Vor kurzem gab es einen neuen Änderungsvorschlag für die Cassandra-Indizierung, der versucht, den Kompromiss zwischen Benutzerfreundlichkeit und Stabilität zu verringern: Die WHERE-Klausel für Endbenutzer viel interessanter und nützlicher zu machen. Diese neue Methode wird als Storage-Attached Indexing (SAI) bezeichnet. Es ist nicht der auffälligste Name, aber was erwartest du? Ingenieure sind nicht dafür bekannt, Dinge zu benennen, aber coole Technologie ist nie ein Witz. SAI hat die Aufmerksamkeit der Cassandra-Community auf sich gezogen, aber warum? Das Indizieren von Daten ist in der Datenbankwelt kein neues Konzept.
Wie wir unsere Daten indizieren, kann sich im Laufe der Zeit ändern, basierend auf den gewünschten Anwendungsfällen und Bereitstellungsmodellen. Cassandra wurde entwickelt, um Aspekte von Dynamo und Big Table zu kombinieren, um die Komplexität des Lese- und Schreibaufwands zu reduzieren, indem die Dinge einfach gehalten werden. Die Komplexität von Cassandra war hauptsächlich seiner verteilten Natur vorbehalten und hat daher einen Kompromiss für Entwickler geschaffen. Wenn Sie den unglaublichen Umfang von Cassandra nutzen möchten, müssen Sie die Zeit damit verbringen, das Datenmodell zu lernen. Datenbankindizes sollen Ihr Datenmodell verbessern und Ihre Abfragen effizienter gestalten. Für Cassandra gibt es sie in irgendeiner Form seit den Anfängen des Projekts. Die unglückliche Realität ist, dass sie nicht gut mit den Benutzeranforderungen übereinstimmen. Jede Verwendung von Indizierung kommt mit einer langen Liste von Kompromissen und Warnungen bis zu dem Punkt, dass sie meist vermieden werden und für einige, nur ein hartes Nein. Infolgedessen haben Benutzer gelernt, wie sie Datenmodelle mit grundlegenden Abfragen erstellen, um die beste Leistung zu erzielen.
Diese Tage mögen hinter uns liegen und Funktionen wie SAI helfen uns, dorthin zu gelangen.
Sekundärindizes in verteilten Datenbanken
Nicht alle Indizes werden gleich erstellt. Primärindizes werden auch als eindeutiger Schlüssel oder im Cassandra-Vokabular als Partitionsschlüssel bezeichnet. Als primäre Zugriffsmethode auf die Datenbank verwendet Cassandra den Partitionsschlüssel, um den Knoten zu identifizieren, der die Daten enthält, und dann die Datendatei, in der die Datenpartition gespeichert ist. Primärindex-Lesevorgänge in Cassandra sind ziemlich einfach, gehen jedoch über den Rahmen dieses Artikels hinaus. Sie können hier mehr über sie lesen.
Sekundärindizes stellen eine völlig andere und einzigartige Herausforderung in einer verteilten Datenbank dar. Schauen wir uns eine Beispieltabelle an, um einige Punkte zu machen:
CREATE TABLE users (
id long,
FirstName text,
LastName text,
country text,
created timestamp,
PRIMARY KEY (id)
);
Eine Primärindex-Suche wäre ziemlich einfach wie folgt:
SELECT FirstName, LastName FROM users WHERE id = 100;
Was wäre, wenn ich alle in Frankreich finden wollte? Als jemand, der mit SQL vertraut ist, würden Sie erwarten, dass diese Abfrage funktioniert:
SELECT FirstName, LastName FROM users WHERE country = ‚FR‘;
Ohne einen sekundären Index in Cassandra zu erstellen, schlägt diese Abfrage fehl. Das grundlegende Zugriffsmuster in Cassandra ist der Partitionsschlüssel. In einer nicht verteilten Datenbank wie einem herkömmlichen RDBMS ist jede Spalte der Tabelle für das System leicht sichtbar. Sie können weiterhin auf die Spalte zugreifen, auch wenn kein Index vorhanden ist, da sie alle in denselben System- und Datendateien vorhanden sind. Indizes helfen in diesem Fall, die Abfragezeit zu verkürzen, indem sie die Suche effizienter machen.
