Esta es una guía paso a paso sobre cómo ejecutar el análisis de clústeres de k-means en una hoja de cálculo de Excel de principio a fin. Tenga en cuenta que hay una plantilla de Excel que ejecuta automáticamente el análisis de clústeres disponible para descarga gratuita en este sitio web. Pero si quieres saber cómo ejecutar un clúster de k-means en Excel tú mismo, este artículo es para ti.
Además de este artículo, también tengo un recorrido en video de cómo ejecutar el análisis de clústeres en Excel.
- Paso Uno: Comience con su conjunto de datos
- Paso Dos: Si solo hay dos variables, use un gráfico de dispersión en Excel
- Paso Tres: Calcule la distancia desde cada punto de datos hasta el centro de un clúster
- ¿Cómo funciona el cálculo?
- Paso cuatro-Calcular la media (media) de cada conjunto de grupos
- Paso Cinco-Repetir Paso 3 – la Distancia desde la media revisada
- Paso final: Grafique y Resuma los Clústeres
Paso Uno: Comience con su conjunto de datos
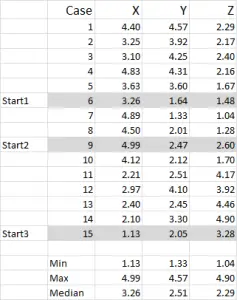
Figura 1
Para este ejemplo, estoy utilizando 15 casos (o encuestados), donde tenemos los datos para tres variables: etiquetados genéricamente X, Y y Z.
Debe notar que los datos se escalan de 1 a 5 en este ejemplo. Sus datos pueden ser de cualquier forma, excepto para una escala de datos nominal (consulte el artículo de qué datos usar).
NOTA: Prefiero usar datos escalados – pero no es obligatorio. La razón de esto es «contener» los valores atípicos. Digamos, por ejemplo, que estoy usando datos de ingresos (una medida demográfica) – la mayoría de los datos pueden estar alrededor de 4 40,000 a 1 100,000, pero tengo una persona con un ingreso de 5 5 millones. Es más fácil para mí clasificar a esa persona en el grupo de ingresos de «más de 2 250,000» y en la escala de ingresos del 1 al 9–, pero eso depende de usted dependiendo de los datos con los que esté trabajando.
Puede ver en este conjunto de ejemplos que se han resaltado tres posiciones de inicio, las discutiremos en el Paso Tres a continuación.
Paso Dos: Si solo hay dos variables, use un gráfico de dispersión en Excel
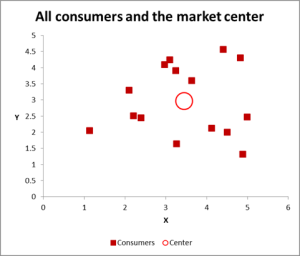
Figura 2
En este ejemplo de análisis de clústeres, estamos utilizando tres variables, pero si solo tiene dos variables para agrupar, un gráfico de dispersión es una excelente manera de comenzar. Y, a veces, puede agrupar los datos a través de medios visuales.
Como puede ver en este gráfico de dispersión, cada caso individual (lo que llamo un consumidor para este ejemplo) se ha mapeado, junto con el promedio (media) para todos los casos (el círculo rojo).
Dependiendo de cómo vea los datos / gráficos, parece que hay varios clústeres. En este caso, podría identificar tres o cuatro clústeres relativamente distintos, como se muestra en el siguiente gráfico.
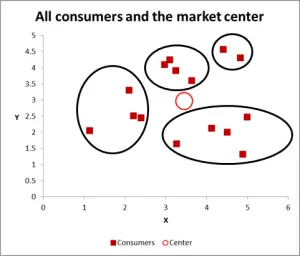
Figura 3
Con este siguiente gráfico, he identificado visiblemente el grupo probable y los he rodeado. Como he sugerido, un buen enfoque cuando solo hay dos variables a considerar, pero en este caso tenemos tres variables (y podría tener más), por lo que este enfoque visual solo funcionará para conjuntos de datos básicos, así que ahora veamos cómo hacer el cálculo de Excel para la agrupación de k – medias.
Paso Tres: Calcule la distancia desde cada punto de datos hasta el centro de un clúster
Para este ejemplo de recorrido, supongamos que solo queremos identificar tres segmentos/clústeres. Sí, hay cuatro grupos evidentes en el diagrama de arriba, pero eso solo mira a dos de las variables. Tenga en cuenta que puede usar este enfoque de Excel para identificar tantos clústeres como desee, solo siga el mismo concepto que se explica a continuación.
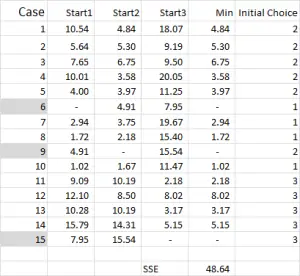
Figura 4
Para la agrupación de k-means, por lo general, elige algunos casos aleatorios (puntos de partida o semillas) para comenzar el análisis.
