äskettäin Cassandra indeksointiin on tehty Uusi muutosehdotus, joka pyrkii vähentämään käytettävyyden ja vakauden välistä kauppaa: tekee WHERE-lausekkeesta paljon kiinnostavamman ja hyödyllisemmän loppukäyttäjille. Tämä uusi menetelmä on nimeltään Storage-Attached Indexing (SAI). Se ei ole mikään hätkähdyttävä nimi, mutta mitä odotit? Insinöörit eivät ole tunnettuja asioiden nimeämisestä, mutta cool-teknologia ei ole koskaan vitsi. SAI on vanginnut Cassandra-yhteisön huomion, mutta miksi? Datan indeksointi ei ole uusi käsite tietokantamaailmassa.
se, miten indeksoimme tietomme, voi muuttua ajan myötä haluttujen käyttötapausten ja käyttöönottomallien perusteella. Cassandra rakennettiin yhdistämällä näkökohtia Dynamo ja iso pöytä vähentää monimutkaisuutta lukea ja kirjoittaa yläpuolella pitämällä asiat yksinkertaisina. Monimutkaisuus Cassandra on enimmäkseen varattu sen hajautettu luonne ja sen seurauksena, luonut tradeoff kehittäjille. Jos haluat Cassandran uskomattoman mittakaavan, sinun täytyy käyttää aikaa tietomallin opetteluun. Tietokantaindeksit on tarkoitettu parantamaan tietomalliasi ja tekemään kyselyistäsi tehokkaampia. Cassandralle ne ovat olleet olemassa jossain muodossa projektin alkuajoista lähtien. Valitettava tosiasia on, että ne eivät ole vastanneet hyvin käyttäjien vaatimuksia. Kaikki käyttö indeksointi tulee pitkä luettelo tradeoffs ja varoituksia siihen pisteeseen, että ne ovat enimmäkseen välttää ja joillekin, vain kova ei. Tämän seurauksena käyttäjät ovat oppineet tietomallin peruskyselyillä parhaan suorituskyvyn saamiseksi.
nuo päivät saattavat olla jäämässä taakse ja SAI: n kaltaiset ominaisuudet auttavat meitä pääsemään sinne.
hajautettujen tietokantojen toissijaiset indeksit
kaikki indeksit eivät ole tasavertaisia. Primaariset indeksit tunnetaan myös nimellä unique key, tai Cassandran sanastossa partition key. Ensisijaisena käyttömenetelmänä tietokannassa Cassandra käyttää osionavainta tunnistaakseen solmun, jossa tiedot ovat, sitten datatiedoston, joka tallentaa datan osion. Cassandran ensisijainen hakemisto on melko yksinkertainen, mutta tämän artikkelin soveltamisalan ulkopuolella. Voit lukea niistä lisää täältä.
toissijaiset indeksit luovat täysin erilaisen ja ainutlaatuisen haasteen hajautettuun tietokantaan. Tarkastellaanpa esimerkkitaulukkoa ja tehdään muutamia huomioita:
luo taulun käyttäjät (
id pitkä,
etunimen teksti,
sukunimen teksti,
maateksti,
luotu aikaleima,
PRIMARY KEY (id)
);
primary index lookup olisi melko yksinkertainen näin:
valitse etunimi, sukunimi käyttäjistä, joissa id = 100;
mitä jos haluaisin löytää kaikki Ranskassa? Koska joku tuntee SQL, voit odottaa tämän kyselyn toimivan:
valitse etunimi, sukunimi käyttäjistä, joissa maa = ”FR”;
luomatta toissijaista indeksiä cassandraan, tämä kysely epäonnistuu. Cassandran perustava pääsykuvio on osionavaimella. Jakamattomassa tietokannassa, kuten perinteisessä RDBMS: ssä, taulukon jokainen sarake on helposti näkyvissä järjestelmälle. Voit silti käyttää saraketta, vaikka indeksiä ei olisikaan, koska ne kaikki ovat samassa järjestelmässä ja tiedostoissa. Tässä tapauksessa indeksit auttavat lyhentämään kyselyaikaa tekemällä haun tehokkaammaksi.
