Che cos’è l’analisi cluster?
L’analisi cluster è un’analisi esplorativa che cerca di identificare le strutture all’interno dei dati. L’analisi del cluster è anche chiamata analisi di segmentazione o analisi tassonomica. Più specificamente, cerca di identificare gruppi omogenei di casi se il raggruppamento non è precedentemente noto. Poiché è esplorativo, non fa alcuna distinzione tra variabili dipendenti e indipendenti. I diversi metodi di analisi dei cluster offerti da SPSS possono gestire dati binari, nominali, ordinali e di scala (intervallo o rapporto).
L’analisi del cluster viene spesso utilizzata in combinazione con altre analisi (come l’analisi discriminante). Il ricercatore deve essere in grado di interpretare l’analisi del cluster in base alla loro comprensione dei dati per determinare se i risultati prodotti dall’analisi sono effettivamente significativi.
Domande tipiche di ricerca le risposte all’analisi del cluster sono le seguenti:
- Medicina-Quali sono i cluster diagnostici? Per rispondere a questa domanda il ricercatore avrebbe escogitato un questionario diagnostico che include possibili sintomi (ad esempio, in psicologia, ansia, depressione ecc.). L’analisi del cluster può quindi identificare gruppi di pazienti che presentano sintomi simili.
- Marketing – Quali sono i segmenti di clientela? Per rispondere a questa domanda un ricercatore di mercato può condurre un sondaggio che copre le esigenze, gli atteggiamenti, i dati demografici e il comportamento dei clienti. Il ricercatore può quindi utilizzare l’analisi del cluster per identificare gruppi omogenei di clienti che hanno esigenze e atteggiamenti simili.
- Istruzione-Quali sono i gruppi di studenti che hanno bisogno di particolare attenzione? I ricercatori possono misurare psicologico, attitudine, e le caratteristiche di realizzazione. Un’analisi di cluster può quindi identificare quali gruppi omogenei esistono tra gli studenti (ad esempio, high achievers in tutte le materie, o studenti che eccellono in alcune materie ma falliscono in altre).
- Biologia-Qual è la tassonomia delle specie? I ricercatori possono raccogliere un set di dati di piante diverse e notare diversi attributi dei loro fenotipi. Un’analisi di cluster può raggruppare tali osservazioni in una serie di cluster e aiutare a costruire una tassonomia di gruppi e sottogruppi di piante simili.
Altre tecniche che potresti voler provare per identificare gruppi simili di osservazioni sono Q-analysis, multi-Dimensional Scaling (MDS) e latent Class analysis.
L’analisi dei cluster in SPSS
La nostra domanda di ricerca per questo esempio di analisi dei cluster è la seguente:
Quali gruppi omogenei di studenti emergono in base ai punteggi dei test standardizzati in matematica, lettura e scrittura?
In SPSS Le analisi dei cluster possono essere trovate in Analizza / Classifica…. SPSS offre tre metodi per l’analisi del cluster: Cluster K-Means, Cluster gerarchico e Cluster in due fasi.
K-means cluster è un metodo per raggruppare rapidamente set di dati di grandi dimensioni. Il ricercatore definisce in anticipo il numero di cluster. Ciò è utile per testare diversi modelli con un diverso numero presunto di cluster.
Il cluster gerarchico è il metodo più comune. Genera una serie di modelli con soluzioni cluster da 1 (tutti i casi in un cluster) a n (ogni caso è un singolo cluster). Il cluster gerarchico funziona anche con le variabili rispetto ai casi; può raggruppare le variabili in un modo in qualche modo simile all’analisi fattoriale. Inoltre, l’analisi gerarchica del cluster può gestire dati nominali, ordinali e di scala; tuttavia non è consigliabile mescolare diversi livelli di misurazione.
L’analisi cluster in due fasi identifica i raggruppamenti eseguendo prima il pre-clustering e poi eseguendo metodi gerarchici. Poiché utilizza un algoritmo di cluster rapido in anticipo, è in grado di gestire set di dati di grandi dimensioni che richiederebbero molto tempo per il calcolo con metodi di cluster gerarchici. A questo proposito, si tratta di una combinazione dei due approcci precedenti. Il clustering in due fasi può gestire la scala e i dati ordinali nello stesso modello e seleziona automaticamente il numero di cluster.
L’analisi gerarchica dei cluster segue tre passaggi fondamentali: 1) calcolare le distanze, 2) collegare i cluster e 3) scegliere una soluzione selezionando il giusto numero di cluster.
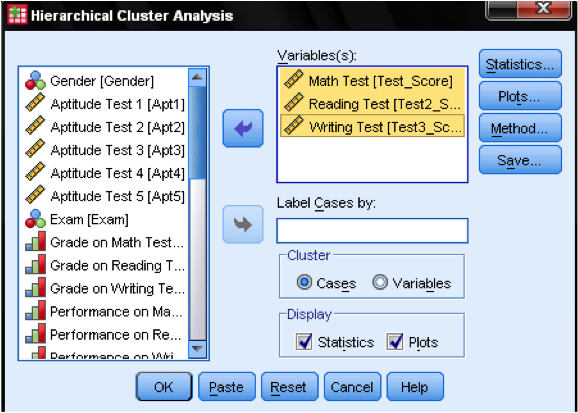
In primo luogo, dobbiamo selezionare le variabili su cui basiamo i nostri cluster. Nella finestra di dialogo aggiungiamo i test di matematica, lettura e scrittura all’elenco delle variabili. Dal momento che vogliamo raggruppare i casi, lasciamo il resto dei segni di spunta sul valore predefinito.
Nella finestra di dialogo Statistiche can possiamo specificare se vogliamo produrre la matrice di prossimità (queste sono le distanze calcolate nella prima fase dell’analisi) e l’appartenenza al cluster prevista dei casi nelle nostre osservazioni. Ancora una volta, lasciamo tutte le impostazioni predefinite.