En este ejemplo, como quiero crear tres clústeres, necesitaré tres puntos de partida. Para estos puntos de inicio he seleccionado los casos 6, 9 y 15, pero cualquier punto aleatorio también podría ser adecuado.
La razón por la que seleccioné estos casos es porque, al mirar solo la variable X, el caso 6 fue la mediana, el caso 9 fue el máximo y el caso 15 fue el mínimo. Esto sugiere que estos tres casos son algo diferentes entre sí, por lo que son buenos puntos de partida a medida que se extienden.
Consulte el artículo sobre por qué el análisis de clústeres a veces genera resultados diferentes.
En referencia a la salida de la tabla, este es nuestro primer cálculo en Excel y genera nuestra «elección inicial» de clústeres. Inicio 1 son los datos para el caso 6, inicio 2 es el caso 9 y inicio 3 es el caso 15. Debe tener en cuenta que la intersección de cada uno de estos da un 0 (-) en la tabla.
¿Cómo funciona el cálculo?
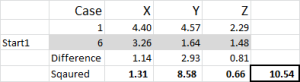
Figura 5
Veamos el primer número de la tabla: caso 1, inicio 1 = 10.54.
Recuerde que hemos designado arbitrariamente el caso 6 como nuestro punto de inicio aleatorio para el Clúster 1. Queremos calcular la distancia y utilizamos el método de suma de cuadrados, como se muestra aquí. Calculamos la diferencia entre cada uno de los tres puntos de datos en el conjunto, y luego cuadramos las diferencias, y luego las sumamos.
Podemos hacerlo «mecánicamente» como se muestra aquí, pero Excel tiene una fórmula incorporada para usar: SUMXMY2, esto es mucho más eficiente de usar.
Volviendo a la Figura 4, encontramos la distancia mínima para cada caso de cada uno de los tres puntos de inicio, que nos indica a qué grupo (1, 2 o 3) es el más cercano al caso, que se muestra en la «columna de elección inicial».
Paso cuatro-Calcular la media (media) de cada conjunto de grupos
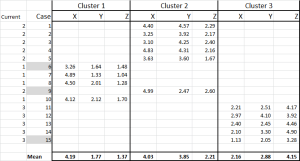
Figura 6
Ahora hemos asignado cada caso a su clúster inicial, y podemos establecerlo usando una instrucción IF en una tabla (como se muestra en la Figura 6).
En la parte inferior de la tabla, tenemos la media (promedio) de cada uno de estos casos. N0w, en lugar de depender de un solo punto de datos «representativo», tenemos un conjunto de casos que representan cada uno.
Paso Cinco-Repetir Paso 3 – la Distancia desde la media revisada
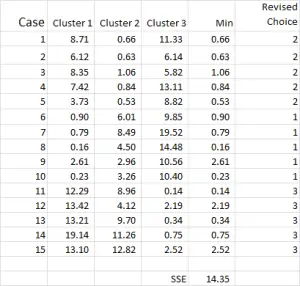
Figura 7
El proceso de análisis de clústeres ahora se convierte en una cuestión de repetir los pasos 4 y 5 (iteraciones) hasta que los clústeres se estabilicen.
Cada vez que usamos la media revisada para cada clúster. Por lo tanto, la Figura 7 muestra nuestra segunda iteración, pero esta vez estamos utilizando las medias generadas en la parte inferior de la Figura 6 (en lugar de los puntos de inicio de la Figura 1).
Ahora puede ver que se ha producido un ligero cambio en la aplicación del clúster, con el caso 9, uno de nuestros puntos de partida, reasignado.
También puede ver la suma de error cuadrado (SSE) calculada en la parte inferior – que es la suma de cada una de las distancias mínimas. Nuestro objetivo es repetir ahora los pasos 4 y 5 hasta que el SSE solo muestre una mejora mínima y/o los cambios de asignación de clúster sean menores en cada iteración.
Paso final: Grafique y Resuma los Clústeres
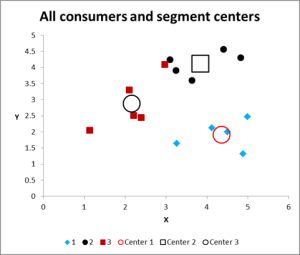
Figura 8
Después de ejecutar varias iteraciones, ahora tenemos la salida para graficar y resumir los datos.
Aquí está el gráfico de salida para este ejemplo de Excel de análisis de clúster.
Como puede ver, se muestran tres clústeres distintos, junto con los centroides (promedio) de cada cluster, los símbolos más grandes.
También podemos presentar estos datos en forma de tabla si es necesario, como lo hemos elaborado en Excel.
Por favor, eche un vistazo a la carcasa del clúster 3, el pequeño cuadrado rojo justo al lado del punto negro en la parte superior central del gráfico. Ese caso se encuentra allí debido a la influencia de la tercera variable, que no se muestra en este gráfico de dos variables.