Wat is de clusteranalyse?
clusteranalyse is een verkennende analyse die probeert structuren binnen de gegevens te identificeren. Clusteranalyse wordt ook wel segmentatieanalyse of taxonomieanalyse genoemd. Meer in het bijzonder wordt getracht homogene groepen van gevallen te identificeren indien de groepering niet eerder bekend is. Omdat het verkennend is, maakt het geen onderscheid tussen afhankelijke en onafhankelijke variabelen. De verschillende clusteranalysemethoden die SPSS aanbiedt kunnen binaire, nominale, ordinale, en schaal (interval of Verhouding) gegevens behandelen.
clusteranalyse wordt vaak gebruikt in combinatie met andere analyses (zoals discriminantanalyse). De onderzoeker moet in staat zijn om de clusteranalyse te interpreteren op basis van hun begrip van de gegevens om te bepalen of de resultaten die door de analyse worden geproduceerd daadwerkelijk zinvol zijn.
typische onderzoeksvragen de antwoorden op de clusteranalyse zijn als volgt:
- geneeskunde-wat zijn de diagnostische clusters? Om deze vraag te beantwoorden zou de onderzoeker een diagnostische vragenlijst die mogelijke symptomen (bijvoorbeeld in de psychologie, angst, depressie enz.). De clusteranalyse kan dan groepen patiënten identificeren die gelijkaardige symptomen hebben.
- Marketing-wat zijn de klantensegmenten? Om deze vraag te beantwoorden kan een marktonderzoeker een enquête uitvoeren over behoeften, attitudes, demografie en gedrag van klanten. De onderzoeker kan dan clusteranalyse gebruiken om homogene groepen klanten te identificeren die vergelijkbare behoeften en attitudes hebben.
- onderwijs – wat zijn studentengroepen die speciale aandacht nodig hebben? Onderzoekers kunnen psychologische, geschiktheid en prestatiekenmerken meten. Een clusteranalyse kan dan identificeren welke homogene groepen Er bestaan onder studenten (bijvoorbeeld hoog presterende in alle vakken, of studenten die uitblinken in bepaalde vakken, maar falen in andere).Biologie-Wat is de taxonomie van soorten? Onderzoekers kunnen een dataset van verschillende planten verzamelen en verschillende attributen van hun fenotypen noteren. Een clusteranalyse kan deze waarnemingen groeperen in een reeks clusters en helpen bij het opbouwen van een taxonomie van groepen en subgroepen van soortgelijke planten.
andere technieken die u zou willen proberen om soortgelijke groepen waarnemingen te identificeren zijn Q-analyse, multi-dimensionale schaling (MDS) en latente klassenanalyse.
de clusteranalyse in SPSS
onze onderzoeksvraag voor dit voorbeeld clusteranalyse is als volgt:
welke homogene clusters van studenten ontstaan op basis van gestandaardiseerde testscores in wiskunde, lezen en schrijven?
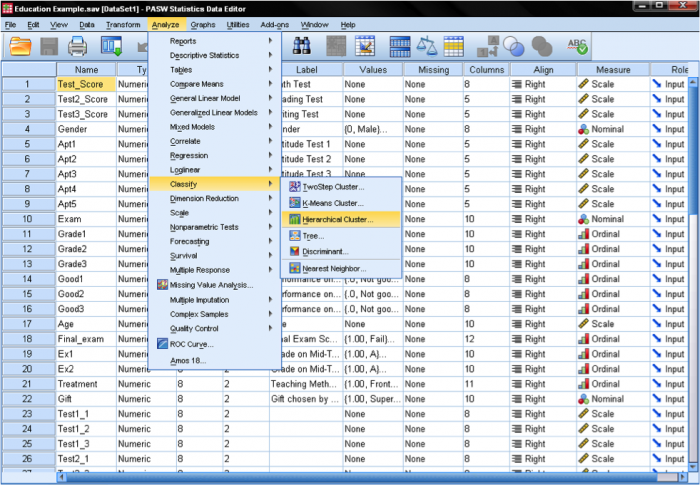
in SPSS-Clusteranalyses kan worden gevonden in analyseren/classificeren…. SPSS biedt drie methoden voor de clusteranalyse: K-betekent Cluster, hiërarchische Cluster, en twee-stap Cluster.
K – Means cluster is een methode om snel grote datasets te clusters. De onderzoeker bepaalt vooraf het aantal clusters. Dit is nuttig om verschillende modellen met een ander aangenomen aantal clusters te testen.
hiërarchische cluster is de meest gebruikte methode. Het genereert een reeks modellen met clusteroplossingen van 1 (alle gevallen in één cluster) tot n (elk geval is een individueel cluster). Hiërarchische cluster werkt ook met variabelen in tegenstelling tot gevallen; het kan variabelen samen cluster op een manier enigszins vergelijkbaar met factoranalyse. Bovendien kan hiërarchische clusteranalyse nominale, ordinale en schaalgegevens verwerken; het wordt echter niet aanbevolen om verschillende meetniveaus te mengen.
tweestaps clusteranalyse identificeert groepen door eerst pre-clustering uit te voeren en vervolgens door hiërarchische methoden uit te voeren. Omdat het vooraf een snel clusteralgoritme gebruikt, kan het grote datasets verwerken die lang zouden duren om met hiërarchische clustermethoden te berekenen. In dit opzicht is het een combinatie van de twee voorgaande benaderingen. Twee-staps clustering kan schaal-en ordinale gegevens verwerken in hetzelfde model, en het selecteert automatisch het aantal clusters.
de hiërarchische clusteranalyse volgt drie basisstappen: 1) Bereken de afstanden, 2) Verbind de clusters, en 3) Kies een oplossing door het juiste aantal clusters te selecteren.
eerst moeten we de variabelen selecteren waarop we onze clusters baseren. In het dialoogvenster voegen we de wiskunde, lezen en schrijven testen toe aan de lijst met variabelen. Omdat we gevallen willen groeperen, laten we de rest van de vinkjes op de standaard staan.
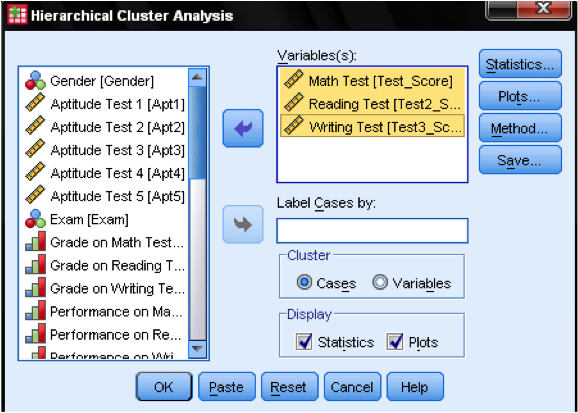
in het dialoogvenster statistieken … kunnen we aangeven of we de nabijheidsmatrix willen uitvoeren (dit zijn de afstanden berekend in de eerste stap van de analyse) en het voorspelde clusterlidmaatschap van de cases in onze waarnemingen. Nogmaals, we laten alle instellingen op standaard.

