cloudový datový sklad je databáze dodávaná ve veřejném cloudu jako spravovaná služba optimalizovaná pro analýzu, měřítko a snadné použití.
na konci 80. let si pamatuji, jak jsem poprvé pracoval s Oracle 6, „relační“ databází, kde byla data formátována do tabulek. Koncept datové služby, kde bych mohl načíst data a poté je dotazovat standardním jazykem (SQL), byl pro mě měničem her. V 90. letech, kdy se relační databáze začaly potýkat s velikostí a složitostí analytických pracovních zátěží, jsme viděli vznik datových skladů MPP jako Teradata, Netezza a později Vertica a Greenplum. V roce 2010 na Yahoo!, více než 20 let po narození relační databáze, měl jsem to štěstí, že jsem byl svědkem mořské změny ve správě dat pomocí open source projektu s názvem Hadoop. Koncept „datového jezera“, kde jsem mohl dotazovat surová nestrukturovaná data, byl obrovským skokem vpřed v mé schopnosti zachytit, ukládat a zpracovávat více dat s větší agilitou za podstatně nižší cenu.
nyní jsme svědky třetí vlny inovací v technologii datového skladu s příchodem cloudových datových skladů. Jak se podniky přesouvají do cloudu, opouštějí své starší technologie skladování dat na místě, včetně Hadoop, pro tyto nové cloudové datové platformy. Tato transformace je obrovským tektonickým posunem v oblasti správy dat a má hluboké důsledky pro podniky.
výhody cloudového datového skladu
cloudové datové sklady uvolňují společnosti, aby se soustředily na provoz svého podnikání, spíše než na provoz místnosti plné serverů, a umožňují týmům business intelligence poskytovat rychlejší a lepší informace díky lepšímu přístupu, škálovatelnosti a výkonu.
- přístup k datům: vložení dat do cloudu umožňuje společnostem poskytnout svým analytikům přístup k datům v reálném čase z mnoha zdrojů, což jim umožňuje rychle provádět lepší analytiku.
- škálovatelnost: Škálování cloudového datového skladu je mnohem rychlejší a levnější než on-premise systém, protože nevyžaduje nákup nového hardwaru (a možná nadměrné nebo nedostatečné poskytování) a škálování může probíhat automaticky podle potřeby
- výkon: cloudový datový sklad umožňuje spouštění dotazů mnohem rychleji, než je tomu v případě tradičního datového skladu v areálu, za nižší náklady.
Možnosti cloudového datového skladu
každý z hlavních veřejných dodavatelů cloudu nabízí svou vlastní chuť služby cloudového datového skladu: Google nabízí BigQuery, Amazon má Redshift a Microsoft má Azure SQL Data Warehouse. Existují také cloudové nabídky od Snowflake, které poskytují stejné funkce prostřednictvím služby, která běží na veřejném cloudu, ale je spravována nezávisle. Pro každou z těchto služeb poskytuje dodavatel cloudu nebo poskytovatel datového skladu následující funkce „po vybalení z krabice“:
- ukládání a správa dat: data jsou uložena v cloudovém souborovém systému (tj.
- automatické aktualizace: neexistuje žádný koncept“ verze “ nebo aktualizace softwaru.
- Správa kapacity: je snadné rozšířit (nebo uzavřít smlouvu) vaši datovou stopu.
faktory, které je třeba zvážit při výběru cloudového datového skladu
jak tito dodavatelé cloudových datových skladů poskytují tyto funkce a jak za ně účtují, je místo, kde se věci více liší. Pojďme se ponořit hlouběji do různých implementací nasazení a cenových modelů.