In einem verteilten System wie Cassandra befinden sich die Spaltenwerte auf jedem Datenknoten und müssen im Abfrageplan enthalten sein. Dadurch wird das sogenannte „Scatter-Gather“ -Szenario eingerichtet, in dem eine Abfrage an jeden Knoten gesendet, Daten gesammelt, zusammengeführt und an den Benutzer zurückgegeben werden. Obwohl dieser Vorgang über mehrere Knoten gleichzeitig ausgeführt werden kann, hängt das Latenzmanagement davon ab, wie schnell der Knoten den Spaltenwert finden kann.
Schneller Überblick über Cassandra Data writes
Sie denken vielleicht, dass es beim Hinzufügen von Indizes darum geht, Daten zu lesen, was sicherlich das Endziel ist. Beim Erstellen einer Datenbank sind die technischen Herausforderungen bei der Indizierung jedoch an der Stelle, an der Daten geschrieben werden, voreingenommen. Es ist eine große Herausforderung, die Daten mit der schnellsten Geschwindigkeit zu akzeptieren und gleichzeitig die Indizes in der optimalsten Form für Lesevorgänge zu formatieren. Es lohnt sich, einen kurzen Überblick darüber zu geben, wie Daten auf der Ebene der einzelnen Knoten in eine Cassanda-Datenbank geschrieben werden. Beachten Sie das folgende Diagramm, wie ich erkläre, wie es funktioniert.
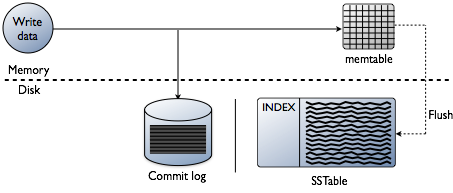
Wenn Daten einem Knoten präsentiert werden, den wir Mutation nennen, ist der Schreibpfad für Cassandra sehr einfach und für diesen Vorgang optimiert. Dies gilt auch für viele andere Datenbanken, die auf Log-Structured Merge (LSM) -Bäumen basieren.
- Validate data ist das richtige Format. Typprüfung gegen das Schema.
- Schreibt Daten in den Tail eines Commit-Logs. Keine Suche, nur die nächste Stelle auf dem Dateizeiger.
- Schreiben Sie Daten in eine Memtable, die nur eine Hashmap des Schemas im Speicher ist.
Fertig! Die Mutation wird anerkannt, wenn diese Dinge passieren. Ich liebe es, wie einfach dies im Vergleich zu anderen Datenbanken ist, die eine Sperre erfordern und versuchen, einen Schreibvorgang durchzuführen.
Später, wenn die Memtables den physischen Speicher füllen, schreibt ein Flush-Prozess Segmente in einem einzigen Durchgang auf der Festplatte in eine Datei namens SSTable (Sorted Strings Table). Das zugehörige Commit-Protokoll wird gelöscht, nachdem die Persistenz in die SSTable verschoben wurde. Dieser Vorgang wiederholt sich ständig, wenn Daten in den Knoten geschrieben werden.
Wichtiges Detail: SSTables sind unveränderlich. Sobald sie geschrieben sind, werden sie nie aktualisiert, sondern nur ersetzt. Wenn schließlich mehr Daten geschrieben werden, wird ein Hintergrundprozess namens Compaction zusammengeführt und sortiert sstables in neue, die ebenfalls unveränderlich sind. Es gibt viele Verdichtungsschemata, aber grundsätzlich erfüllen sie alle diese Funktion.
Sie haben jetzt genügend grundlegende Grundlagen für Cassandra, damit wir mit Indizes ausreichend nerdig werden können. Jede weitere Informationstiefe bleibt dem Leser als Übung überlassen.
