Un entrepôt de données dans le cloud est une base de données fournie dans un cloud public en tant que service géré optimisé pour l’analyse, l’évolutivité et la facilité d’utilisation.
À la fin des années 80, je me souviens de ma première fois avec Oracle 6, une base de données » relationnelle » où les données étaient formatées en tables. Le concept d’un service de données où je pouvais charger des données puis les interroger avec un langage standard (SQL) a changé la donne pour moi. Dans les années 90, lorsque les bases de données relationnelles ont commencé à se débattre avec la taille et la complexité des charges de travail analytiques, nous avons vu l’émergence des entrepôts de données MPP comme Teradata, Netezza et plus tard, Vertica et Greenplum. En 2010 chez Yahoo!, plus de 20 ans après la naissance de la base de données relationnelle, j’ai eu la chance d’assister à un changement radical dans la gestion des données avec un projet open source appelé Hadoop. Le concept de « lac de données » où je pouvais interroger des données brutes non structurées a été un énorme bond en avant dans ma capacité à capturer, stocker et traiter plus de données avec plus d’agilité à un coût nettement inférieur.
Nous assistons maintenant à une troisième vague d’innovation dans la technologie d’entreposage de données avec l’avènement des entrepôts de données en nuage. Au fur et à mesure que les entreprises passent au cloud, elles abandonnent leurs technologies d’entreposage de données sur site héritées, y compris Hadoop, pour ces nouvelles plates-formes de données cloud. Cette transformation est un énorme changement tectonique dans la gestion des données et a de profondes implications pour les entreprises.
Les avantages d’un entrepôt de données dans le Cloud
Les entrepôts de données dans le cloud permettent aux entreprises de se concentrer sur la gestion de leur entreprise, plutôt que de gérer une salle remplie de serveurs, et ils permettent aux équipes de business intelligence de fournir des informations plus rapides et de meilleure qualité grâce à un accès, une évolutivité et des performances améliorés.
- Accès aux données : La mise de leurs données dans le cloud permet aux entreprises de donner à leurs analystes l’accès à des données en temps réel provenant de nombreuses sources, ce qui leur permet d’exécuter rapidement de meilleures analyses.
- Évolutivité: Il est beaucoup plus rapide et moins coûteux de mettre à l’échelle un entrepôt de données en nuage qu’un système sur site, car il ne nécessite pas d’achat de nouveau matériel (et peut-être de sur- ou de sous-provisionnement) et la mise à l’échelle peut se faire automatiquement au besoin
- Performances: Un entrepôt de données en nuage permet d’exécuter les requêtes beaucoup plus rapidement qu’elles ne le sont avec un entrepôt de données sur site traditionnel, à moindre coût.
Capacités d’entrepôt de données en nuage
Chacun des principaux fournisseurs de cloud public offre sa propre saveur de service d’entrepôt de données en nuage: Google propose BigQuery, Amazon a Redshift et Microsoft a Azure SQL Data Warehouse. Il existe également des offres cloud telles que Snowflake qui offrent les mêmes fonctionnalités via un service qui s’exécute sur le cloud public mais est géré de manière indépendante. Pour chacun de ces services, le fournisseur de cloud ou le fournisseur d’entrepôt de données fournit les fonctionnalités suivantes » prêtes à l’emploi »:
- Stockage et gestion des données: les données sont stockées dans un système de fichiers basé sur le cloud (c.-à-d. S3).
- Mises à niveau automatiques : il n’y a pas de concept de « version » ou de mise à niveau logicielle.
- Gestion de la capacité : il est facile d’étendre (ou de contracter) votre empreinte de données.
Facteurs à prendre en compte Lors du choix d’un entrepôt de données en nuage
Comment ces fournisseurs d’entrepôts de données en nuage offrent ces fonctionnalités et comment ils les facturent, c’est là que les choses deviennent plus nuancées. Approfondissons les différentes implémentations de déploiement et modèles de tarification.
