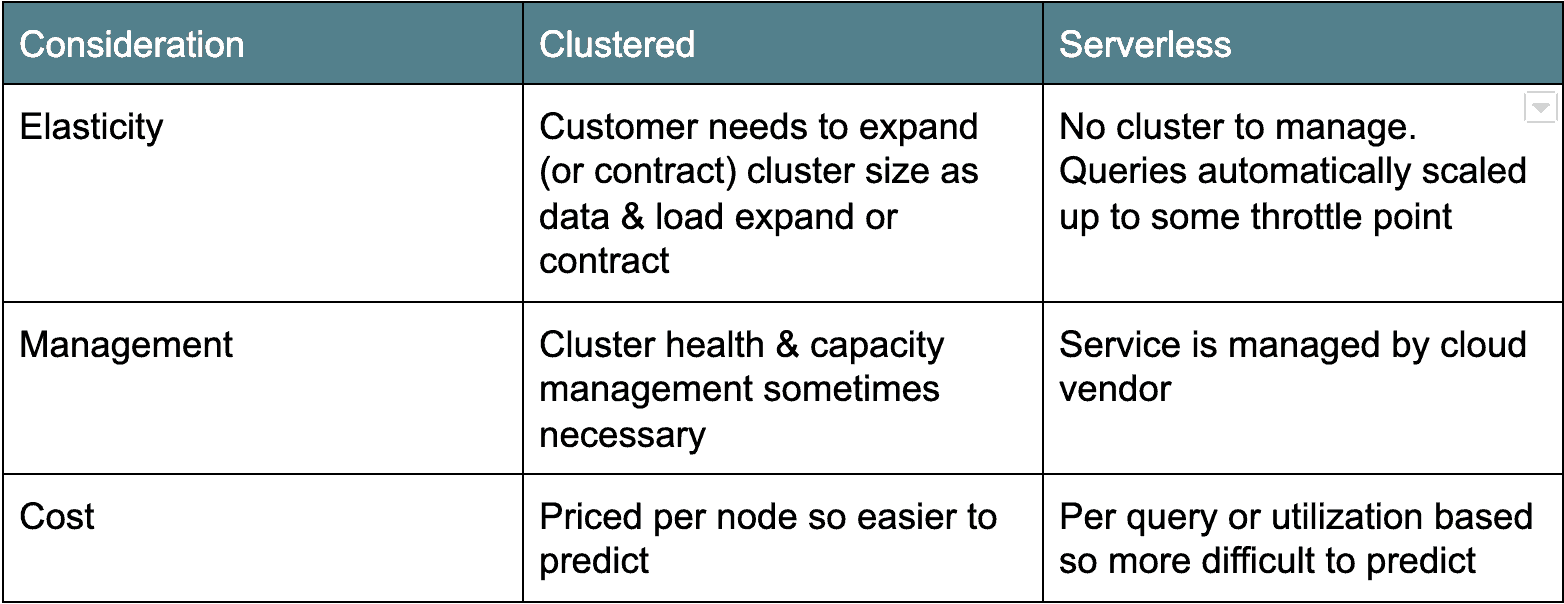
Cloud Data Priser: Betal Med Drikke Eller Av Serveren
Foruten distribusjonsarkitektur er en annen stor forskjell mellom cloud data warehouse-alternativene priser. I alle tilfeller betaler du noen nominell avgift for mengden data lagret. Men prisen varierer for beregning.
For Eksempel Tilbyr Google BigQuery og Snowflake prisalternativer ved behov basert på mengden data som er skannet eller beregnet tid brukt. Amazon Redshift og Azure SQL Data Warehouse tilbyr ressurspriser basert på antall eller typer noder i klyngen. Det er fordeler og ulemper til begge typer prismodeller. On-demand-modellene belaster deg bare for det du bruker, noe som kan gjøre budsjettering vanskelig, da det er vanskelig å forutsi antall brukere og antall og størrelse på spørringene de skal kjøre. Jeg vet ett kundeeksempel hvor en bruker feilaktig kjørte en $ 1000 + spørring.
for nodebaserte modeller (Dvs. Amazon Redshift og Azure SQL Data Warehouse) betaler du etter server-og/eller servertypen. Denne prismodellen er åpenbart mer forutsigbar, men den er «alltid på», så du betaler en flat pris uansett bruk.
Priser er en viktig faktor og krever mye brukstilfelle og arbeidsmengde modellering for å finne riktig passform for organisasjonen.
Utfordringer og Betraktninger for Skyoverføring («Gotchas»)
på AtScale har vi sett mange bedrifter forsøke en overføring fra deres lokale datasjøer og / eller relasjonelle datalager til skyen. For mange ,deres migrasjoner «stall» etter det første pilotprosjektet på grunn av følgende grunner:
- Forstyrrelser: nedstrøms brukere (forretningsanalytikere, datavitenskapere) må endre vaner og re-verktøy sine rapporter og dashboards.
- Ytelse: cloud DW samsvarer ikke med ytelsen til svært avstemte, eldre lokale dataplattformer.
- Sticker shock-uventede eller uplanlagte driftskostnader og mangel på kostnadskontroll.
Dette er hvor AtScale kan hjelpe
Beholde Det Du Har
atscale A3 minimerer eller eliminerer forretningsforstyrrelser på grunn av plattformoverføringer ved å la virksomheten fortsette å bruke sine eksisterende BI-verktøy, dashbord og rapporter uten å omkode eller forlate dem helt. Hvordan kan vi gjøre dette? Atscale Universal Semantic Layer™ gir en abstraksjon som utnytter dine eldre plattformskjemaer ved å praktisk talt tilordne dem til ditt nye sky – datalager. Dette betyr at dine eksisterende rapporter og dashbord vil fungere på den nye skydataplattformen med minimal eller ingen omkoding.
Supercharge Din Ytelse
jeg ser mange bedrifter blir desillusjonert med ytelsen til deres nye cloud data plattform. Det de ofte ikke klarer å vurdere er at deres eksisterende datalager (Dvs. Teradata, Oracle) har blitt innstilt i mange år eller til og med tiår. Å få det samme ytelsesnivået «ut av boksen» med et sky-datalager er ikke realistisk.
atscale Adaptive Cache™ fungerer ved å automatisk generere aggregater på din skydataplattform basert på brukerens spørringsmønstre. Ved å unngå kostbare og tidkrevende tabellskanninger leverer atscale-plattformen raske, konsekvente spørringer med «tankehastighet». Vi har hjulpet mange kunder med å komme forbi ytelsesutfordringene sine og fjerne blokkeringen av skyoverføringen.
Hold Et Lokk på Kostnader
jeg kan ikke engang telle antall ganger jeg har hørt det folk klager over at deres skykostnader er mye høyere enn de forventet og uforutsigbare å starte opp. Igjen er Det AtScale Adaptive Cache™ til redning. Ved å redusere unødvendige tabellskanninger kan vi forbedre total ytelse, samtidighet og forutsigbarhet i kostnader, slik at du får mer ut av dataplattformen uten å øke kostnadene. Med atscales maskingenererte spørringer vil vi gjøre kostnadene forutsigbare og eliminere risikoen forbundet med håndskrevne SQL-spørringer.
jeg tror oppriktig at cloud data warehouses er en spillveksler og den neste bølgen i datalagring. Brukt gjennomtenkt, cloud data warehouses kan dramatisk redusere driftskostnadene samtidig som du gir smidighet for å holde tritt med kravene til virksomheten.