Probleme mit vorheriger Indizierung
Cassandra hatte zwei vorherige sekundäre Indizierungsimplementierungen. Storage Attached Secondary Indexing(SASI) und Sekundärindizes, die wir als 2i bezeichnen. Auch hier gilt mein Punkt, dass Ingenieure mit Namen nicht auffällig sind. Sekundärindizes waren von Anfang an ein Teil von Cassandra, aber die Implementierungen haben sie für Endbenutzer mit ihrer langen Liste von Kompromissen problematisch gemacht. Die beiden Hauptanliegen, mit denen wir uns als Projekt ständig befasst haben, sind die Schreibverstärkung und die Indexgröße auf der Festplatte. Infolgedessen können sie für neue Benutzer frustrierend verlockend sein, nur um sie später in der Bereitstellung fehlschlagen zu lassen. Schauen wir uns jeden an.
Sekundärindizes (2i) — Diese ursprüngliche Arbeit im Projekt begann als Komfortfunktion für frühe Sparsamkeitsdatenmodelle. Später, als Cassandra Query Language Thrift als bevorzugte Abfragemethode für Cassandra ersetzte, wurde die 2i-Funktionalität mit der Syntax „INDEX ERSTELLEN“ beibehalten. Wenn Sie von SQL gekommen waren, war dies eine wirklich einfache Möglichkeit, das Gesetz der unbeabsichtigten Konsequenzen zu lernen. Genau wie bei der SQL-Indizierung wirkt sich die Schreibleistung umso mehr aus, je mehr Sie hinzufügen. Bei Cassandra löste dies jedoch das größere Problem mit der Schreibverstärkung aus. In Bezug auf den obigen Schreibpfad haben sekundäre Indizes dem Pfad einen neuen Schritt hinzugefügt. Wenn eine Mutation in einer indizierten Spalte auftritt, wird eine Indizierungsoperation ausgelöst, die Daten in einer separaten Indexdatei neu indiziert. Mehr Indizes in einer Tabelle können die Festplattenaktivität in einem einzelnen Zeilenschreibvorgang drastisch erhöhen. Wenn ein Knoten eine hohe Menge an Mutationen aufnimmt, kann das Ergebnis eine gesättigte Plattenaktivität sein, die die einzelnen Knoten instabil machen kann, was 2i die verdiente Anleitung „sparsam verwenden“ gibt.“ Die Indexgröße ist in dieser Implementierung ziemlich linear, aber mit der Neuindizierung kann der erforderliche Speicherplatz in einem aktiven Cluster schwer zu planen sein.
Storage Attached Secondary Indexing (SASI) — SASI wurde ursprünglich von einem kleinen Team bei Apple entwickelt, um ein bestimmtes Abfrageproblem und nicht das allgemeine Problem der Sekundärindizes zu lösen. Um diesem Team gegenüber fair zu sein, ist es ihnen in einem Anwendungsfall entgangen, für dessen Lösung es nie entwickelt wurde. Willkommen bei Open Source für alle. Die beiden Abfragetypen, für die SASI entwickelt wurde:
- Zeilen basierend auf teilweiser Datenübereinstimmung finden. Platzhalter oder ÄHNLICHE Abfragen.
- Bereichsabfragen für spärliche Daten, insbesondere Zeitstempel. Wie viele Datensätze passen in einen Zeitraum Typ Abfragen.
Beide Operationen wurden recht gut ausgeführt und das Problem der Schreibverstärkung mit Legacy 2i wurde ebenfalls behoben. Wenn einem Cassandra-Knoten Mutationen angezeigt werden, werden die Daten während des ersten Schreibvorgangs im Speicher indiziert, ähnlich wie Memtables verwendet werden. Für eine Permutation ist keine Plattenaktivität erforderlich. Eine enorme Verbesserung gegenüber Clustern mit viel Schreibaktivität. Wenn memtables in sstables geleert werden, wird der entsprechende Index für die Daten geleert. Jede geschriebene Indexdatei ist unveränderlich und an die sstable angehängt, daher der Name Storage Attached . Wenn die Komprimierung erfolgt, werden die Daten neu indiziert und in eine neue Datei geschrieben, wenn neue sstables erstellt werden. Aus Sicht der Plattenaktivität war dies eine wesentliche Verbesserung. Der Nachteil von SASI lag hauptsächlich in der Größe der erstellten Indizes. Das On-Disk-Indexformat verursachte eine enorme Menge an Speicherplatz für jede indizierte Spalte. Dies macht sie für Betreiber sehr schwierig zu verwalten. Darüber hinaus wurde SASI als experimentell markiert und in Bezug auf die Funktionsverbesserung ist nicht viel passiert. Im Laufe der Zeit wurden viele Fehler mit teuren Korrekturen gefunden, die die Diskussion darüber ausgelöst haben, ob SASI vollständig entfernt werden sollte. Wenn Sie den tiefsten Einblick in diese Funktion benötigen, hat Duy Hai Doan die Funktionsweise von SASI hervorragend beschrieben.