Cassandran kaltaisessa hajautetussa järjestelmässä sarakearvot ovat jokaisella datasolmulla ja ne on sisällytettävä kyselysuunnitelmaan. Tämä asettaa niin sanotun Scatter-Gather-skenaarion, jossa kysely lähetetään jokaiseen solmuun, tiedot kerätään, yhdistetään ja palautetaan käyttäjälle. Vaikka tämä operaatio voidaan tehdä useita solmuja kerralla, latenssin hallinta on alas, kuinka nopeasti solmu voi löytää sarakkeen arvo.
Nopea katsaus Cassandra dataan kirjoittaa
saatat ajatella, että indeksien lisäämisessä on kyse datan lukemisesta, mikä on varmasti päätavoite. Tietokantaa rakennettaessa indeksoinnin tekniset haasteet ovat kuitenkin puolueellisia siinä vaiheessa, kun tietoja kirjoitetaan. Tietojen hyväksyminen nopeimmalla nopeudella ja indeksien muotoilu optimaalisessa muodossa lukemiseen on valtava haaste. Kannattaa tehdä nopea katsaus siihen, miten tiedot kirjoitetaan Cassanda-tietokantaan yksittäisen solmun tasolla. Katso seuraava kaavio selitän, miten se toimii.
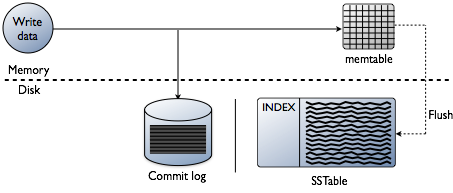
kun data esitetään solmulle, jota kutsumme mutaatioksi, Cassandran kirjoituspolku on hyvin yksinkertainen ja optimoitu kyseiseen operaatioon. Tämä pätee myös moniin muihin Log-Structured Merge(LSM) – puihin perustuviin tietokantoihin.
- Validointitiedot ovat oikeassa muodossa. Tyyppi tarkistaa skeema.
- kirjoita tiedot toimituslokin häntään. Ei etsintää, vain seuraava kohta tiedostoosoittimessa.
- kirjoita tiedot memtable, joka on vain hashmap skeema muistissa.
tehty! Mutaatio tunnustetaan, kun nuo asiat tapahtuvat. Rakastan kuinka yksinkertainen tämä on verrattuna muihin tietokantoihin, jotka vaativat lukitusta ja pyrkivät suorittamaan kirjoituksen.
myöhemmin, kun memtables täyttää fyysisen muistin, huuhteluprosessi kirjoittaa segmenttejä yhdellä syötöllä levylle tiedostoon nimeltä SSTable (lajiteltu Merkkijonotaulukko). Mukana oleva toimitusloki poistetaan nyt, kun pysyvyys on siirtynyt Sstableen. Tämä prosessi toistuu jatkuvasti, kun data kirjoitetaan solmuun.
tärkeä yksityiskohta: vakiot ovat muuttumattomia. Kun ne on kirjoitettu, niitä ei koskaan päivitetä, ne vain korvataan. Lopulta, kun enemmän tietoa on kirjoitettu, tausta prosessi nimeltään tiivistys sulautuu ja lajittelee sstables uusiin, jotka ovat myös muuttumattomia. On olemassa paljon tiivistysjärjestelmiä, mutta pohjimmiltaan ne kaikki suorittavat tämän toiminnon.
Cassandralla on nyt sen verran peruspohjaa, että indeksien kanssa saadaan tarpeeksi nörttiä. Kaikki syvempi informaatio jää lukijalle harjoitukseksi.