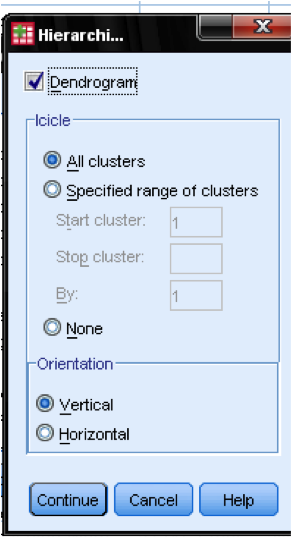
in het dialoogvenster Plots … moeten we het Dendrogram toevoegen. Het Dendrogram zal grafisch laten zien hoe de clusters worden samengevoegd en stelt ons in staat om te bepalen wat het juiste aantal clusters is.
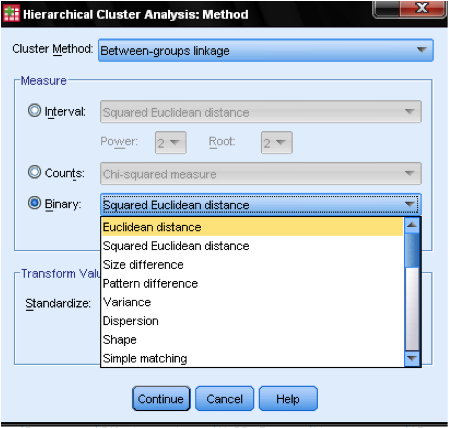
de dialoogvenster methode … stelt ons in staat om de afstandsmeting en de clustering methode te specificeren. Eerst moeten we de juiste afstandsmaat definiëren. SPSS biedt drie grote blokken afstandsmetingen voor interval (schaal), tellingen (ordinaal) en binaire (nominale) gegevens.
voor intervalgegevens is de meest voorkomende vierkante Euclidische afstand. Het is gebaseerd op de Euclidische afstand tussen twee waarnemingen, die de vierkantswortel is van de som van de kwadraatafstanden. Omdat de Euclidische Afstand in het kwadraat is, neemt het belang van grote afstanden toe, terwijl het belang van kleine afstanden afneemt.

als we ordinale gegevens (tellingen) hebben kunnen we kiezen tussen Chi-kwadraat of een gestandaardiseerd Chi-kwadraat genaamd Phi-kwadraat. Voor binaire gegevens wordt gewoonlijk de kwadraat-Euclidische afstand gebruikt.

in ons voorbeeld kiezen we Interval en vierkante Euclidische afstand.
vervolgens moeten we de Clustermethode kiezen. Typisch, keuzes zijn tussen-groepen koppeling (afstand tussen clusters is de gemiddelde afstand van alle datapunten binnen deze clusters), dichtstbijzijnde buur (enkele koppeling: afstand tussen clusters is de kleinste afstand tussen twee datapunten), verste buur (volledige koppeling: afstand is de grootste afstand tussen twee datapunten), en Ward ‘ s methode (afstand is de afstand van alle clusters tot het grote gemiddelde van de steekproef). Single linkage werkt het beste met lange ketens van clusters, terwijl complete linkage het beste werkt met dichte blobs van clusters. Koppeling tussen groepen werkt met beide clustertypen. Het wordt aanbevolen om eerst een enkele koppeling te gebruiken. Hoewel een enkele koppeling de neiging heeft clusters te creëren, helpt het bij het identificeren van uitschieters. Na het uitsluiten van deze uitschieters, kunnen we verder gaan met Wards methode. Ward ‘ s methode gebruikt de F-waarde (zoals in ANOVA) om de significantie van verschillen tussen clusters te maximaliseren.
een laatste overweging is standaardisatie. Als de variabelen verschillende schalen en middelen hebben, willen we misschien standaardiseren naar Z-scores of door de schaal te centreren. We kunnen de waarden ook omzetten in absolute waarden als we een dataset hebben waar dit passend zou kunnen zijn.