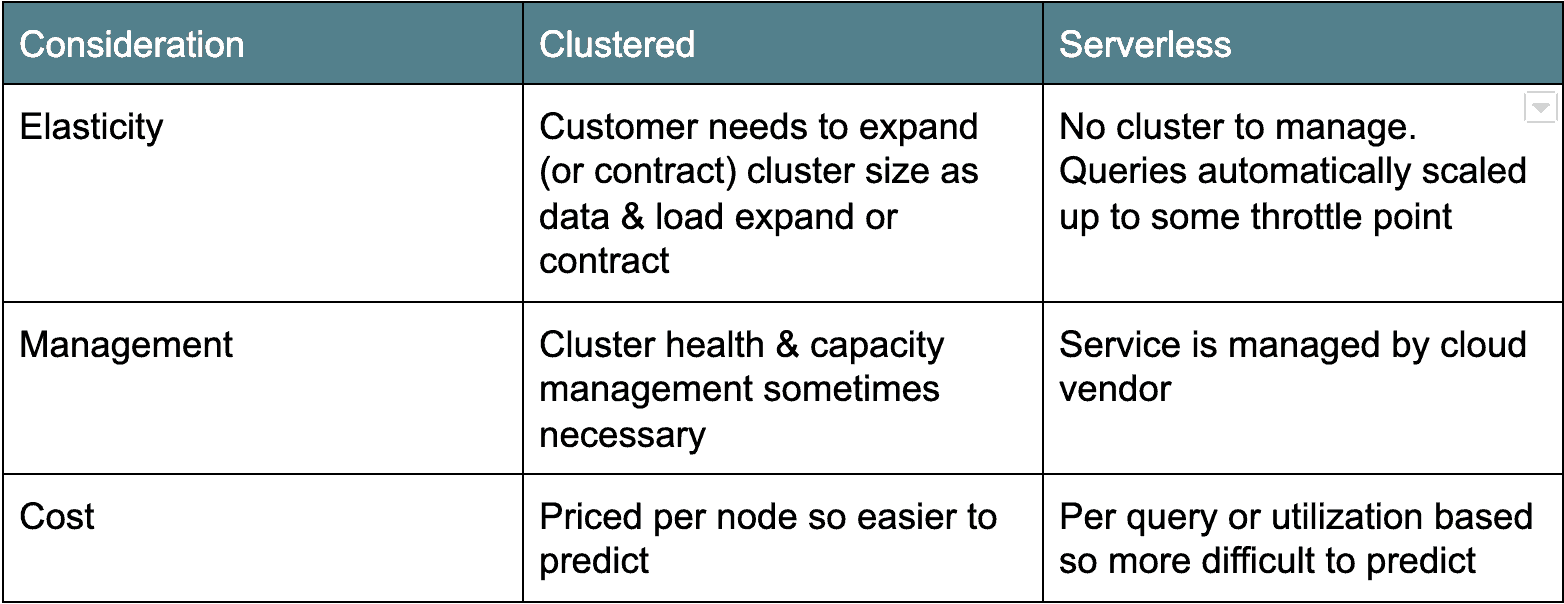
Architecture Cloud : Cluster versus Serverless
Il existe deux principaux camps d’architectures d’entrepôts de données cloud. La première architecture de déploiement, plus ancienne, est basée sur des clusters: Amazon Redshift et Azure SQL Data Warehouse entrent dans cette catégorie. En règle générale, les entrepôts de données cloud en cluster ne sont que des dérivés Postgres en cluster, portés pour fonctionner en tant que service dans le cloud. L’autre saveur, sans serveur, est plus moderne et compte Google BigQuery et Snowflake comme exemples. Essentiellement, les entrepôts de données cloud sans serveur rendent le cluster de bases de données « invisible » ou partagé entre de nombreux clients. Chaque architecture a ses avantages et ses inconvénients (voir ci-dessous).
Tarification des données Cloud: Payer à la boisson ou par le serveur
Outre l’architecture de déploiement, une autre différence majeure entre les options d’entrepôt de données dans le cloud est la tarification. Dans tous les cas, vous payez des frais nominaux pour la quantité de données stockées. Mais le prix diffère pour le calcul.