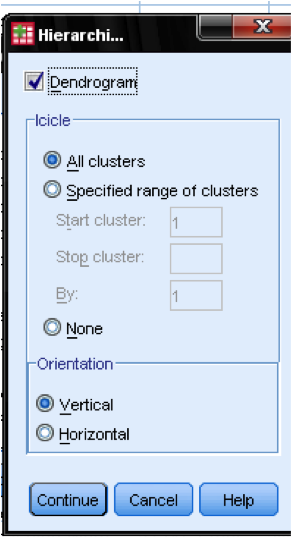
Nei grafici della finestra di dialogo should dovremmo aggiungere il dendrogramma. Il dendrogramma mostrerà graficamente come vengono uniti i cluster e ci consente di identificare quale sia il numero appropriato di cluster.
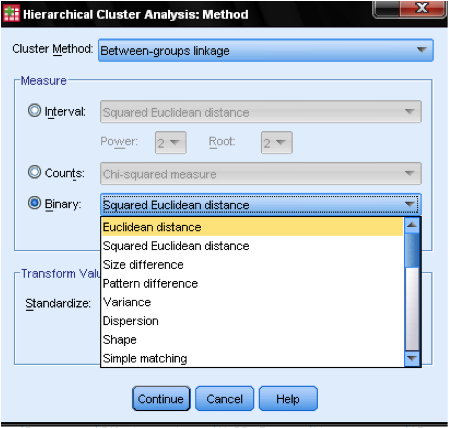
Il metodo della finestra di dialogo allows ci consente di specificare la misura della distanza e il metodo di clustering. Innanzitutto, dobbiamo definire la misura della distanza corretta. SPSS offre tre grandi blocchi di misure di distanza per intervallo (scala), conteggi (ordinali) e dati binari (nominali).
Per i dati di intervallo, il più comune è la distanza euclidea quadrata. Si basa sulla Distanza euclidea tra due osservazioni, che è la radice quadrata della somma delle distanze quadrate. Poiché la Distanza euclidea è quadrata, aumenta l’importanza delle grandi distanze, mentre indebolisce l’importanza delle piccole distanze.

Se abbiamo dati ordinali (conteggi) possiamo scegliere tra Chi-Quadrato o un Chi-Quadrato standardizzato chiamato Phi-Quadrato. Per i dati binari, la Distanza euclidea quadrata è comunemente usata.

Nel nostro esempio, scegliamo Intervallo e Distanza euclidea Quadrata.
Successivamente, dobbiamo scegliere il metodo Cluster. In genere, le scelte sono il collegamento tra gruppi (la distanza tra i cluster è la distanza media di tutti i punti dati all’interno di questi cluster), il vicino più vicino (collegamento singolo: la distanza tra i cluster è la distanza più piccola tra due punti dati), il vicino più lontano (collegamento completo: la distanza è la distanza più grande tra due punti dati) e il metodo di Ward (distanza è la distanza Il collegamento singolo funziona meglio con lunghe catene di cluster, mentre il collegamento completo funziona meglio con blob densi di cluster. Il collegamento tra gruppi funziona con entrambi i tipi di cluster. Si raccomanda è quello di utilizzare singolo collegamento in primo luogo. Sebbene il collegamento singolo tenda a creare catene di cluster, aiuta a identificare valori anomali. Dopo aver escluso questi valori anomali, possiamo passare al metodo di Ward. Il metodo di Ward utilizza il valore F (come in ANOVA) per massimizzare il significato delle differenze tra i cluster.
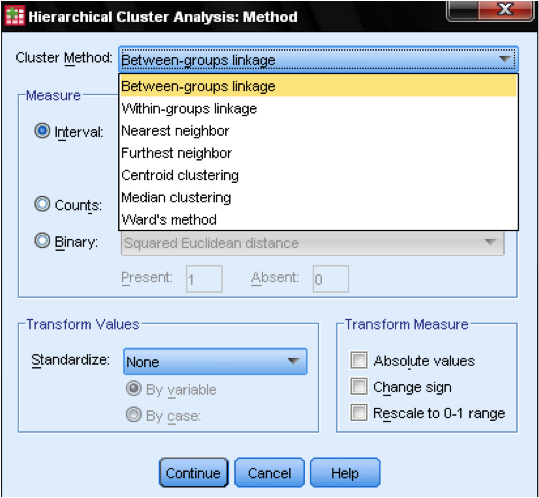
Un’ultima considerazione è la standardizzazione. Se le variabili hanno scale e mezzi diversi, potremmo voler standardizzare i punteggi Z o centrando la scala. Possiamo anche trasformare i valori in valori assoluti se abbiamo un set di dati in cui ciò potrebbe essere appropriato.