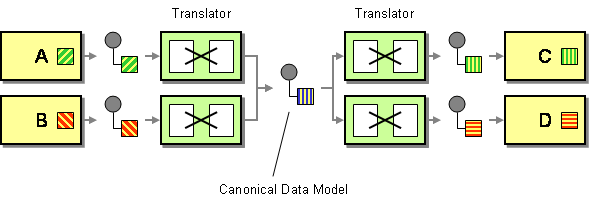
een canoniek datamodel wordt gedefinieerd in de Enterprise Integration Patterns als de oplossing om afhankelijkheden te minimaliseren bij het integreren van toepassingen die verschillende dataformaten gebruiken. Met andere woorden, een component (een applicatie of een dienst) moet communiceren met een andere component via een dataformaat dat onafhankelijk is van beide dataformaten.
twee dingen om hier te benadrukken. Eerst definieerde ik een component als een applicatie of een service omdat dergelijke modellen worden/werden gebruikt in de context van applicatie integratie en service oriëntatie. Ten tweede hebben we het hier over een concept dat uitsluitend als transportgegevensformaat moet worden gebruikt. U moet geen canonieke dataformaat gebruiken als de interne structuur van uw gegevensopslag.
theoretisch zijn de voordelen vrij duidelijk. Een canoniek dataformaat vermindert de koppeling tussen applicaties, vermindert het aantal te ontwikkelen vertalingen voor de integratie van een reeks componenten, enz. Best interessant toch? Eén enkel datamodel is begrijpelijk voor het hele IT-landschap en een aantal mensen (ontwikkelaars, systeemanalisten, zakelijke stakeholders, enz.) die dezelfde visie op een bepaald concept kunnen delen.
in de praktijk is de toepassing van dergelijke modellen echter zelden efficiënt.
een persoon is niet hetzelfde concept voor de marketing-en ondersteuningsafdeling van een verzekeringsmaatschappij. Een vlucht voor een luchtverkeersbeveiligingssysteem heeft een andere betekenis, afhankelijk van of deze door een piloot is gevuld of dat het een doorlopende vlucht is bovenop uw luchtruim. Een PLM-onderdeel heeft een compleet andere weergave, afhankelijk van of het net is ontworpen of moet worden onderhouden door een ondersteuningsteam.
in de meeste contexten resulteert het ontwerpen van een canoniek datamodel in een groot datamodel met een volledige set optionele attributen en zeer weinig verplichte attributen (zoals de identifiers). Hoewel het in de eerste plaats is ontworpen om de integratie van componenten te vergemakkelijken, zult u het alleen maar compliceren. In de tussentijd zal uw model veel frustratie veroorzaken onder de gebruikers vanwege de inherente complexiteit (in termen van gebruik en beheer). Bovendien, met betrekking tot de koppeling kwestie, je bent gewoon het verplaatsen van het ergens anders. In plaats van te worden gekoppeld aan een component data formaat, wordt u strak gekoppeld aan een gemeenschappelijke data formaat dat zal worden gebruikt door het hele IT-landschap en onderhevig aan zeer frequente veranderingen.
In een notendop moet in de meeste contexten een canoniek gegevensmodel worden beschouwd als een anti-patroon. Wat is de andere optie dan overwegen dat u nog steeds de afhankelijkheden tussen twee componenten die gegevens uitwisselen wilt minimaliseren?
Domain Driven Design (DDD) beveelt de invoering van het concept van begrensde context aan. Een begrensde context is gewoon een expliciete context waarin een model van toepassing is met duidelijke grenzen met andere begrensde contexten. Afhankelijk van uw organisatie kan een begrensde context verwijzen naar een functioneel domein waarin een object wordt gebruikt, het kan verwijzen naar de objectstatus zelf, enz.
in dat geval zou het canonieke gegevensmodel als zodanig gewoon het gele deel in het volgende diagram zijn:
het snijpunt van A, B en C vertegenwoordigt de verzameling attributen die er moeten zijn ongeacht de context (in principe de verplichte attributen van de vorige grote CDM). Dit deel moet nog steeds zorgvuldig worden ontworpen vanwege zijn centrale rol. Toch is het belangrijk om pragmatisch te blijven. Als het in jouw context niet zinvol is om zo ‘ n gemeenschappelijk model te hebben, moet je het gewoon weggooien.
