nemrégiben egy új változtatási javaslat született a Cassandra indexeléshez, amely megpróbálja csökkenteni a használhatóság és a stabilitás közötti kompromisszumot: a WHERE záradékot sokkal érdekesebbé és hasznosabbá teszi a végfelhasználók számára. Ez az új módszer az úgynevezett Storage-Attached Indexing (Sai). Nem ez a legszebb név, de mit vársz? A mérnökök nem ismertek a dolgok elnevezéséről, de a hűvös technológia soha nem vicc. SAI felkeltette a Cassandra közösség figyelmét, de miért? Az adatok indexelése nem új fogalom az adatbázis világában.
az adatok indexelésének módja idővel változhat a kívánt használati esetek és telepítési modellek alapján. A Cassandra-t a Dynamo és a Big Table szempontjainak kombinálásával építették, hogy csökkentsék az olvasási és írási költségek összetettségét azáltal, hogy egyszerűvé teszik a dolgokat. A Cassandra összetettségét többnyire elosztott jellegére tartották fenn, ennek eredményeként kompromisszumot teremtett a fejlesztők számára. Ha azt szeretné, hogy a hihetetlen méretű Cassandra, meg kell tölteni az időt a tanulás, hogyan kell az adatok modell. Az adatbázis-indexek célja Az adatmodell fejlesztése és a lekérdezések hatékonyabbá tétele. Cassandra számára valamilyen formában léteznek a projekt kezdete óta. A szerencsétlen valóság az, hogy nem feleltek meg jól a felhasználói igényeknek. Bármilyen használata indexelés jön egy hosszú listát a kompromisszumok és figyelmeztetések arra a pontra, hogy ezek többnyire kerülni, és néhány, csak egy kemény nem. Ennek eredményeként a felhasználók megtanulták, hogyan kell adatmodellezni az alapvető lekérdezésekkel a legjobb teljesítmény elérése érdekében.
ezek a napok már mögöttünk lehetnek, és az olyan funkciók, mint a SAI, segítenek nekünk odaérni.
másodlagos indexek elosztott adatbázisokban
nem minden index jön létre egyenlően. Az elsődleges indexeket egyedi kulcsnak vagy Cassandra szókincsben partíciós kulcsnak is nevezik. Az adatbázis elsődleges hozzáférési módszereként a Cassandra a partíciós kulcsot használja az adatokat tároló csomópont, majd az adatok partícióját tároló adatfájl azonosítására. Elsődleges index olvas Cassandra meglehetősen egyszerű,de túlmutat a cikk. Itt olvashat róluk többet.
a másodlagos indexek teljesen más és egyedi kihívást jelentenek egy elosztott adatbázisban. Nézzünk meg egy példa táblázatot, hogy néhány pontot:
CREATE TABLE users (
id long,
lastname text,
lastName text,
country text,
created timestamp,
PRIMARY KEY (ID)
);
az elsődleges indexkeresés nagyon egyszerű lenne:
válassza ki a keresztnevet, a vezetéknevet a felhasználóktól, ahol id = 100;
mi lenne, ha mindenkit meg akarnék találni Franciaországban? Mint valaki, aki ismeri az SQL-t, számíthat arra, hogy ez a lekérdezés működni fog:
válassza ki a lastname, lastName lehetőséget azon felhasználók közül, ahol country = ‘FR’;
másodlagos index létrehozása nélkül a Cassandra-ban ez a lekérdezés sikertelen lesz. A Cassandra alapvető hozzáférési mintája partíciós kulcs szerint történik. Egy nem elosztott adatbázisban, mint egy hagyományos RDBMS, a táblázat minden oszlopa könnyen látható a rendszer számára. Akkor is elérheti az oszlopot, ha nincs index, mivel mindegyik ugyanabban a rendszerben és adatfájlban létezik. Az indexek ebben az esetben segítenek csökkenteni a lekérdezési időt azáltal, hogy hatékonyabbá teszik a keresést.
egy olyan elosztott rendszerben, mint a Cassandra, az oszlopértékek minden adatcsomóponton megtalálhatók, és szerepelniük kell a lekérdezési tervben. Ez beállítja az úgynevezett “szórás-gyűjtés” forgatókönyvet, ahol minden csomópontnak lekérdezést küld, adatokat gyűjt, összevon, és visszaküldi a felhasználónak. Annak ellenére, hogy ez a művelet egyszerre több csomóponton is elvégezhető, a késleltetés kezelése attól függ, hogy a csomópont milyen gyorsan tudja megtalálni az oszlop értékét.
a Cassandra data gyors áttekintése
lehet, hogy azt gondolja, hogy az indexek hozzáadása az adatok olvasásáról szól, ami minden bizonnyal a végcél. Az adatbázis felépítésekor azonban az indexelés technikai kihívásai elfogultak az adatok írásának pontján. Az adatok leggyorsabb sebességgel történő elfogadása, miközben az indexeket a legoptimálisabb formában formázza az olvasáshoz, óriási kihívás. Érdemes gyorsan áttekinteni, hogyan írják az adatokat a Cassanda adatbázisba az egyes csomópontok szintjén. Lásd az alábbi ábrát, ahogy elmagyarázom, hogyan működik.