Par exemple, Google BigQuery et Snowflake proposent des options de tarification à la demande en fonction de la quantité de données analysées ou du temps de calcul utilisé. Amazon Redshift et Azure SQL Data Warehouse proposent une tarification des ressources basée sur le nombre ou les types de nœuds du cluster. Il y a des avantages et des inconvénients aux deux types de modèles de tarification. Les modèles à la demande ne vous facturent que ce que vous utilisez, ce qui peut rendre la budgétisation difficile car il est difficile de prédire le nombre d’utilisateurs et le nombre et la taille des requêtes qu’ils exécuteront. Je connais un exemple de client où un utilisateur a exécuté par erreur une requête de plus de 1 000 $.
Pour les modèles basés sur des nœuds (c’est-à-dire Amazon Redshift et Azure SQL Data Warehouse), vous payez par serveur et/ou type de serveur. Ce modèle de tarification est évidemment plus prévisible, mais il est « toujours activé », vous payez donc un prix forfaitaire quelle que soit l’utilisation.
La tarification est une considération majeure et nécessite beaucoup de modélisation de cas d’utilisation et de charge de travail pour trouver la solution adaptée à votre organisation.
Défis et considérations pour la migration vers le Cloud (les « pièges « )
Chez AtScale, nous avons vu de nombreuses entreprises tenter une migration de leurs lacs de données sur site et/ou entrepôts de données relationnels vers le cloud. Pour beaucoup, leurs migrations « calent » après le premier projet pilote pour les raisons suivantes:
- Perturbation: les utilisateurs en aval (business analysts, data scientists) doivent changer leurs habitudes et ré-outiller leurs rapports et tableaux de bord.
- Performances : le cloud DW ne correspond pas aux performances des plates-formes de données sur site héritées et hautement adaptées.
- Choc autocollant – coûts d’exploitation imprévus ou imprévus et manque de contrôle des coûts.
C’est là qu’AtScale peut aider
À conserver ce que vous avez
AtScale A3 minimise ou élimine les perturbations commerciales dues aux migrations de plates-formes en permettant à l’entreprise de continuer à utiliser ses outils de BI, tableaux de bord et rapports existants sans les recoder ou les abandonner complètement. Comment pouvons-nous faire cela? La couche sémantique universelle AtScale™ fournit une abstraction qui tire parti de vos schémas de plate-forme hérités en les mappant virtuellement à votre nouvel entrepôt de données dans le cloud. Cela signifie que vos rapports et tableaux de bord existants fonctionneront sur la nouvelle plate-forme de données cloud avec un recodage minimal ou nul.
Boostez vos performances
Je vois de nombreuses entreprises désillusionnées par les performances de leur nouvelle plate-forme de données cloud. Ce qu’ils omettent souvent de considérer, c’est que leur entrepôt de données sur site existant (c’est-à-dire Teradata, Oracle) a été réglé pendant des années, voire des décennies. Obtenir le même niveau de performance « prêt à l’emploi » avec un entrepôt de données en nuage n’est pas réaliste.
AtScale Adaptive Cache™ fonctionne en générant automatiquement des agrégats sur votre plate-forme de données cloud en fonction des modèles de requêtes des utilisateurs. En évitant les analyses de table coûteuses et chronophages, la plate-forme AtScale fournit des requêtes rapides et cohérentes à la « vitesse de la pensée « . Nous avons aidé de nombreux clients à surmonter leurs défis de performance et à débloquer leurs migrations vers le cloud.
Gardez un œil sur les coûts
Je ne peux même pas compter le nombre de fois où j’ai entendu des informaticiens se plaindre que leurs coûts de cloud sont beaucoup plus élevés que prévu et imprévisibles au démarrage. Encore une fois, c’est le cache adaptatif AtScale™ à la rescousse. En réduisant les analyses de table inutiles, nous pouvons améliorer les performances globales, la concurrence et la prévisibilité des coûts, ce qui vous permet de tirer le meilleur parti de votre plate-forme de données sans augmenter les coûts. Avec les requêtes générées par machine d’AtScale, nous rendrons vos coûts prévisibles et éliminerons le risque associé aux requêtes SQL écrites à la main.
Je crois sincèrement que les entrepôts de données en nuage changent la donne et constituent la prochaine vague de l’entreposage de données. Utilisés de manière réfléchie, les entrepôts de données dans le cloud peuvent réduire considérablement vos coûts d’exploitation tout en vous offrant l’agilité nécessaire pour répondre aux exigences de l’entreprise.