Recientemente, ha habido una nueva propuesta de cambio para la indexación de Cassandra que intenta reducir el equilibrio entre usabilidad y estabilidad: Haciendo que la cláusula WHERE sea mucho más interesante y útil para los usuarios finales. Este nuevo método se denomina Indexación conectada al almacenamiento (SAI). No es el nombre más llamativo, pero ¿qué esperabas? Los ingenieros no son conocidos por nombrar cosas, pero la tecnología genial nunca es una broma. SAI ha captado la atención de la comunidad Cassandra, pero ¿por qué? La indexación de datos no es un concepto nuevo en el mundo de las bases de datos.
La forma en que indexamos nuestros datos puede cambiar con el tiempo en función de los casos de uso y modelos de implementación deseados. Cassandra se construyó combinando aspectos de Dinamo y Mesa Grande para reducir la complejidad de la sobrecarga de lectura y escritura al mantener las cosas simples. La complejidad de Cassandra se ha reservado principalmente a su naturaleza distribuida y, como resultado, ha creado una compensación para los desarrolladores. Si desea la increíble escala de Cassandra, tiene que pasar el tiempo aprendiendo a modelar datos. Los índices de base de datos están diseñados para mejorar su modelo de datos y hacer que sus consultas sean más eficientes. Para Cassandra, han existido de alguna forma desde los primeros días del proyecto. La desafortunada realidad es que no se han adaptado bien a los requisitos del usuario. Cualquier uso de la indexación viene con una larga lista de compensaciones y advertencias hasta el punto de que en su mayoría se evitan y, para algunos, solo un duro no. Como resultado, los usuarios han aprendido a modelar datos con consultas básicas para obtener el mejor rendimiento.
Esos días pueden estar quedando atrás y características como SAI nos están ayudando a llegar allí.
Índices secundarios en bases de datos distribuidas
No todos los índices se crean iguales. Los índices primarios también se conocen como clave única, o en el vocabulario de Cassandra, clave de partición. Como método de acceso principal en la base de datos, Cassandra utiliza la clave de partición para identificar el nodo que contiene los datos y luego el archivo de datos que almacena la partición de datos. Las lecturas de índice primario en Cassandra son bastante simples, pero están más allá del alcance de este artículo. Puedes leer más sobre ellos aquí.
Los índices secundarios crean un desafío completamente diferente y único en una base de datos distribuida. Veamos una tabla de ejemplo para hacer algunos puntos:
CREAR usuarios de TABLA (
id largo,
Texto de nombre,
Texto de nombre,
texto de país,
marca de tiempo creada,
CLAVE PRIMARIA (id)
);
Una búsqueda de índice primario sería bastante simple como esta:
SELECCIONAR Nombre, apellido DE LOS usuarios DONDE id = 100;
¿Y si quisiera encontrar a todos en Francia? Como alguien familiarizado con SQL, esperaría que esta consulta funcionara:
SELECCIONE FirstName, LastName DE usuarios DONDE country = ‘FR’;
Sin crear un índice secundario en Cassandra, esta consulta fallará. El patrón de acceso fundamental en Cassandra es por clave de partición. En una base de datos no distribuida como un RDBMS tradicional, cada columna de la tabla es fácilmente visible para el sistema. Aún puede acceder a la columna incluso si no hay un índice, ya que todas existen en el mismo sistema y archivos de datos. Los índices en este caso ayudan a reducir el tiempo de consulta al hacer que la búsqueda sea más eficiente.
En un sistema distribuido como Cassandra, los valores de columna están en cada nodo de datos y deben incluirse en el plan de consulta. Esto configura lo que llamamos el escenario «Scatter-Gather» en el que se envía una consulta a cada nodo, se recopilan datos, se fusionan y se devuelven al usuario. Aunque esta operación se puede realizar en varios nodos a la vez, la administración de latencia se reduce a la velocidad con la que el nodo puede encontrar el valor de la columna.