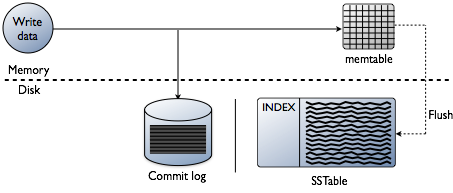
amikor az adatok egy csomópontnak kerülnek bemutatásra, amelyet mutációnak nevezünk, a Cassandra írási útvonala nagyon egyszerű és optimalizált erre a műveletre. Ez igaz sok más adatbázisra is, amelyek Log-Structured Merge(LSM) fákon alapulnak.
- az adatok érvényesítése a megfelelő formátum. Írja be az ellenőrzést a séma ellen.
- írjon adatokat egy elkövetési napló farkába. Nem törekszik, csak a következő helyen a fájl mutató.
- írjon adatokat egy memtáblába, amely csak a memóriában lévő séma hashmap-je.
Kész! A mutációt elismerik, amikor ezek a dolgok megtörténnek. Szeretem, milyen egyszerű ez, mint más adatbázisok, amelyek megkövetelik a zár, és igyekeznek végrehajtani egy írási.
később, amikor a memtables kitölti a fizikai memóriát, egy öblítési folyamat a szegmenseket egyetlen lépésben írja ki a lemezen egy sstable nevű fájlba (rendezett karakterláncok táblázata). A kísérő elkövetési napló törlődik most, hogy a perzisztencia átkerült az SSTable-be. Ez a folyamat folyamatosan ismétlődik, amikor az adatokat a csomópontra írják.
fontos részlet: Az SSTables megváltoztathatatlan. Miután megírták őket, soha nem frissülnek, csak kicserélik őket. Végül, ahogy több adat íródik, a tömörítésnek nevezett háttérfolyamat összeolvad és az sstables-t újakká rendezi, amelyek szintén megváltoztathatatlanok. Sok tömörítési séma létezik, de alapvetően mindannyian elvégzik ezt a funkciót.
most már elég alapvető alapja van a Cassandra-nak, így eléggé idegesek lehetünk az indexekkel. Minden további információmélység gyakorlatként marad az olvasó számára.
a korábbi indexeléssel kapcsolatos problémák
a Cassandra-nak két korábbi másodlagos indexelési implementációja volt. A Storage Attached Secondary Indexing(Sasi) és a Secondary Indexes (másodlagos indexek), amelyeket 2i-nek nevezünk. Ismét itt áll a véleményem arról, hogy a mérnökök nem mutatósak a nevekkel. A másodlagos indexek a kezdetektől fogva a Cassandra részét képezték, de a megvalósítások a végfelhasználók számára gondot okoztak a kompromisszumok hosszú listájával. A két fő probléma, amellyel projektként folyamatosan foglalkoztunk, az íráserősítés és az indexméret a lemezen. Ennek eredményeként frusztrálóan csábíthatnak az új felhasználók számára, hogy később a telepítés során kudarcot valljanak. Nézzük meg mindegyiket.
másodlagos indexek (2i) — ez az eredeti munka a projektben a korai takarékossági adatmodellek kényelmi funkciójaként indult. Később, mivel a Cassandra lekérdezési nyelv felváltotta a takarékosságot, mint a Cassandra preferált lekérdezési módszerét, a 2i funkcionalitást megtartották az” INDEX létrehozása ” szintaxissal. Ha SQL-ből származik, ez egy nagyon egyszerű módja annak, hogy megtanulják a nem kívánt következmények törvényét. Csakúgy, mint az SQL indexelésnél, minél többet ad hozzá, annál jobban befolyásolja az írási teljesítményt. Cassandra esetében azonban ez kiváltotta a nagyobb problémát az írás-erősítéssel. A fenti írási útvonalra hivatkozva a másodlagos indexek új lépést adtak az útvonalhoz. Amikor egy indexelt oszlopban mutáció következik be, egy indexelési művelet indul el, amely újra indexeli az adatokat egy külön indexfájlban. Az asztalon lévő több index drámai módon növelheti a lemez aktivitását egy sor írási műveletben. Amikor egy csomópont nagy mennyiségű mutációt vesz fel, az eredmény telített lemezaktivitás lehet, amely instabillá teheti az egyes csomópontokat, megadva a 2i megérdemelt útmutatását a “takarékosan használja.”Az Index mérete meglehetősen lineáris ebben a megvalósításban, de az újraindexeléssel a szükséges lemezterület mennyiségét nehéz lehet megtervezni egy aktív fürtben.
