tämä on askel askeleelta opas siitä, miten k-means klusterianalyysi suoritetaan Excel-laskentataulukossa alusta loppuun. Huomaa, että on olemassa Excel-malli, joka toimii automaattisesti klusterianalyysi ladattavissa ilmaiseksi tällä sivustolla. Mutta jos haluat tietää, miten ajaa K-tarkoittaa ryhmittelyä Excel itse, niin tämä artikkeli on sinua varten.
tämän artikkelin lisäksi minulla on myös video, miten klusterianalyysi suoritetaan Excelissä.
- ensimmäinen vaihe-Aloita tietokokonaisuudestasi
- Vaihe kaksi-Jos vain kaksi muuttujaa, käytä hajontagrammia Excelissä
- vaihe kolme-Laske etäisyys jokaisesta datapisteestä klusterin keskipisteeseen
- miten laskenta toimii?
- Vaihe neljä-laske kunkin klusterijoukon keskiarvo
- vaihe viisi-toista vaihe 3 – Etäisyys tarkistetusta keskiarvosta
- lopullinen vaihe-kaavio ja yhteenveto klustereista
ensimmäinen vaihe-Aloita tietokokonaisuudestasi
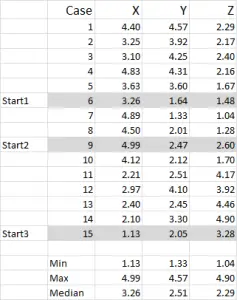
Kuva 1
tässä esimerkissä käytän 15 tapausta (tai vastaajaa), joissa meillä on tiedot kolmesta muuttujasta – yleisesti merkittynä X, Y ja Z.
huomaa, että tässä esimerkissä tiedot on skaalattu 1-5. Tietosi voivat olla missä tahansa muodossa lukuun ottamatta nimellistä tietoasteikkoa (katso artikkeli siitä, mitä tietoja käytetään).
huomautus: käytän mieluummin skaalattuja tietoja-mutta se ei ole pakollista. Syynä tähän on mahdollisten poikkeamien” hillitseminen”. Sano, esimerkiksi, käytän tulotietoja (demografinen toimenpide) – suurin osa tiedoista voi olla noin $40,000 to $100,000, mutta minulla on yksi henkilö, jonka tulot $5m. se on vain helpompi minulle luokitella, että henkilö ”yli $250,000” tuloluokassa ja mittakaavassa tulot 1-9 – mutta se on jopa sinulle riippuen tiedot työskentelet.
tästä esimerkkitapauksesta näkee, että kolme aloituspaikkaa on korostettu-niitä käsitellään seuraavassa vaiheessa kolme.
Vaihe kaksi-Jos vain kaksi muuttujaa, käytä hajontagrammia Excelissä
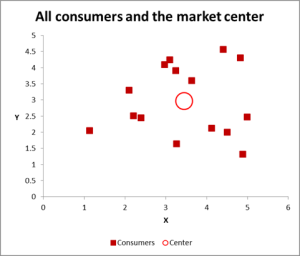
kuva 2
tässä klusterianalyysin esimerkissä käytämme kolmea muuttujaa – mutta jos sinulla on vain kaksi muuttujaa klusteroitavaksi, scatter-kaavio on erinomainen tapa aloittaa. Ja joskus, voit klusterin tiedot visuaalisin keinoin.
kuten voitte nähdä tästä hajontagrammista, jokainen yksittäinen tapaus (jota kutsun tämän esimerkin kuluttajaksi) on kartoitettu, sekä kaikkien tapausten keskiarvo (punainen ympyrä).
riippuen siitä, miten aineistoa/kuvaajaa tarkastellaan-klustereita näyttää olevan useita. Tässä tapauksessa voit tunnistaa kolme tai neljä suhteellisen erillistä klustereita – kuten seuraavassa kaaviossa.
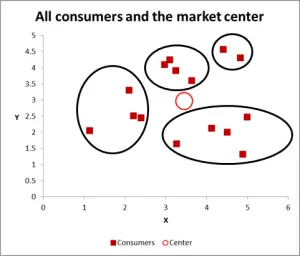
kuva 3
seuraavan kaavion avulla olen tunnistanut todennäköiset klusterit ja ympyröinyt ne. Kuten olen ehdottanut, hyvä lähestymistapa, kun on vain kaksi muuttujaa harkita – mutta tässä tapauksessa meillä on kolme muuttujaa (ja sinulla voisi olla enemmän), joten tämä visuaalinen lähestymistapa toimii vain perustiedot asetetaan – joten nyt tarkastellaan, miten tehdä Excel laskenta k-tarkoittaa klusterointia.
vaihe kolme-Laske etäisyys jokaisesta datapisteestä klusterin keskipisteeseen
tässä läpikulkuesimerkissä oletetaan, että haluamme tunnistaa vain kolme segmenttiä/klusteria. Kyllä, on olemassa neljä klustereita näkyy yllä olevassa kaaviossa, mutta että tarkastellaan vain kaksi muuttujaa. Huomaa, että voit käyttää tätä Excel – lähestymistapaa tunnistamaan niin monta klusteria kuin haluat-seuraa vain samaa konseptia kuin alla on selitetty.
