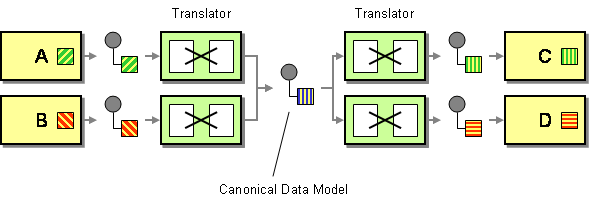
Ein kanonisches Datenmodell ist in den Enterprise Integration Patterns als Lösung definiert, um Abhängigkeiten bei der Integration von Anwendungen, die unterschiedliche Datenformate verwenden, zu minimieren. Mit anderen Worten, eine Komponente (eine Anwendung oder ein Dienst) sollte mit einer anderen Komponente über ein Datenformat kommunizieren, das von beiden Komponentendatenformaten unabhängig ist.
Hier sind zwei Dinge hervorzuheben. Zuerst habe ich eine Komponente entweder als Anwendung oder als Dienst definiert, da solche Modelle im Kontext der Anwendungsintegration und Serviceorientierung verwendet werden. Zweitens sprechen wir hier über ein Konzept, das ausschließlich als Transportdatenformat verwendet werden sollte. Sie sollten kein kanonisches Datenformat als interne Struktur Ihres Datenspeichers verwenden.
Theoretisch liegen die Vorteile auf der Hand. Ein kanonisches Datenformat reduziert die Kopplung zwischen Anwendungen, reduziert die Anzahl der zu entwickelnden Übersetzungen für die Integration eines Satzes von Komponenten usw. Ziemlich interessant, oder? Ein einziges Datenmodell ist für die gesamte IT-Landschaft und eine Reihe von Personen (Entwickler, Systemanalytiker, Geschäftsakteure usw.) verständlich.), die die gleiche Vision eines bestimmten Konzepts teilen können.
Für praktische Zwecke ist die Implementierung solcher Modelle jedoch selten effizient.
Eine Person ist nicht dasselbe Konzept für die Marketing- und Supportabteilung eines Versicherungsunternehmens. Ein Flug für ein Flugverkehrsmanagementsystem hat eine andere Bedeutung, je nachdem, ob er von einem Piloten ausgefüllt wurde oder ob es sich um einen laufenden Flug über Ihrem Luftraum handelt. Ein PLM-Teil hat eine völlig andere Darstellung, je nachdem, ob es gerade entworfen wurde oder von einem Support-Team gewartet werden muss.
In den meisten Kontexten führt das Entwerfen eines kanonischen Datenmodells zu einem großen Datenmodell mit einem vollständigen Satz optionaler Attribute und sehr wenigen obligatorischen Attributen (wie den Bezeichnern). Obwohl es in erster Linie zur Vereinfachung der Komponentenintegration entwickelt wurde, werden Sie es nur komplizieren. In der Zwischenzeit wird Ihr Modell aufgrund seiner inhärenten Komplexität (in Bezug auf Auslastung und Verwaltung) bei den Benutzern große Frustration hervorrufen. Darüber hinaus verschieben Sie es in Bezug auf das Kupplungsproblem einfach woanders. Anstatt an ein Komponentendatenformat gekoppelt zu sein, werden Sie eng an ein gemeinsames Datenformat gekoppelt, das von der gesamten IT-Landschaft verwendet wird und sehr häufigen Änderungen unterliegt.
Kurz gesagt, in den meisten Kontexten sollte ein kanonisches Datenmodell als Anti-Muster betrachtet werden. Was ist die andere Option, als zu überlegen, ob Sie die Abhängigkeiten zwischen zwei Komponenten, die Daten austauschen, minimieren möchten?
Domain Driven Design (DDD) empfiehlt die Einführung des Konzepts des begrenzten Kontexts. Ein begrenzter Kontext ist einfach ein expliziter Kontext, in dem ein Modell mit klaren Grenzen zu anderen begrenzten Kontexten angewendet wird. Abhängig von Ihrer Organisation kann sich ein begrenzter Kontext auf eine Funktionsdomäne beziehen, in der ein Objekt verwendet wird, auf den Objektzustand selbst usw.
In diesem Fall wäre das kanonische Datenmodell als solches einfach der gelbe Teil im folgenden Diagramm:
Der Schnittpunkt von A, B und C repräsentiert den Satz von Attributen, die unabhängig vom Kontext vorhanden sein müssen (im Grunde die obligatorischen Attribute des vorherigen großen CDM). Dieser Teil sollte aufgrund seiner zentralen Rolle dennoch sorgfältig gestaltet werden. Dennoch ist es wichtig, pragmatisch zu bleiben. Wenn es in Ihrem Kontext keinen Sinn macht, ein solches gemeinsames Modell zu haben, sollten Sie es einfach verwerfen.