Cloud Architecture: Cluster versus Serverless
existují dva hlavní tábory architektur cloudových datových skladů. První, starší Architektura nasazení je založena na clusteru: Amazon Redshift a Azure SQL Data Warehouse spadají do této kategorie. Typicky, clusterové cloudové datové sklady jsou opravdu jen seskupené deriváty Postgres, portované ke spuštění jako služba v cloudu. Druhá příchuť, bez serveru, je modernější a jako příklady počítá Google BigQuery a Snowflake. Cloudové datové sklady bez serverů v podstatě činí databázový cluster „neviditelným“ nebo sdíleným mezi mnoha klienty. Každá architektura má své klady a zápory (viz níže).
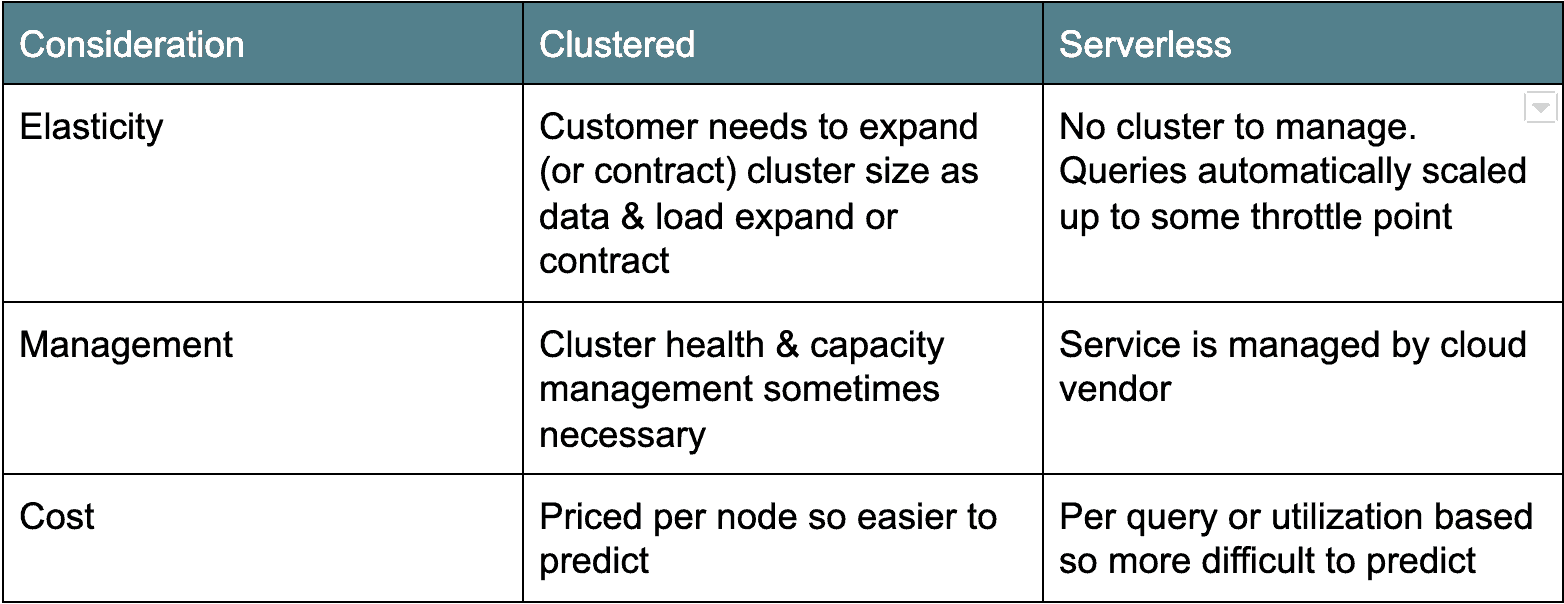
ceny cloudových dat: Platit nápojem nebo serverem
kromě architektury nasazení je dalším významným rozdílem mezi možnostmi cloudového datového skladu cena. Ve všech případech zaplatíte nějaký nominální poplatek za množství uložených dat. Ale ceny se liší pro compute.
