クラスター分析とは何ですか?
クラスター分析は、データ内の構造を特定しようとする探索的分析です。 クラスター分析は、セグメンテーション分析またはタクソノミ分析とも呼ばれます。 より具体的には、グループ化が以前に知られていない場合、ケースの同種のグループを識別しようとします。 これは探索的であるため、従属変数と独立変数の区別はありません。 SPSSが提供するさまざまなクラスター分析方法では、バイナリ、ノミナル、順序、およびスケール(間隔または比率)データを処理できます。
クラスター分析は、他の分析(判別分析など)と組み合わせて使用されることがよくあります。 研究者は、分析によって生成された結果が実際に意味があるかどうかを判断するために、データの理解に基づいてクラスター分析を解釈できる必要が
典型的な研究質問クラスター分析の答えは次のとおりです:
- 医学-診断クラスターとは何ですか? この質問に答えるために、研究者は、可能性のある症状(例えば、心理学、不安、うつ病など)を含む診断アンケートを考案する。). クラスター分析は、同様の症状を有する患者のグループを識別することができます。
- マーケティング-顧客セグメントとは何ですか? この質問に答えるためには市場研究者は顧客の必要性、態度、人口統計、および行動をカバーする調査を行なうかもしれない。 研究者は、同様のニーズや態度を持っている顧客の均質なグループを識別するために、クラスタ分析を使用することができます。
- 教育–特別な注意を必要とする学生グループは何ですか? 研究者は、心理的、適性、および達成特性を測定することができます。 クラスター分析は、学生の間にどのような同質なグループが存在するかを識別することができます(たとえば、すべての科目で高い達成者、または特定の科目
- 生物学-種の分類学とは何ですか? 研究者は、異なる植物のデータセットを収集し、その表現型の異なる属性に注意することができます。 クラスター分析では、これらの観測値を一連のクラスターにグループ化し、類似する植物のグループとサブグループの分類法を構築するのに役立ちます。
同様の観測グループを識別するために試してみたい他の手法としては、Q解析、多次元スケーリング(MDS)、潜在クラス解析があります。
SPSSにおけるクラスター分析
この例のクラスター分析の研究課題は次のとおりです。
数学、読み書きの標準化されたテストスコアに基づいて、学生の均質なクラスターは何ですか?SPSSクラスター分析の
は、Analyze/Classify…にあります。 SPSSは、クラスター分析のための三つの方法を提供しています:K-Meansクラスター、階層クラスター、およびツーステップクラスター。
K-means clusterは、大きなデータセットを迅速にクラスター化する方法です。 研究者は、事前にクラスターの数を定義します。 これは、想定されるクラスター数が異なる異なるモデルをテストする場合に便利です。
階層クラスターが最も一般的な方法です。 これは、1(1つのクラスター内のすべてのケース)からn(各ケースは個別のクラスター)までのクラスターソリューションを持つ一連のモデルを生成します。 階層クラスターは、ケースとは対照的に、変数でも動作します;それは、因子分析にやや似た方法で一緒に変数をクラスター化することができます. さらに、階層クラスター分析では、ノミナルデータ、順序データ、スケールデータを処理できますが、異なるレベルの測定を混在させることはお勧めしません。
ツーステップクラスター分析では、まずプリクラスタリングを実行し、次に階層メソッドを実行してグループ化を識別します。 迅速なクラスターアルゴリズムを先行して使用するため、階層クラスターメソッドで計算するのに時間がかかる大きなデータセットを処理できます。 この点で、それは前の2つのアプローチの組み合わせです。 二段階クラスタリングは、同じモデル内のスケールデータと順序データを処理することができ、クラスターの数を自動的に選択します。
1)距離を計算する、2)クラスターをリンクする、3)適切な数のクラスターを選択して解を選択する、という3つの基本的な手順に従います。
まず、クラスターの基礎となる変数を選択する必要があります。 ダイアログウィンドウでは、変数のリストに数学、読み取り、および書き込みのテストを追加します。 ケースをクラスター化したいので、残りの目盛りはデフォルトのままにしておきます。
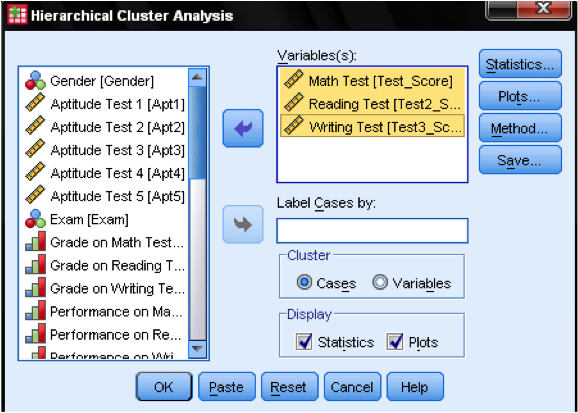
ダイアログボックスStatistics…では、近接行列(これらは分析の最初のステップで計算された距離です)と観測値のケースの予測されたクラスターメンバーシップを出力するかどうかを指定できます。 ここでも、すべての設定をデフォルトのままにします。

