최적화는 프로그램 변환 기법으로,적은 리소스(예:중앙 처리 장치,메모리)를 소비하고 고속을 전달함으로써 코드를 개선하려고 시도합니다.
최적화에서 높은 수준의 일반 프로그래밍 구조는 매우 효율적인 낮은 수준의 프로그래밍 코드로 대체됩니다. 코드 최적화 프로세스는 아래 세 가지 규칙을 따라야 합니다:
-
출력 코드는 어떤 식 으로든 프로그램의 의미를 변경해서는 안됩니다.
-
최적화 프로그램의 속도 증가 해야 하 고 가능한 경우 프로그램 자원의 적은 수를 요구 한다.
-
최적화 자체가 빠르며 전체 컴파일 프로세스를 지연해서는 안됩니다.
최적화 된 코드에 대한 노력은 프로세스를 컴파일하는 다양한 수준에서 수행 될 수 있습니다.
-
처음에는 사용자가 코드를 변경/재정렬하거나 더 나은 알고리즘을 사용하여 코드를 작성할 수 있습니다.
-
중간 코드를 생성 한 후,컴파일러는 주소 계산 및 개선 루프에 의해 중간 코드를 수정할 수 있습니다.
-
대상 컴퓨터 코드를 생성하는 동안 컴파일러는 메모리 계층 구조 및 프로세서 레지스터를 사용할 수 있습니다.
최적화는 크게 두 가지 유형으로 분류할 수 있습니다.
기계 독립적 최적화
이 최적화에서 컴파일러는 중간 코드를 취하여 프로세서 레지스터 및/또는 절대 메모리 위치를 포함하지 않는 코드의 일부를 변환합니다. 예를 들어:
do{ item = 10; value = value + item; } while(valueThis code involves repeated assignment of the identifier item, which if we put this way:
Item = 10;do{ value = value + item; } while(valueshould not only save the CPU cycles, but can be used on any processor.
Machine-dependent Optimization
Machine-dependent optimization is done after the target code has been generated and when the code is transformed according to the target machine architecture. It involves CPU registers and may have absolute memory references rather than relative references. Machine-dependent optimizers put efforts to take maximum advantage of memory hierarchy.
Basic Blocks
Source codes generally have a number of instructions, which are always executed in sequence and are considered as the basic blocks of the code. These basic blocks do not have any jump statements among them, i.e., when the first instruction is executed, all the instructions in the same basic block will be executed in their sequence of appearance without losing the flow control of the program.
A program can have various constructs as basic blocks, like IF-THEN-ELSE, SWITCH-CASE conditional statements and loops such as DO-WHILE, FOR, and REPEAT-UNTIL, etc.
Basic block identification
We may use the following algorithm to find the basic blocks in a program:
-
기본 블록이 시작되는 모든 기본 블록의 검색 헤더 문:
- 프로그램의 첫 번째 진술.
- 모든 분기(조건부/무조건)의 대상인 문입니다.
- 지점 문을 따르는 문입니다.
-
헤더 문과 그 뒤에 오는 문은 기본 블록을 형성합니다.
-
기본 블록은 다른 기본 블록의 헤더 문을 포함하지 않습니다.
기본 블록은 코드 생성 및 최적화 관점에서 중요한 개념입니다.
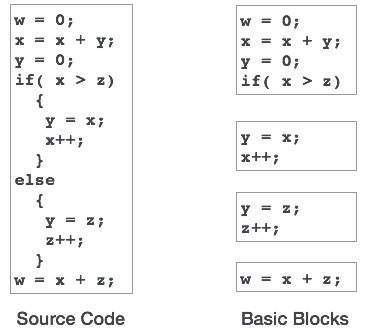
기본 블록은 단일 기본 블록에서 두 번 이상 사용되는 변수를 식별하는 데 중요한 역할을합니다. 변수가 두 번 이상 사용되는 경우 해당 변수에 할당 된 레지스터 메모리는 블록이 실행을 완료하지 않으면 비울 필요가 없습니다.
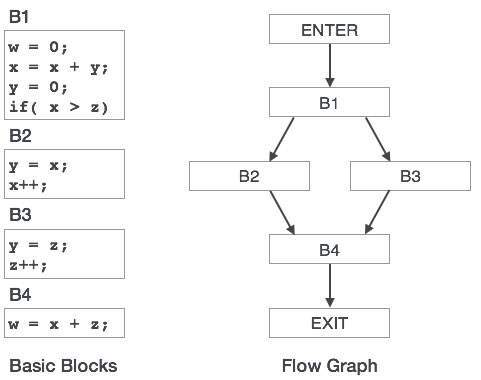
제어 흐름 그래프
프로그램의 기본 블록은 제어 흐름 그래프를 통해 나타낼 수 있습니다. 제어 흐름 그래프는 프로그램 제어가 블록 간에 전달되는 방식을 나타냅니다. 이 프로그램에 원치 않는 루프를 찾는 데 도움이하여 최적화에 도움이되는 유용한 도구입니다.