Revisión rápida de las escrituras de datos de Cassandra
Puede estar pensando que agregar índices se trata de leer datos, que sin duda es el objetivo final. Sin embargo, al construir una base de datos, los desafíos técnicos en la indexación están sesgados en el punto donde se escriben los datos. Aceptar los datos a la velocidad más rápida y formatear los índices de la forma más óptima para las lecturas es un gran desafío. Vale la pena hacer una revisión rápida de cómo se escriben los datos en una base de datos Cassanda a nivel de nodo individual. Consulte el siguiente diagrama mientras explico cómo funciona.
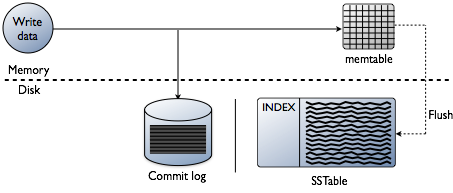
Cuando los datos se presentan a un nodo, que llamamos mutación, la ruta de escritura para Cassandra es muy simple y optimizada para esa operación. Esto también es cierto para muchas otras bases de datos basadas en árboles de fusión estructurados en registros(LSM).
- Validar los datos es el formato correcto. Escriba check en el esquema.
- Escribir datos en la cola de un registro de confirmación. Nada de búsquedas, sólo el siguiente punto en el puntero del archivo.
- Escriba datos en una tabla de memoria, que es solo un mapa de hash del esquema en memoria.
¡Listo! La mutación se reconoce cuando suceden esas cosas. Me encanta lo simple que es esto en comparación con otras bases de datos que requieren un bloqueo y buscan realizar una escritura.
Más tarde, a medida que los memtables llenan la memoria física, un proceso de vaciado escribe segmentos en una sola pasada en el disco a un archivo llamado SSTable (Tabla de cadenas Ordenadas). El registro de confirmación que lo acompaña se elimina ahora que la persistencia se ha movido a la tabla SSTable. Este proceso se repite a medida que los datos se escriben en el nodo.
Detalle importante: Las mesas son inmutables. Una vez que se escriben, nunca se actualizan, solo se reemplazan. Eventualmente, a medida que se escriben más datos, un proceso de fondo llamado compactación se fusiona y clasifica las tablas en otras nuevas que también son inmutables. Hay muchos esquemas de compactación, pero fundamentalmente, todos realizan esta función.
Ahora tiene suficiente base básica en Cassandra para que podamos ser suficientemente nerd con los índices. Cualquier información de mayor profundidad se deja como un ejercicio para el lector.
Problemas con indexación anterior
Cassandra ha tenido dos implementaciones de indexación secundaria anteriores. Indexación Secundaria Adjunta de almacenamiento (SASI) e Índices Secundarios, a los que nos referimos como 2i. De nuevo, mi punto sobre los ingenieros que no son llamativos con los nombres se sostiene aquí. Los índices secundarios han sido parte de Cassandra desde el principio, pero las implementaciones los han hecho problemáticos para los usuarios finales con su larga lista de compensaciones. Las dos preocupaciones principales que hemos tratado constantemente como proyecto son la amplificación de escritura y el tamaño del índice en disco. Como resultado, pueden ser frustrantemente tentadores para los nuevos usuarios solo para que fallen más adelante en la implementación. Echemos un vistazo a cada uno.
Índices secundarios (2i): Este trabajo original en el proyecto comenzó como una función de conveniencia para los primeros modelos de datos de ahorro. Más tarde, como el lenguaje de consulta Cassandra reemplazó a Thrift como el método de consulta preferido para Cassandra, la funcionalidad 2i se mantuvo con la sintaxis «CREATE INDEX». Si había venido de SQL, esta era una manera muy fácil de aprender la ley de las consecuencias no deseadas. Al igual que en la indexación SQL, cuanto más agregue, más afectará el rendimiento de escritura. Sin embargo, con Cassandra, esto desencadenó el problema más grande con la amplificación de escritura. En referencia a la ruta de escritura anterior, los índices secundarios agregaron un nuevo paso a la ruta. Cuando se produce una mutación en una columna indexada, se activa una operación de indexación que vuelve a indexar los datos en un archivo de índice separado. Más índices en una tabla pueden aumentar drásticamente la actividad del disco en una operación de escritura de una sola fila. Cuando un nodo está tomando una gran cantidad de mutaciones, el resultado puede ser una actividad de disco saturada que puede hacer que los nodos individuales sean inestables, dando a 2i la guía merecida de «usar con moderación».»El tamaño del índice es bastante lineal en esta implementación, pero con la reindexación, la cantidad de espacio en disco necesario puede ser difícil de planificar en un clúster activo.
