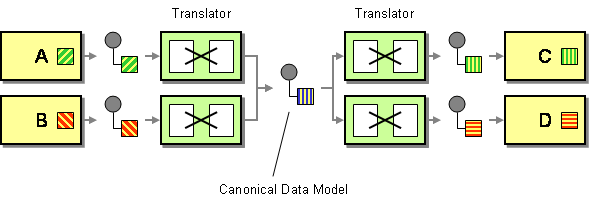
Un modelo de datos canónico se define en los Patrones de integración empresarial como la solución para minimizar las dependencias al integrar aplicaciones que utilizan diferentes formatos de datos. En otras palabras, un componente (una aplicación o un servicio) debe comunicarse con otro componente a través de un formato de datos que sea independiente de ambos formatos de datos de componentes.
Dos cosas a destacar aquí. En primer lugar, definí un componente como una aplicación o un servicio porque dichos modelos se utilizan en el contexto de la integración de aplicaciones y la orientación al servicio. En segundo lugar, estamos hablando de un concepto que debería utilizarse únicamente como formato de datos de transporte. No debe utilizar un formato de datos canónico como estructura interna de su almacén de datos.
Teóricamente, las ventajas son bastante obvias. Un formato de datos canónico reduce el acoplamiento entre aplicaciones, reduce el número de traducciones a desarrollar para integrar un conjunto de componentes, etc. Bastante interesante, ¿verdad? Un único modelo de datos es comprensible para todo el panorama de TI y un conjunto de personas (desarrolladores, analistas de sistemas, partes interesadas del negocio, etc.).) que pueden compartir la misma visión de un concepto dado.
Para fines prácticos, la implementación de tales modelos rara vez es eficiente.
Una persona no es el mismo concepto para el departamento de marketing y soporte en una compañía de seguros. Un vuelo para un sistema de gestión del tráfico aéreo tiene un significado diferente dependiendo de si fue llenado por un piloto o si se trata de un vuelo en curso en la parte superior de su espacio aéreo. Una pieza PLM tiene una representación completamente diferente dependiendo de si acaba de ser diseñada o si tiene que ser mantenida por un equipo de soporte.
En la mayoría de los contextos, diseñar un modelo de datos canónico resulta en un modelo de datos grande con un conjunto completo de atributos opcionales y muy pocos obligatorios (como los identificadores). A pesar de que fue diseñado principalmente para facilitar la integración de componentes, solo lo complicará. Mientras tanto, su modelo creará mucha frustración entre los usuarios debido a su complejidad inherente (en términos de utilización y administración). Además, con respecto al problema del acoplamiento, simplemente lo estás cambiando a otro lugar. En lugar de estar acoplado a un formato de datos de componente, se acopla estrechamente a un formato de datos común que será utilizado por todo el entorno de TI y sujeto a cambios muy frecuentes.
En pocas palabras, en la mayoría de los contextos, un modelo de datos canónico debe considerarse como un anti-patrón. ¿Cuál es la otra opción que considerar que aún debería querer minimizar las dependencias entre dos componentes que intercambian datos?
Domain Driven Design (DDD) recomienda introducir el concepto de contexto delimitado. Un contexto delimitado es simplemente un contexto explícito en el que se aplica un modelo con límites claros con otros contextos delimitados. Dependiendo de su organización, un contexto delimitado podría referirse a un dominio funcional en el que se utiliza un objeto, podría referirse al estado del objeto en sí, etc.
En ese caso, el modelo de datos canónico como tal sería simplemente la parte amarilla en el siguiente diagrama:
La intersección de A, B y C representa el conjunto de atributos que deben estar allí independientemente del contexto (básicamente los atributos obligatorios del MDL grande anterior). Esta parte aún debe diseñarse cuidadosamente debido a su papel central. Sin embargo, es importante seguir siendo pragmático. Si en su contexto no tiene sentido tener un modelo común, simplemente debe descartarlo.
Lo que también es importante es una intersección entre dos contextos (A y B, B y C, C y A). ¿Cómo asignar una representación de objeto de un contexto a otro? ¿Cuáles son los atributos explícitos que deben compartirse en dos contextos? ¿Cuáles son las restricciones comerciales comunes entre dos contextos? Estas preguntas aún deben ser respondidas por un equipo transversal, pero desde una perspectiva empresarial, tiene sentido plantearlas. Ese no siempre era el caso de un solo MDL compartido en contextos potencialmente opuestos.
Sin embargo, con respecto a las partes que no se comparten con otros contextos (en blanco), no debe formar parte de un modelo de datos empresarial. Deberías ser pragmático. Por ejemplo, si un subconjunto es específico de un dominio determinado, los expertos en dominios deberían modelarlo ellos mismos.
Un desafío clave, sin embargo, es identificar esos contextos limitados y podría valer la pena recordar aquí la ley de Conway:
Cualquier organización que diseñe un sistema producirá inevitablemente un diseño cuya estructura sea una copia de la estructura de comunicación de la organización.
Los contextos delimitados no se asignarán necesariamente a la organización actual. Por ejemplo, un contexto limitado puede abarcar varios departamentos. Romper los silos organizacionales debería seguir siendo un objetivo para la mayoría de las empresas.
Además, DDD introduce el concepto de Capa Anticorrupción (ACL). Este patrón puede referirse a una solución para una migración heredada (mediante la introducción de una capa de intermediación entre el sistema antiguo y el nuevo para evitar problemas de calidad de los datos, etc.).). Pero en nuestro contexto, cuando hablamos de corrupción, está relacionado con el modelado de datos de deuda que se puede introducir para resolver problemas a corto plazo.
Tomemos el ejemplo de dos sistemas encargados de administrar un estado dado de una pieza PLM (una pieza es un artículo físico producido o comprado y luego ensamblado como un rotor de helicóptero, por ejemplo). Un sistema heredado (llamémoslo SystemA) está a cargo de administrar la fase de diseño y debe implementar un nuevo sistema (llamémoslo SystemZ) a cargo de administrar la fase de mantenimiento. Todo el entorno de aplicaciones de TI comparte el mismo identificador de parte común (partId), excepto SystemA, que no es consciente de ello. En lugar del partido, SystemA administra su propio identificador, systemAId. Debido a que SystemZ necesita ser llamado SystemA usando systemAId, una heurística podría ser integrar systemAId como parte del modelo de datos de SystemZ.
Este es un error común que debe evitar. Simplemente corrompió su modelo de datos debido a una situación a corto plazo.
El patrón ACL podría haber sido una solución aquí. SystemZ podría haber implementado su propio formato de datos (sin corrupción externa como systemAId). Entonces habría sido hasta una capa de intermediación para gestionar la traducción entre el partido y el systemAId.
Aplicado a nuestro tema, el patrón ACL obliga a implementar una capa entre dos contextos delimitados diferentes. Un componente no sabe cómo llamar a otro componente que no forma parte de su propio contexto delimitado. En su lugar, un componente solo sabe cómo asignar su propia estructura de datos en el formato de datos del contexto delimitado al que pertenece.
Por cierto, esta es una regla general. Un componente pertenecerá a un solo contexto delimitado. Esta es también la razón por la que DDD es una gran opción para la arquitectura de microservicios. Debido a la granularidad de grano fino, es más fácil cumplir con esta regla.
En resumen, un modelo canónico como tal debe considerarse como un anti-patrón en la mayoría de los casos. Debe intentar implementar el concepto de contexto delimitado que significa un modelo por contexto con límites explícitos entre los contextos. Dos componentes que forman parte de contextos delimitados diferentes deben comunicarse a través de una Capa Anticorrupción para evitar la corrupción de los modelos de datos.