Storage Attached Secondary Indexing (Sasi) — a Sasi-t eredetileg az Apple egy kis csapata tervezte egy adott lekérdezési probléma megoldására, nem pedig a másodlagos indexek általános problémájára. Ahhoz, hogy tisztességes, hogy a csapat, ez megúszta őket egy Használati esetben, hogy soha nem volt célja, hogy megoldja. Üdvözöljük a nyílt forráskódú mindenkinek. A két lekérdezési típus, amelyet a SASI-nak terveztek:
- Finding sorok alapján részleges adatok megfelelő. Helyettesítő karakter, vagy hasonló lekérdezések.
- tartomány lekérdezések ritka adatok, különösen időbélyegek. Hány rekord fér el egy időtartomány típusú lekérdezésekben.
mindkét műveletet elég jól végezte, és a legacy 2i írási erősítésének kérdésével is foglalkozott. mivel a mutációkat egy Cassandra csomópontnak mutatják be, az adatokat a memóriában indexelik a kezdeti írás során, hasonlóan a memtables használatához. Permutáció esetén nincs szükség lemezaktivitásra. Hatalmas javulás a klaszterekben, sok írási tevékenységgel. Amikor a memtables-t sstables-re öblítik, az adatok megfelelő indexe kipirul. Minden megírt indexfájl megváltoztathatatlan és az sstable-hez van csatolva, innen ered a Storage Attached név. Amikor a tömörítés megtörténik, Az adatok újraexelésre kerülnek, és új fájlba íródnak, amikor új sstables jön létre. A lemezaktivitás szempontjából ez jelentős javulás volt. A Sasi hátránya elsősorban a létrehozott indexek méretében volt. A lemezen lévő indexformátum hatalmas mennyiségű lemezterületet okozott az egyes indexelt oszlopokhoz. Ez nagyon megnehezíti a kezelésüket az üzemeltetők számára. Ezenkívül a SASI-t kísérleti jellegűnek jelölték meg, és nem sok történt a funkciók javításával kapcsolatban. Az idő múlásával sok hibát találtak drága javításokkal, amelyek megvitatták, hogy a SASI-t teljesen el kell-e távolítani. Ha szüksége van a legmélyebb merülésre ezen a funkción, Duy Hai Doan elképesztő munkát végzett a SASI működésének lebontásában.
mi teszi a SAI-t jobbá
az első, legjobb válasz erre a kérdésre az, hogy a SAI evolúciós jellegű. A DataStax mérnökei rájöttek, hogy a másodlagos indexelés alapvető architektúráját az alapoktól kezdve kell kezelni, de szilárd tanulságokkal, amelyeket a korábbi megvalósításokból tanultak. Az elsődleges küldetés az írás-erősítés és az index fájlméret problémáinak kezelése, miközben a Cassandra jobb lekérdezési fejlesztéseinek elérési útját hozta létre. Hogyan kezeli a SAI mindkét témát?
Íráserősítés — amint azt a SASI-tól megtudtuk, a memóriában lévő indexelés és az sstables-szel végzett öblítési indexek a megfelelő módja annak, hogy összhangban maradjanak a Cassandra írási útvonal működésével, miközben új funkciókat adnak hozzá. A Sai-val, amikor a mutációt elismerik, vagyis teljesen elkötelezettek, az adatokat indexelik. Az optimalizálással és a sok teszteléssel az írási teljesítményre gyakorolt hatás jelentősen javult. Meg kell látni jobb, mint egy 40% – os növekedése áteresztőképesség és több mint 200%-kal jobb írási késések felett 2i. hogy azt mondta, akkor is meg kell tervezni növekedését 2x késés és áteresztőképesség indexelt táblák, mint a nem indexelt táblák. Duy Hai Doan-t idézve: “nincs varázslat”, csak jó mérnöki munka.
Indexméret — ez a legdrámaibb javulás, és vitathatatlanul ott, ahol a legtöbb munkát elvégezték. Ha követi az adatbázis belső világát, akkor tudja, hogy az adattárolás továbbra is élénk terület, amelyet folyamatosan fejlődő fejlesztések töltenek be. Az SAI két különböző típusú indexelési sémát használ az adattípus alapján.
