o que é a análise de aglomerado?
Cluster analysis is an exploratory analysis that tries to identify structures within the data. A análise de clusters também é chamada de análise de segmentação ou análise de taxonomia. Mais especificamente, tenta identificar grupos homogêneos de casos se o agrupamento não é conhecido anteriormente. Por ser exploratória, não faz qualquer distinção entre variáveis dependentes e independentes. Os diferentes métodos de análise de clusters que SPSS oferece podem lidar com dados binários, nominais, ordinais e escalas (intervalo ou razão).
a análise de Clusters é frequentemente utilizada em conjunto com outras análises (como a análise discriminante). O pesquisador deve ser capaz de interpretar a análise de cluster com base na sua compreensão dos dados para determinar se os resultados produzidos pela análise são realmente significativos.Perguntas de investigação típicas as respostas da análise de clusters são as seguintes::
- Medicina-quais são os clusters de diagnóstico? Para responder a esta pergunta, O pesquisador iria elaborar um questionário de diagnóstico que inclui possíveis sintomas (por exemplo, em Psicologia, ansiedade, depressão, etc.). A análise de cluster pode então identificar grupos de pacientes que têm sintomas semelhantes.
- Marketing-quais são os segmentos de clientes? Para responder a esta pergunta, um pesquisador de mercado pode realizar uma pesquisa cobrindo necessidades, atitudes, demografia e comportamento dos clientes. O pesquisador pode então usar a análise de cluster para identificar grupos homogêneos de clientes que têm necessidades e atitudes semelhantes.
- Educação-o que são os grupos de estudantes que precisam de atenção especial? Os pesquisadores podem medir as características psicológicas, de aptidão e de realização. Uma análise de cluster pode então identificar que grupos homogêneos existem entre os estudantes (por exemplo, grandes resultados em todas as disciplinas, ou estudantes que se destacam em certas disciplinas, mas falham em outras).Biologia-O que é a taxonomia das espécies? Os pesquisadores podem coletar um conjunto de dados de diferentes plantas e notar diferentes atributos de seus fenótipos. Uma análise de clusters pode agrupar essas observações em uma série de clusters e ajudar a construir uma taxonomia de grupos e subgrupos de plantas similares.
outras técnicas que você pode querer tentar, a fim de identificar grupos semelhantes de observações são a análise Q, escala multidimensional (MDS), e análise de classe latente.
the Cluster Analysis in SPSS
Our research question for this example cluster analysis is as follows:
What homogenous clusters of students emerge based on standardized test scores in mathematics, reading, and writing?
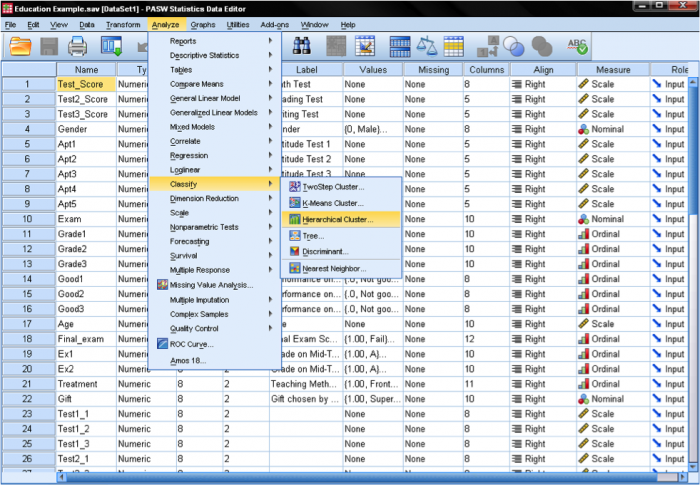
nas análises de agregados SPSS pode ser encontrado na análise/classificação… SPSS oferece três métodos para a análise de clusters: k-Means Cluster, Hierarchical Cluster, e Two-Step Cluster.
k-means cluster é um método para agrupar rapidamente grandes conjuntos de dados. O pesquisador define o número de clusters com antecedência. Isto é útil para testar diferentes modelos com um número assumido diferente de aglomerados.
cluster hierárquico é o método mais comum. Ele gera uma série de modelos com soluções de cluster de 1 (todos os casos em um cluster) A n (cada caso é um cluster individual). Cluster hierárquico também funciona com variáveis em oposição aos casos; ele pode agrupar variáveis em conjunto de uma maneira um pouco semelhante à análise de fatores. Além disso, a análise hierárquica de clusters pode lidar com dados nominais, ordinais e escalas; no entanto, não é recomendado misturar diferentes níveis de medição.
a análise de clusters em duas fases identifica os agrupamentos executando pré-clustering primeiro e, em seguida, executando métodos hierárquicos. Porque ele usa um algoritmo de cluster rápido à frente, ele pode lidar com grandes conjuntos de dados que levaria muito tempo para computar com métodos de cluster hierárquicos. A este respeito, trata-se de uma combinação das duas abordagens anteriores. O agrupamento de dois passos pode lidar com dados de escala e ordinais no mesmo modelo, e ele automaticamente seleciona o número de aglomerados.
a análise hierárquica de clusters segue três etapas básicas: 1) calcular as distâncias, 2) ligar os clusters, e 3) escolher uma solução selecionando o número certo de clusters.
primeiro, temos que selecionar as variáveis sobre as quais baseamos nossos aglomerados. Na janela de diálogo, adicionamos os testes de matemática, leitura e escrita à lista de variáveis. Como queremos agrupar casos, deixamos o resto das marcas no padrão.
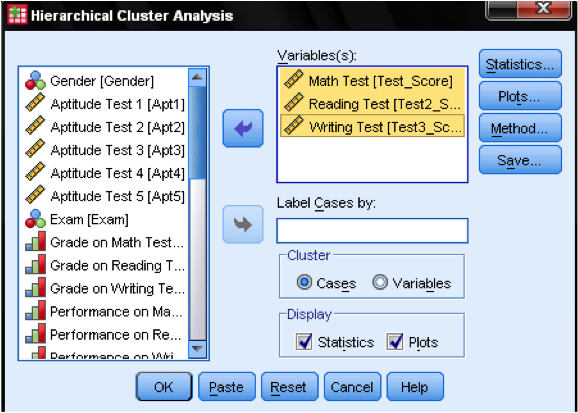
Na caixa de diálogo Estatísticas… nós podemos especificar se queremos saída da matriz de proximidade (estas são as distâncias calculadas no primeiro passo da análise) e o previsto membros do cluster dos casos, em nossas observações. Mais uma vez, deixamos todas as configurações em padrão.