루프 최적화
대부분의 프로그램은 시스템에서 루프로 실행됩니다. 프로세서 사이클 및 메모리를 절약하기 위해 루프를 최적화 할 필요가 있습니다. 루프는 다음 기술로 최적화 할 수 있습니다:
-
불변 코드:루프에 상주하고 각 반복에서 동일한 값을 계산하는 코드 조각을 루프 불변 코드라고합니다. 이 코드는 각 반복이 아닌 한 번만 계산되도록 저장하여 루프 밖으로 이동할 수 있습니다.
-
유도 분석:그 값이 루프 불변 값에 의해 루프 내에서 변경되는 경우 변수는 유도 변수라고합니다.
-
강도 감소:더 많은 프로세서 사이클,시간 및 메모리를 소비하는 표현식이 있습니다. 이러한 식은 식의 출력을 손상시키지 않으면 서 더 저렴한 식으로 대체해야합니다. 예를 들어,곱셈(엑스*2)은(엑스)보다 프로세서 사이클 측면에서 비싸다
데드 코드 제거
데드 코드는 다음과 같은 하나 이상의 코드 문입니다:
- 실행되지 않았거나 연결할 수 없거나
- 또는 실행되면 출력이 사용되지 않습니다.
따라서 데드 코드는 프로그램 작동에서 아무런 역할을하지 않으므로 간단히 제거 할 수 있습니다.
부분적으로 죽은 코드
계산 된 값이 특정 상황에서만 사용되는 코드 문이 있습니다. 이러한 코드를 부분적으로 데드 코드라고합니다.
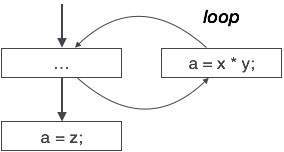
위의 제어 흐름 그래프는 변수’가’식의 출력을 할당하는 데 사용되는 프로그램의 덩어리를 보여줍니다. 우리가’에 할당 된 값이 루프 내에서 사용되지 않습니다 가정 해 봅시다.컨트롤이 루프를 떠난 직후,’에이’는 변수’지’의 값을 할당받습니다.이 값은 나중에 프로그램에서 사용됩니다. 우리는 여기서’에이’의 할당 코드는 어디에도 사용되지 않습니다 결론,따라서 제거 할 자격이.
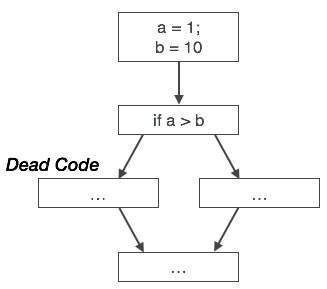
마찬가지로 위의 그림은 조건문이 항상 거짓임을 보여 주며,이는 실제로 작성된 코드가 실행되지 않으므로 제거 될 수 있음을 의미합니다.
부분 중복
중복 식은 피연산자의 변경 없이 병렬 경로에서 두 번 이상 계산됩니다.부분 중복 식은 피연산자를 변경하지 않고 경로에서 두 번 이상 계산됩니다. 예를 들어,
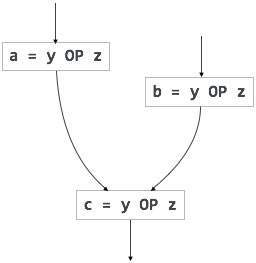
|
|
루프 불변 코드는 부분적으로 중복되며 코드 모션 기술을 사용하여 제거 할 수 있습니다.
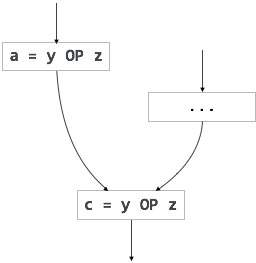
부분적으로 중복되는 코드의 또 다른 예는 다음과 같습니다:
If (condition){ a = y OP z;}else{ ...}c = y OP z;
우리는 피연산자의 값(와이 과 지)변수 할당에서 변경되지 않습니다 ㅏ 에 변수 씨.여기서 조건문이 참이면 와이 연산 지 두 번,그렇지 않으면 한 번 계산됩니다. 아래 그림과 같이 코드 모션을 사용하여 이 중복성을 제거할 수 있습니다:
If (condition){ ... tmp = y OP z; a = tmp; ...}else{ ... tmp = y OP z;}c = tmp;
여기서 조건이 참 또는 거짓인지 여부;와이 연산 지 한 번만 계산해야합니다.