- a Szövegfordított indexek szótárba bontott kifejezésekkel jönnek létre. A legnagyobb javulás a Trie alapú indexelés használatából származik, amely sokkal jobb tömörítést kínál, ami kisebb indexméreteket jelent.
- numerikus – a Lucene-ből vett blokk KD-fák nevű adatstruktúra felhasználásával, amely kiváló tartomány-lekérdezési teljesítményt kínál. A rendszer külön sorazonosító listát tart fenn, hogy optimalizálja a tokenrendelési lekérdezéseket.
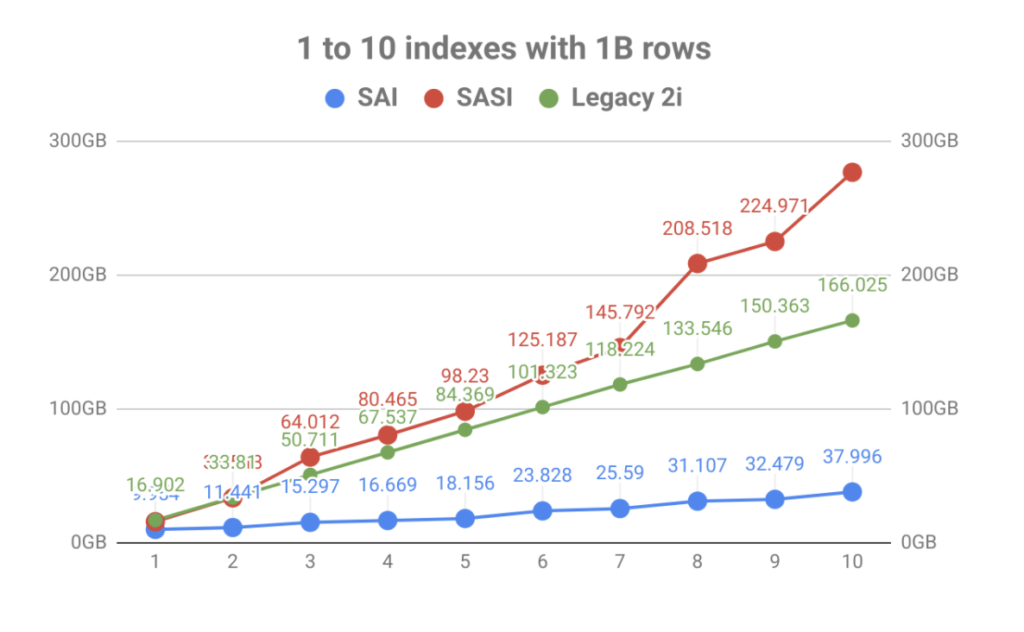
nagy hangsúlyt fektetve az indextárolásra, az eredmény hatalmas javulást eredményezett a kötetben az asztali indexek számával szemben. Amint az alábbi grafikonon látható, a SASI által hozott gyors indexelést gyorsan elhomályosította a Lemezhasználat robbanása. Nem csak fájdalmat okoz az operatív tervezésnek, hanem az indexfájlokat is el kellett olvasni a tömörítési események során, amelyek telíthetik a lemezeket, amelyek csomópont teljesítményproblémákhoz vezethetnek.
az írási erősítésen és az indexméreten kívül az SAI belső architektúrája további bővítést és további funkciókat tesz lehetővé a jövőben. Ez összhangban van a projekt céljaival, hogy a jövőben modulárisabbak legyenek. Vessen egy pillantást a többi függőben lévő Cep-re, és láthatja, hogy ez csak a kezdet.
hová megy innen a SAI?
DataStax felajánlotta SAI az Apache Cassandra projekt révén Cassandra Enhancement folyamat, mint CEP-7. A vita most a 4.Cassandra x ága.
ha szeretné kipróbálni ezt most, mielőtt ez egy része az Apache Cassandra projekt, van egy pár helyen, hogy menjen. Az üzemeltetők vagy az emberek, akik szeretnek egy kicsit több technikai gyakorlati, akkor töltse le a legújabb DataStax Enterprise 6.8. Ha Ön fejlesztő, A Sai mostantól engedélyezve van a DataStax Astra-ban, a Cassandra-ban, mint szolgáltatásban. Létrehozhat egy free-forever tier-t, hogy játsszon a szintaxissal és az új where záradék funkcióval. Ezzel megtudhatja, hogyan kell használni ezt a funkciót a Cassandra indexelési készségek oldalán és a mellékelt dokumentációban.