Indexación secundaria adjunta de almacenamiento (SASI): SASI fue diseñado originalmente por un pequeño equipo de Apple para resolver un problema de consulta específico y no el problema general de los índices secundarios. Para ser justos con ese equipo, se les escapó en un caso de uso que nunca fue diseñado para resolver. Bienvenidos a open source todos. Los dos tipos de consulta para los que se diseñó SASI:
- Búsqueda de filas en función de la coincidencia parcial de datos. Comodín, o consultas SIMILARES.
- Consultas de rango en datos dispersos, específicamente marcas de tiempo. Cuántos registros caben en las consultas de tipo de intervalo de tiempo.
Hizo ambas operaciones bastante bien y también abordó el tema de la amplificación de escritura con legacy 2i. Como las mutaciones se presentan a un nodo de Cassandra, los datos se indexan en la memoria durante la escritura inicial, al igual que se usan las tablas de memoria. No se requiere actividad de disco en una permutación. Una gran mejora en clústeres con mucha actividad de escritura. Cuando los memtables se descargan a sstables, se descarga el índice correspondiente para los datos. Cada archivo de índice escrito es inmutable y se adjunta al sstable, de ahí el nombre de Almacenamiento Adjunto. Cuando se produce compactación, los datos se reindexan y se escriben en un nuevo archivo a medida que se crean nuevas tablas sstables. Desde el punto de vista de la actividad del disco, esta fue una mejora importante. La desventaja de SASI fue principalmente en el tamaño de los índices creados. El formato de índice en disco causó una enorme cantidad de espacio en disco utilizado para cada columna indexada. Esto hace que sean muy difíciles de gestionar para los operadores. Además, SASI fue marcado como experimental y no ha pasado mucho con respecto a la mejora de características. Se han encontrado muchos errores con el tiempo con correcciones costosas que han llevado a la discusión de si el SASI debe eliminarse por completo. Si necesita una inmersión más profunda en esta función, Duy Hai Doan hizo un trabajo increíble al desglosar cómo funciona SASI.
Lo que hace mejor a SAI
La primera y mejor respuesta a esa pregunta es que SAI es de naturaleza evolutiva. Los ingenieros de DataStax se dieron cuenta de que la arquitectura central de la Indexación Secundaria debía abordarse desde cero, pero con sólidas lecciones aprendidas de implementaciones anteriores. Abordar los problemas de amplificación de escritura y tamaño de archivo de índice mientras se crea una ruta para mejorar las consultas en Cassandra ha sido la misión principal. ¿Cómo aborda SAI estos dos temas?
Amplificación de escritura: Como aprendimos de SASI, la indexación en memoria y los índices de lavado con tablas SSTables eran la forma correcta de mantenerse en línea con el funcionamiento de la ruta de escritura Cassandra, al tiempo que agregaba nuevas funcionalidades. Con SAI, cuando la mutación es reconocida, es decir, totalmente comprometida, los datos son indexados. Con optimizaciones y muchas pruebas, el impacto en el rendimiento de escritura ha mejorado enormemente. Debería ver mejor que un aumento del 40% en el rendimiento y más de un 200% en latencias de escritura sobre 2i. Dicho esto, aún debe planificar un aumento de 2 veces la latencia y el rendimiento en tablas indexadas en comparación con tablas no indexadas. Para citar a Duy Hai Doan, «No hay magia», solo buena ingeniería.
Tamaño del índice: Esta es la mejora más dramática y, posiblemente, donde se ha realizado la mayor parte del trabajo. Si sigue el mundo de los aspectos internos de las bases de datos, sabrá que el almacenamiento de datos sigue siendo un campo animado lleno de mejoras en continua evolución. SAI utiliza dos tipos diferentes de esquemas de indexación basados en el tipo de datos.
- Los índices invertidos de texto se crean con términos divididos en un diccionario. La mayor mejora es el uso de la indexación basada en Trie, que ofrece una compresión mucho mejor, lo que significa tamaños de índice más pequeños.