Issues with previous indexing
Cassandra has been two previous secondary indexing implementations. Varastointi liitteenä toissijainen indeksointi (SASI) ja toissijainen indeksit, joita kutsumme 2i. jälleen, minun pointtini siitä, että insinöörit eivät ole räikeä nimiä pätee täällä. Toissijaiset indeksit ovat olleet osa Cassandraa alusta alkaen, mutta toteutukset ovat tehneet niistä hankalia loppukäyttäjille pitkällä kauppalistallaan. Kaksi tärkeintä huolenaihetta, joita olemme jatkuvasti käsitelleet projektina, ovat kirjoitusvahvistus ja levyn indeksikoko. Tämän seurauksena ne voivat olla turhauttavan houkuttelevia uusille käyttäjille vain, jos ne epäonnistuvat myöhemmin käyttöönotossa. Katsotaan jokaista.
Secondary Indexes (2i) – tämä projektin alkuperäinen työ alkoi kätevänä ominaisuutena varhaisille Säästäväisyystietomalleille. Myöhemmin, kun Cassandran kyselykieli korvasi Thriftin Cassandran ensisijaisena kyselytapana, 2i-toiminnallisuus säilytettiin ”CREATE INDEX” – syntaksilla. Jos olisit tullut SQL, tämä oli todella helppo tapa oppia laki tahattomia seurauksia. Aivan kuten SQL indeksointi, enemmän lisäät enemmän vaikutat kirjoittaa suorituskykyä. Cassandran kohdalla tämä kuitenkin laukaisi suuremman ongelman kirjoitusvahvistuksella. Viitaten kirjoituspolku edellä, toissijaiset indeksit lisätty uusi askel polulle. Kun mutaatio indeksoidussa sarakkeessa tapahtuu, käynnistetään indeksointioperaatio, joka indeksoi TIEDOT uudelleen erilliseen indeksitiedostoon. Enemmän indeksit taulukossa voi dramaattisesti lisätä levyn toimintaa yhden rivin kirjoittaa toimintaa. Kun solmu ottaa suuren määrän mutaatioita, tuloksena voi olla kylläinen levyaktiivisuus, joka voi tehdä yksittäisistä solmuista epävakaita, antaen 2i: lle ansaittua ohjausta ”käytä säästeliäästi.”Indeksin koko on melko lineaarinen tässä toteutuksessa, mutta uudelleenindeksoinnin myötä tarvittavan levytilan määrää voi olla vaikea suunnitella aktiivisessa klusterissa.
Storage Attached Secondary Indexing (SASI) – SASI oli alun perin Applen pienen tiimin suunnittelema ratkaisu tiettyyn kyselyongelmaan eikä toissijaisten indeksien yleiseen ongelmaan. Ollakseni reilu sitä joukkuetta kohtaan, se pääsi heiltä karkuun käyttöjutussa, jota ei ollut suunniteltu ratkaisemaan. Tervetuloa avoimen lähdekoodin kaikille. Kaksi kyselytyyppiä, joita SASI oli suunniteltu käsittelemään:
- rivien löytäminen osittaisen tietojen täsmäämisen perusteella. Jokerimerkki, tai kuten kyselyt.
- harvakseltaan kerättyjä tietoja koskevat Kantamatkakyselyt, erityisesti aikaleimat. Kuinka monta kirjaa mahtuu aikavälin tyyppi kyselyt.