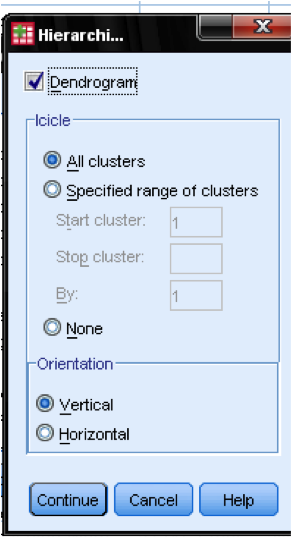
ダイアログボックスプロットで…私たちは、系統図を追加する必要があります。 樹枝図は,クラスタがどのようにマージされるかをグラフィカルに示し,クラスタの適切な数が何であるかを識別することを可能にする。
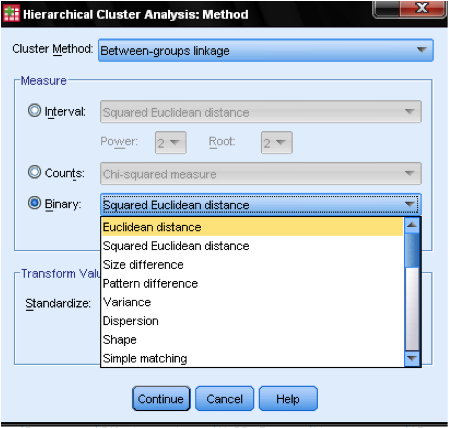
ダイアログボックスメソッド…では、距離測定とクラスタリング方法を指定できます。 まず、正しい距離測度を定義する必要があります。 SPSSには、間隔(スケール)、カウント(順序)、およびバイナリ(ノミナル)データ用の距離メジャーの三つの大きなブロックがあります。
区間データの場合、最も一般的なのは正方ユークリッド距離です。 これは、2つの観測値の間のユークリッド距離に基づいており、これは距離の二乗和の平方根です。 ユークリッド距離は二乗されるので、大きな距離の重要性が増し、小さな距離の重要性が弱まります。

順序データ(カウント)がある場合は、カイ二乗またはファイ二乗と呼ばれる標準化されたカイ二乗の間で選択できます。 バイナリデータでは、ユークリッド距離の二乗が一般的に使用されます。

この例では、区間と二乗ユークリッド距離を選択します。
次に、Clusterメソッドを選択する必要があります。 通常、選択肢は、グループ間のリンケージ(クラスタ間の距離はこれらのクラスタ内のすべてのデータポイントの平均距離)、最近傍(単一リンケージ:クラスタ間の距離は2つのデータポイント間の最小距離)、最も遠い隣接(完全リンケージ:距離は2つのデータポイント間の最大距離)、およびWardの方法(距離はサンプルのグランド平均に対するすべてのクラスタの距離)です。 単一リンケージはクラスタの長いチェーンで最適に機能し、完全なリンケージはクラスタの密なブロブで最適に機能します。 Between-groupsリンケージは、両方のクラスタータイプで動作します。 最初に単一リンケージを使用することをお勧めします。 単一リンケージはクラスターのチェーンを作成する傾向がありますが、外れ値を識別するのに役立ちます。 これらの外れ値を除外した後、Wardの方法に移ることができます。 Wardの方法では、(ANOVAのように)F値を使用して、クラスター間の差の有意性を最大化します。
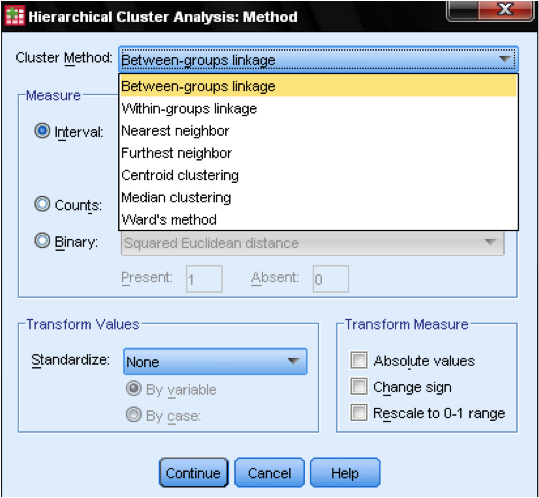
最後の考慮事項は標準化です。 変数に異なる尺度があり、平均値がある場合は、Zスコアに標準化するか、スケールを中心にして標準化することができます。 これが適切なデータセットがある場合は、値を絶対値に変換することもできます。