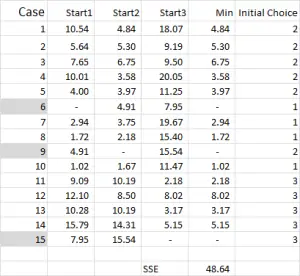
Kuva 4
K-tarkoittaa ryhmittelyä yleensä poimitaan joitakin satunnaisia tapauksia (lähtökohdat tai siemenet) saada analyysi alkaa.
tässä esimerkissä-koska haluan luoda kolme klusteria, niin tarvitsen kolme aloituspistettä. Näihin alkupisteisiin olen valinnut tapaukset 6, 9 ja 15-mutta mitkä tahansa satunnaispisteet voisivat myös olla sopivia.
syy, miksi valitsin nämä tapaukset, on se, että – kun tarkastellaan muuttujaa X vain-tapaus 6 oli mediaani, tapaus 9 oli maksimi ja tapaus 15 oli minimi. Tämä viittaa siihen, että nämä kolme tapausta ovat hieman erilaisia keskenään, niin hyvät lähtökohdat kun ne jakautuvat.
katso artikkelista, Miksi klusterianalyysi tuottaa joskus erilaisia tuloksia.
viitaten taulukon tulosteeseen – tämä on ensimmäinen Laskutoimituksemme Excelissä ja se luo klustereiden ”alustavan valinnan”. Start 1 on tapauksen 6 TIEDOT, start 2 on tapaus 9 ja start 3 on tapaus 15. Huomaa, että risteysalueiden kunkin näistä antaa 0 ( – ) taulukossa.
miten laskenta toimii?
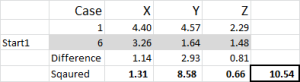
kuva 5
katsotaanpa ensimmäinen numero taulukossa-tapaus 1, Alku 1 = 10.54.
muista, että olemme mielivaltaisesti nimenneet tapauksen 6 sattumanvaraiseksi Alkupisteeksemme klusterille 1. Haluamme laskea etäisyys ja käytämme summa neliöt menetelmä-kuten tässä. Laskemme jokaisen kolmen datapisteen välisen eron, ja sitten neliöimme erot, ja sitten summaamme ne.
voimme tehdä sen ”mekaanisesti” kuten tässä on esitetty – mutta Excel on sisäänrakennettu kaava käyttää: SUMXMY2-tämä on paljon tehokkaampaa käyttää.
viitaten kuvioon 4, löydämme sitten kunkin tapauksen vähimmäisetäisyyden jokaisesta kolmesta alkupisteestä-tämä kertoo, mikä klusteri (1, 2 tai 3), jota tapaus on lähimpänä – joka on esitetty ”initial choice-sarakkeessa”.
Vaihe neljä-laske kunkin klusterijoukon keskiarvo
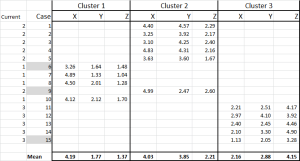
kuva 6
olemme nyt kohdistaneet jokaisen tapauksen sen alkuperäiseen klusteriin – ja voimme vahvistaa sen käyttämällä IF-lausumaa taulukossa (kuten kuvassa 6).
taulukon alareunassa on kunkin tapauksen keskiarvo. N0w-sen sijaan, että luottaisimme vain yhteen ”edustavaan” datapisteeseen – meillä on joukko tapauksia, jotka edustavat kutakin.
vaihe viisi-toista vaihe 3 – Etäisyys tarkistetusta keskiarvosta
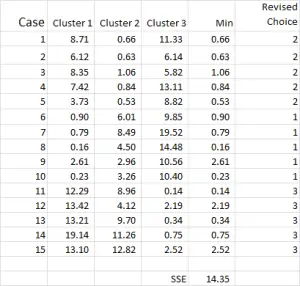
Kuva 7
klusterianalyysiprosessissa toistellaan nyt vaiheita 4 ja 5 (iteraatioita), kunnes klusterit vakiintuvat.
joka kerta käytetään tarkistettua keskiarvoa jokaiselle klusterille. Siksi Kuvassa 7 esitetään toinen iteraatiomme – mutta tällä kertaa käytämme kuvan 6 alareunassa syntyneitä keinoja (Kuvan 1 alkupisteiden sijaan).
voitte nyt havaita, että klusterin soveltamisessa on tapahtunut pieni muutos, ja tapaus 9 – yksi lähtökohdistamme – on jaettu uudelleen.
voit myös nähdä neliövirheen (SSE) summan laskettuna alareunassa – joka on jokaisen vähimmäisetäisyyden summa. Tavoitteenamme on nyt toistaa vaiheet 4 ja 5, kunnes SSE osoittaa vain vähäistä parannusta ja/tai klusterin allokoinnin muutokset ovat vähäisiä jokaisessa iteraatiossa.
lopullinen vaihe-kaavio ja yhteenveto klustereista
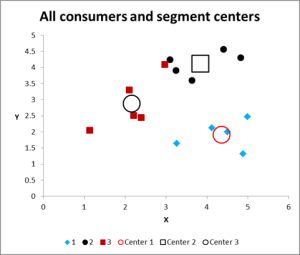
Kuva 8
kun käynnissä useita iteraatioita, meillä on nyt lähtö graafi ja yhteenveto tiedot.
tässä on tämän klusterianalyysin Excel-esimerkin tulostuskäyrä.
kuten näette, on esitetty kolme erillistä klusteria, sekä kunkin klusterin centroidit (keskiarvo) – suuremmat symbolit.
voimme tarvittaessa esittää nämä tiedot myös taulukkomuodossa, sillä olemme selvittäneet ne Excelissä.
Katso tapaus klusterissa 3 – pieni punainen neliö aivan mustan pisteen vieressä graafin ylimmässä keskellä. Tämä asia istuu siellä, koska vaikutus kolmannen muuttujan, joka ei ole esitetty tämän kahden muuttujan kaavio.