se suoriutui kummastakin operaatiosta melko hyvin ja käsitteli myös kirjoitusvahvistusta legacy 2i: llä. koska mutaatiot esitetään Cassandra-solmulle, data indeksoidaan muistiin ensimmäisen kirjoituksen aikana, aivan kuten memtablesia käytetään. Permutaatiossa ei vaadita levyn aktiivisuutta. Valtava parannus klustereita paljon kirjoittaa toimintaa. Kun memtables huuhdellaan sstables, vastaava indeksi tiedot huuhdellaan. Jokainen indeksitiedosto kirjoitettu on muuttumaton ja liitetty sstable, joten nimi varastointi liitteenä. Kun tiivistys tapahtuu, data kirjoitetaan uuteen tiedostoon, kun luodaan uusia sstables-tiedostoja. Levyn toiminnan kannalta tämä oli merkittävä parannus. Sasin varjopuoli oli ennen kaikkea luotujen indeksien koossa. Levyn indeksiformaatti aiheutti valtavan määrän levytilaa, jota käytettiin jokaiseen indeksoituun sarakkeeseen. Tämä tekee niistä operaattoreille erittäin vaikeita hallita. Lisäksi SASI leimattiin kokeelliseksi, eikä ominaisuuksien parantamisen suhteen ole tapahtunut juuri mitään. Monista bugeista on aikojen saatossa löytynyt kalliita korjauksia, jotka ovat herättäneet keskustelua siitä, pitäisikö SASI poistaa kokonaan. Jos tarvitset syvin sukellus tämän ominaisuuden, Duy Hai Doan teki hämmästyttävää työtä murtaa miten SASI toimii.
mikä tekee SAI: sta paremman
ensimmäisen, parhaan vastauksen tähän kysymykseen on se, että SAI on luonteeltaan evolutiivinen. Datastaxin insinöörit ymmärsivät, että toissijaisen indeksoinnin ydinarkkitehtuuria piti käsitellä alusta asti, mutta aiemmista toteutuksista on saatu hyviä kokemuksia. Käsitellään kysymyksiä kirjoitus-vahvistus ja indeksitiedoston kokoa samalla luoda polku parempia kyselyn parannuksia Cassandra on ollut ensisijainen tehtävä. Miten SAI käsittelee näitä molempia aiheita?
Kirjoita vahvistus — kuten Sasi opetti, muistin indeksointi ja flushing indeksit SSTables oli oikea tapa pysyä linjassa miten Cassandra kirjoittaa-polku toimii, samalla kun lisätään uusia toimintoja. SAI: lla, kun mutaatio on tunnustettu eli täysin sitoutunut, tiedot indeksoidaan. Optimoinnit ja paljon testausta, vaikutus kirjoittaa suorituskykyä on huomattavasti parantunut. Sinun pitäisi nähdä parempi kuin 40% lisäys läpimeno ja yli 200% parempi kirjoittaa latenssit yli 2i. tästä huolimatta, sinun pitäisi silti suunnitella kasvua 2x latenssi ja läpimeno indeksoitu taulukoita verrattuna ei-indeksoitu taulukoita. Duy Hai Doania lainatakseni: ”ei ole taikuutta, vain hyvää insinööritaitoa.
Indeksikoko – tämä on dramaattisin parannus ja luultavasti siellä, missä suurin osa työstä on tehty. Jos seuraat tietokannan sisäosien maailmaa, tiedät, että Tietojen tallennus on edelleen vilkas kenttä, joka on täynnä jatkuvasti kehittyviä parannuksia. SAI käyttää kahta erityyppistä indeksointijärjestelmää, jotka perustuvat tietotyyppiin.
- tekstin Käänteishakemistot luodaan termeillä, jotka on murrettu sanakirjaan. Suurin parannus on käytöstä Trie perustuva indeksointi, joka tarjoaa paljon parempi pakkaus, joka tarkoittaa pienempiä indeksikokoja.
- numeerinen-käyttäen lucenesta otettua tietorakennetta nimeltä block kd-trees, joka tarjoaa erinomaisen kantaman kyselytehon. Erillinen rivi ID-luetteloa ylläpidetään optimoida token order kyselyt.