wat ook belangrijk is, is een snijpunt tussen twee contexten (A en B, B en C, C en A). Hoe een objectweergave van de ene context naar de andere toe te wijzen? Wat zijn de expliciete attributen die over twee contexten moeten worden gedeeld? Wat zijn de gemeenschappelijke zakelijke beperkingen tussen twee contexten? Deze vragen moeten nog steeds worden beantwoord door een transversaal team, maar vanuit een zakelijk perspectief, is het zinvol om ze te verhogen. Dat was niet altijd het geval met een enkele CDM gedeeld over potentieel tegengestelde contexten.
wat de delen betreft die niet worden gedeeld met andere contexten (in het wit), mag het geen deel uitmaken van een ondernemingsgegevensmodel. Je moet pragmatisch zijn. Bijvoorbeeld, als een subset specifiek is voor een bepaald domein, moet het aan de domeinexperts zijn om het zelf te modelleren.
een belangrijke uitdaging is echter om die begrensde contexten te identificeren en het zou de moeite waard zijn hier de wet van Conway aan te herinneren:
elke organisatie die een systeem ontwerpt zal onvermijdelijk een ontwerp produceren waarvan de structuur een kopie is van de communicatiestructuur van de organisatie.
de begrensde contexten moeten niet noodzakelijk worden toegewezen aan de huidige organisatie. Een begrensde context kan bijvoorbeeld meerdere afdelingen omvatten. Het doorbreken van organisatorische silo ‘ s zou voor de meeste bedrijven nog steeds een doelstelling moeten zijn.
daarnaast introduceert DDD het concept Anti-Corruption Layer (ACL). Dit patroon kan verwijzen naar een oplossing voor een legacy migratie (door de invoering van een tussenlaag tussen het oude en het nieuwe systeem om problemen met de gegevenskwaliteit te voorkomen, enz.). Maar in onze context als we praten over corruptie is het gerelateerd aan datamodellering schuld die je kunt introduceren om kortetermijnproblemen op te lossen.
neem het voorbeeld van twee systemen die verantwoordelijk zijn voor het beheer van een bepaalde toestand van een PLM-onderdeel (een onderdeel is een fysiek item dat wordt geproduceerd of gekocht en vervolgens wordt geassembleerd als bijvoorbeeld een helikopterrotor). Eén legacy-systeem (laten we het SystemA noemen) is verantwoordelijk voor het beheer van de ontwerpfase en u moet een nieuw systeem (laten we het SystemZ noemen) implementeren dat verantwoordelijk is voor het beheer van de onderhoudsfase. Het hele it-toepassingslandschap deelt dezelfde common part identifier (partId) met uitzondering van SystemA die zich er niet van bewust is. In plaats van de partId beheert SystemA zijn eigen identifier, systemAId. Omdat SystemZ SystemA moet aanroepen met systemAId, zou het een heuristische optie kunnen zijn om systemAId te integreren als onderdeel van het SystemZ data model.
dit is een veel voorkomende fout die u moet vermijden. Je hebt gewoon je datamodel beschadigd vanwege een situatie op korte termijn.
het ACL-patroon had hier een oplossing kunnen zijn. SystemZ kon zijn eigen gegevensformaat hebben geïmplementeerd (zonder enige externe corruptie zoals de systemAId). Dan zou het tot een tussenlaag geweest zijn om de vertaling tussen de partId en de systemAId te beheren.
toegepast op ons onderwerp, dwingt het ACL-patroon een laag te implementeren tussen twee verschillende begrensde contexten. Een component is zich niet bewust van hoe een andere component te noemen die geen deel uitmaakt van zijn eigen begrensde context. In plaats daarvan is een component zich alleen bewust van hoe hij zijn eigen datastructuur kan toewijzen aan het dataformaat van de begrensde context waartoe hij behoort.
Dit is trouwens een vuistregel. Een component mag slechts tot één begrensde context behoren. Dit is ook de reden waarom DDD is een geweldige pasvorm voor microservices architectuur. Door de fijnkorrelige korreligheid is het gemakkelijker om aan deze regel te voldoen.
samenvattend kan worden gesteld dat een canoniek model als zodanig in de meeste gevallen als een anti-patroon moet worden beschouwd. Je moet proberen het begrensde contextconcept te implementeren dat één model per context betekent met expliciete grenzen tussen de contexten. Twee componenten die deel uitmaken van verschillende begrensde contexten moeten communiceren via een anti-corruptie laag om data modellering corruptie te voorkomen.