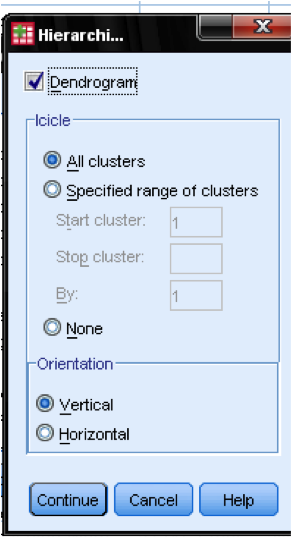
na caixa de diálogo, devemos adicionar o dendrograma. O dendrograma irá mostrar graficamente como os aglomerados são fundidos e nos permite identificar qual é o número apropriado de aglomerados.
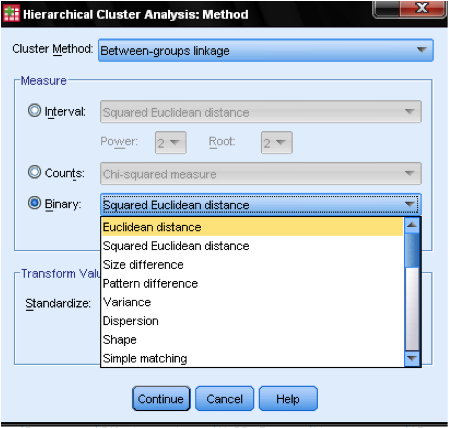
o método da caixa de diálogo… permite-nos indicar a medida da distância e o método de agrupamento. Em primeiro lugar, temos de definir a medida correcta da distância. SPSS oferece três grandes blocos de medidas de distância para intervalo (escala), contagens (ordinal) e dados binários (nominais).
para os dados do intervalo, a mais comum é a distância Euclidiana quadrada. É baseado na distância euclidiana entre duas observações, que é a raiz quadrada da soma das distâncias ao quadrado. Uma vez que a distância euclidiana é ao quadrado, aumenta a importância de grandes distâncias, enquanto enfraquece a importância de pequenas distâncias.

se tivermos dados ordinais (contagens) podemos selecionar entre Qui-quadrado ou um Qui-Quadrado padronizado chamado Phi-quadrado. Para dados binários, a distância Euclidiana ao quadrado é comumente usada.

no nosso exemplo, escolhemos intervalo e distância Euclidiana quadrada.
em seguida, temos que escolher o método de Cluster. Normalmente, as escolhas são entre-grupos de ligação (distância entre os grupos é a distância média de todos os pontos de dados dentro destes clusters), vizinho mais próximo (single linkage: distância entre os clusters é a menor distância entre dois pontos de dados), vizinho mais distante (ligação completa: a distância é a maior distância entre dois pontos de dados), e Ward (método é a distância de todos os clusters para a grande média da amostra). A ligação única funciona melhor com longas cadeias de aglomerados, enquanto a ligação completa funciona melhor com densas bolhas de aglomerados. A ligação entre grupos funciona com ambos os tipos de aglomerados. Recomenda-se a utilização de uma única ligação em primeiro lugar. Embora uma única ligação tende a criar cadeias de aglomerados, Ela ajuda na identificação de casos anómalos. Depois de excluir estes anómalos, podemos seguir o método do Ward. O método de Ward usa o valor F (como em ANOVA) para maximizar o significado das diferenças entre os clusters.
uma última consideração é a normalização. Se as variáveis têm escalas diferentes e meios nós podemos querer padronizar ou para z pontuações ou centrando a escala. Também podemos transformar os valores em valores absolutos se tivermos um conjunto de dados onde isso possa ser apropriado.