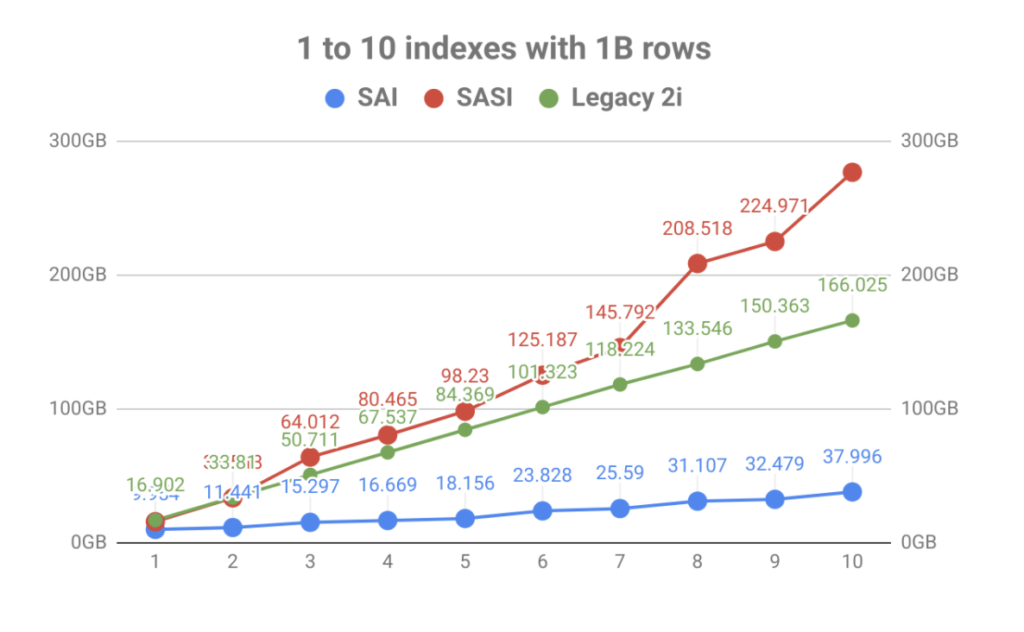
indeksien tallennusta painottaen tuloksena oli massiivinen volyymin parannus verrattuna taulukkoindeksien määrään. Kuten alla olevasta graafista näkyy, Sasin tuoma nopea indeksointi jäi nopeasti levynkäytön räjähdysmäisen kasvun varjoon. Se ei ainoastaan tee operatiivisesta suunnittelusta tuskaa, vaan indeksitiedostot oli luettava tiivistystapahtumien aikana, jotka saattoivat kyllästää levyjä, jotka johtivat solmujen suorituskykyyn liittyviin ongelmiin.
kirjoitusvahvistuksen ja indeksin koon ulkopuolella SAI: n sisäinen arkkitehtuuri mahdollistaa laajennuksen ja lisätoiminnot tulevaisuudessa. Tämä on linjassa projektin tavoitteiden kanssa olla modulaarisempi tulevissa rakennuksissa. Katsokaa joitakin muita CEPs, jotka ovat vireillä ja näet, että tämä on vasta alkua.
mihin SAI jatkaa tästä?
DataStax on tarjonnut SAI: ta Apache Cassandra-projektille Cassandran parannusprosessin kautta nimellä CEP-7. Keskustelu on nyt sisällyttämistä 4.Cassandran X-haara.
jos haluat kokeilla tätä nyt ennen kuin se on osa Apache Cassandra-projektia, meillä on sinulle pari paikkaa. Operaattoreille tai ihmisille, jotka haluavat hieman enemmän teknisiä käytännön, voit ladata uusimman DataStax Enterprise 6.8. Jos olet Kehittäjä, SAI on nyt käytössä DataStax Astra, meidän Cassandra palveluna. Voit luoda ilmaiseksi ikuisesti tason leikkiä syntaksin ja uuden missä lauseke toiminnallisuutta. Sen avulla, oppia käyttämään tätä ominaisuutta menemällä Cassandra indeksointi taitoja sivu ja mukana dokumentaatio.