- Numérico: Utiliza una estructura de datos llamada árboles de bloques kd, tomada de Lucene, que ofrece un excelente rendimiento de consulta de rango. Se mantiene una lista de ID de fila separada para optimizar las consultas de pedido de tokens.
Con un fuerte énfasis en el almacenamiento de índices, el resultado fue una mejora masiva en el volumen frente al número de índices de tabla. Como puede ver en el gráfico a continuación, la rápida indexación que trajo SASI fue eclipsada rápidamente por la explosión del uso del disco. No solo hace que la planificación operativa sea un problema, sino que los archivos de índice tuvieron que leerse durante los eventos de compactación, lo que podría saturar los discos y provocar problemas de rendimiento de los nodos.
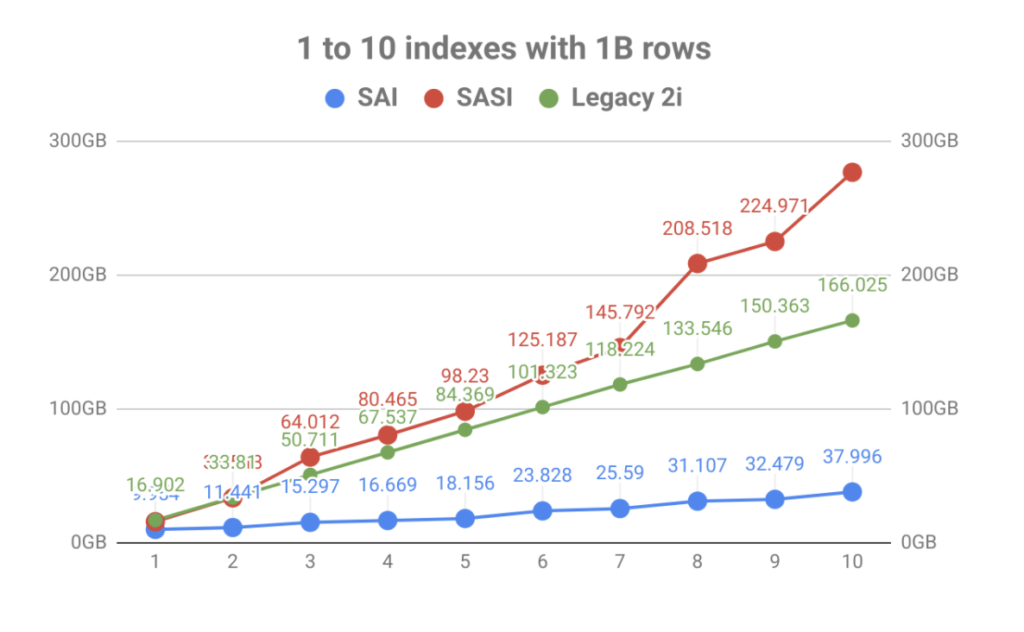
Fuera de la amplificación de escritura y el tamaño del índice, la arquitectura interna de SAI permite una mayor expansión y funcionalidad adicional en el futuro. Esto está en línea con los objetivos del proyecto de ser más modulares en futuras construcciones. Echa un vistazo a algunos de los otros CEP que están pendientes y puedes ver que esto es solo el comienzo.
¿A dónde va SAI desde aquí?
DataStax ha ofrecido SAI al proyecto Apache Cassandra a través del Proceso de Mejora de Cassandra como CEP-7. El debate se encuentra ahora para su inclusión en el 4.rama x de Cassandra.
Si quieres probar esto ahora antes de que forme parte del proyecto Apache Cassandra, tenemos un par de lugares a los que puedes ir. Para operadores o personas a las que les guste la práctica un poco más técnica, puede descargar la última versión de DataStax Enterprise 6.8. Si usted es un desarrollador, SAI ahora está habilitado en DataStax Astra, nuestro Servicio Cassandra como servicio. Puede crear un nivel gratuito para siempre para jugar con la sintaxis y la nueva funcionalidad de cláusula where. Con eso, aprenda a usar esta función yendo a la Página de Habilidades de Indexación de Cassandra y la documentación incluida.