Wichtig ist auch eine Schnittmenge zweier Kontexte (A und B, B und C, C und A). Wie ordne ich eine Objektdarstellung von einem Kontext einem anderen zu? Was sind die expliziten Attribute, die in zwei Kontexten gemeinsam genutzt werden sollten? Was sind die gemeinsamen Geschäftsbeschränkungen zwischen zwei Kontexten? Diese Fragen sollten noch von einem transversalen Team beantwortet werden, aber aus betriebswirtschaftlicher Sicht ist es sinnvoll, sie anzusprechen. Dies war bei einem einzigen CDM, das in potenziell entgegengesetzten Kontexten gemeinsam genutzt wurde, nicht immer der Fall.
In Bezug auf die Teile, die nicht mit anderen Kontexten geteilt werden (in weiß), sollte es jedoch nicht Teil eines Unternehmensdatenmodells sein. Sie sollten pragmatisch sein. Wenn beispielsweise eine Teilmenge für eine bestimmte Domäne spezifisch ist, sollte es Sache der Domänenexperten sein, sie selbst zu modellieren.
Eine zentrale Herausforderung besteht jedoch darin, diese begrenzten Kontexte zu identifizieren, und es könnte sich lohnen, hier an das Conway-Gesetz zu erinnern:
Jede Organisation, die ein System entwirft, wird unweigerlich ein Design erstellen, dessen Struktur eine Kopie der Kommunikationsstruktur der Organisation ist.
Die begrenzten Kontexte müssen nicht unbedingt auf die aktuelle Organisation abgebildet werden. Beispielsweise kann ein begrenzter Kontext mehrere Abteilungen umfassen. Das Aufbrechen organisatorischer Silos sollte für die meisten Unternehmen immer noch ein Ziel sein.
Darüber hinaus führt DDD das Konzept der Antikorruptionsschicht (ACL) ein. Dieses Muster kann sich auf eine Lösung für eine Legacy-Migration beziehen (indem eine Zwischenschicht zwischen dem alten und dem neuen System eingeführt wird, um Datenqualitätsprobleme usw. zu vermeiden.). Aber in unserem Kontext, wenn wir über Korruption sprechen, hängt es mit der Datenmodellierung zusammen, die Sie einführen können, um kurzfristige Probleme zu lösen.
Nehmen wir das Beispiel zweier Systeme, die für die Verwaltung eines bestimmten Zustands eines PLM-Teils zuständig sind (ein Teil ist ein physisches Element, das hergestellt oder gekauft und dann wie beispielsweise ein Hubschrauberrotor zusammengebaut wird). Ein Legacy-System (nennen wir es SystemA) ist für die Verwaltung der Designphase verantwortlich, und Sie müssen ein neues System (nennen wir es SystemZ) implementieren, das für die Verwaltung der Wartungsphase verantwortlich ist. Die gesamte IT-Anwendungslandschaft verwendet denselben Common Part Identifier (partId), mit Ausnahme von SystemA, das ihn nicht kennt. Anstelle der partId verwaltet SystemA einen eigenen Bezeichner, systemAId . Da SystemZ mit systemAId aufgerufen werden muss, könnte eine Heuristik darin bestehen, systemAId als Teil des SystemZ-Datenmodells zu integrieren.
Dies ist ein häufiger Fehler, den Sie vermeiden sollten. Sie haben Ihr Datenmodell einfach aufgrund einer kurzfristigen Situation beschädigt.
Das ACL-Muster hätte hier eine Lösung sein können. SystemZ hätte ein eigenes Datenformat implementieren können (ohne externe Beschädigung wie die systemAId). Dann wäre es an einer Vermittlungsschicht gewesen, die Übersetzung zwischen der partId und der systemAId zu verwalten.
Angewendet auf unser Thema erzwingt das ACL-Muster die Implementierung einer Ebene zwischen zwei verschiedenen begrenzten Kontexten. Eine Komponente weiß nicht, wie sie eine andere Komponente aufrufen soll, die nicht Teil ihres eigenen begrenzten Kontexts ist. Stattdessen weiß eine Komponente nur, wie sie ihre eigene Datenstruktur dem Datenformat des begrenzten Kontexts zuordnet, zu dem sie gehört.
Dies ist übrigens eine Faustregel. Eine Komponente darf nur zu einem begrenzten Kontext gehören. Aus diesem Grund eignet sich DDD auch hervorragend für die Microservices-Architektur. Aufgrund der feinkörnigen Granularität ist es einfacher, diese Regel einzuhalten.
Zusammenfassend sollte ein kanonisches Modell als solches in den meisten Fällen als Anti-Muster betrachtet werden. Sie sollten versuchen, das Konzept des begrenzten Kontexts zu implementieren, dh ein Modell pro Kontext mit expliziten Grenzen zwischen den Kontexten. Zwei Komponenten, die Teil verschiedener begrenzter Kontexte sind, sollten über eine Antikorruptionsschicht kommunizieren, um eine Beschädigung der Datenmodellierung zu verhindern.