například Google BigQuery a Snowflake nabízejí cenové možnosti na vyžádání na základě množství naskenovaných dat nebo použitého výpočetního času. Amazon Redshift a Azure SQL Data Warehouse nabízejí ceny zdrojů na základě počtu nebo typů uzlů v klastru. Existují výhody a nevýhody obou typů cenových modelů. Modely na vyžádání vám účtují pouze to, co používáte, což může ztěžovat rozpočtování, protože je těžké předpovědět počet uživatelů a počet a velikost dotazů, které budou spuštěny. Znám jeden příklad zákazníka, kdy uživatel omylem spustil dotaz $ 1,000+.
u modelů založených na uzlech (tj. Amazon Redshift a Azure SQL Data Warehouse) platíte podle typu serveru a / nebo serveru. Tento cenový model je samozřejmě předvídatelnější, ale je „vždy zapnutý“, takže platíte paušální cenu bez ohledu na použití.
cena je hlavním hlediskem a vyžaduje velké množství případů použití a modelování pracovní zátěže, aby bylo možné najít správné řešení pro vaši organizaci.
výzvy a úvahy o cloudové migraci (dále jen“Gotchas“)
v AtScale jsme viděli, jak se mnoho podniků pokouší o migraci ze svých datových jezer a / nebo relačních datových skladů do cloudu. Pro mnohé se jejich migrace „zastaví“ po prvním pilotním projektu z následujících důvodů:
- narušení: následní uživatelé (obchodní analytici, vědci v oblasti dat) musí změnit své návyky a přepracovat své zprávy a řídicí panely.
- výkon: cloud DW neodpovídá výkonu vysoce vyladěných starších datových platforem.
- nálepka šok-neočekávané nebo neplánované provozní náklady a nedostatek kontroly nákladů.
to je místo, kde AtScale může pomoci
udržet to, co máte
AtScale A3 minimalizuje nebo eliminuje narušení podnikání v důsledku migrace platformy tím, že umožňuje podniku pokračovat v používání svých stávajících BI nástrojů, dashboardů a sestav bez překódování nebo úplného opuštění. Jak to můžeme udělat? AtScale Universal Sémantic Layer™ poskytuje abstrakci, která využívá vaše starší schémata platformy tím, že je prakticky přemapuje do nového cloudového datového skladu. To znamená, že vaše stávající sestavy a dashboardy budou fungovat na nové cloudové datové platformě s minimálním nebo žádným překódováním.
Přeplňujte svůj výkon
vidím, že mnoho podniků je rozčarováno výkonem své nové cloudové datové platformy. To, co často nezohledňují, je, že jejich stávající datový sklad na místě (tj. Získání stejné úrovně výkonu „po vybalení z krabice“ s cloudovým datovým skladem není realistické.
Atscale Adaptive Cache™ funguje tak, že automaticky generuje agregáty na platformě cloudových dat na základě vzorů uživatelských dotazů. Tím, že se vyhnete nákladným a časově náročným skenům tabulek, platforma AtScale poskytuje rychlé a konzistentní dotazy „rychlostí myšlení“. Pomohli jsme mnoha zákazníkům překonat jejich výkonnostní výzvy a odblokovat jejich cloudovou migraci.
Udržujte víko na nákladech
nemohu ani spočítat, kolikrát jsem slyšel, že si lidé stěžují, že jejich cloudové náklady jsou mnohem vyšší,než očekávali a nepředvídatelné. Opět je to AtScale Adaptive Cache™ na záchranu. Snížením zbytečných skenů tabulky, můžeme zlepšit celkový výkon, souběžnost, a předvídatelnost nákladů, což vám umožní získat více z vaší datové platformy bez zvýšení nákladů. Díky strojově generovaným dotazům AtScale učiníme vaše náklady předvídatelnými a eliminujeme riziko spojené s ručně psanými dotazy SQL.
Upřímně věřím, že cloudové datové sklady jsou měničem her a další vlnou v datových skladech. Cloudové datové sklady, které se používají zamyšleně, mohou výrazně snížit vaše provozní náklady a zároveň vám poskytnou obratnost držet krok s požadavky podniku.