Was macht SAI besser
Die erste, beste Antwort auf diese Frage ist, dass SAI evolutionärer Natur ist. Die Ingenieure von DataStax erkannten, dass die Kernarchitektur der sekundären Indizierung von Grund auf angegangen werden musste, jedoch mit soliden Lehren, die aus früheren Implementierungen gezogen wurden. Die Probleme der Schreibverstärkung und der Indexdateigröße anzugehen und gleichzeitig einen Pfad für bessere Abfrageverbesserungen in Cassandra zu erstellen, war die Hauptaufgabe. Wie geht die ORKB mit diesen beiden Themen um?
Schreibverstärkung – Wie wir von SASI gelernt haben, war die In-Memory-Indizierung und das Leeren von Indizes mit SSTables der richtige Weg, um mit der Funktionsweise des Cassandra-Schreibpfads Schritt zu halten und gleichzeitig neue Funktionen hinzuzufügen. Bei SAI werden die Daten indiziert, wenn die Mutation bestätigt wird, dh vollständig festgeschrieben ist. Mit Optimierungen und vielen Tests haben sich die Auswirkungen auf die Schreibleistung erheblich verbessert. Sie sollten eine Steigerung des Durchsatzes um mehr als 40% und eine Verbesserung der Schreiblatenzen um über 200% gegenüber 2i erzielen. Sie sollten jedoch immer noch eine Erhöhung der Latenz und des Durchsatzes um das 2-fache für indizierte Tabellen im Vergleich zu nicht indizierten Tabellen einplanen. Um Duy Hai Doan zu zitieren: „Es gibt keine Magie“, nur gute Technik.
Indexgröße – Dies ist die dramatischste Verbesserung und wohl der Ort, an dem die meiste Arbeit geleistet wurde. Wenn Sie der Welt der Datenbank-Interna folgen, wissen Sie, dass die Datenspeicherung immer noch ein lebhaftes Feld ist, das von sich ständig weiterentwickelnden Verbesserungen geprägt ist. SAI verwendet zwei verschiedene Arten von Indexierungsschemata basierend auf dem Datentyp.
- Textinvertierte Indizes werden mit Begriffen erstellt, die in ein Wörterbuch unterteilt sind. Die größte Verbesserung ergibt sich aus der Verwendung der Trie-basierten Indizierung, die eine viel bessere Komprimierung bietet, was kleinere Indexgrößen bedeutet.
- Numerisch – Verwendung einer Datenstruktur namens Block kd-trees aus Lucene, die eine hervorragende Abfrageleistung bietet. Eine separate Zeilen-ID-Liste wird zur Optimierung für Token-Bestellabfragen verwaltet.
Mit einer starken Betonung der Indexspeicherung war das Ergebnis eine massive Verbesserung des Volumens gegenüber der Anzahl der Tabellenindizes. Wie Sie in der folgenden Grafik sehen können, wurde die schnelle Indizierung durch SASI durch die Explosion der Festplattennutzung schnell in den Schatten gestellt. Dies macht nicht nur die Betriebsplanung zu einem Problem, sondern die Indexdateien mussten auch während der Verdichtungsereignisse gelesen werden, wodurch die Festplatten gesättigt werden konnten, was zu Problemen mit der Knotenleistung führte.
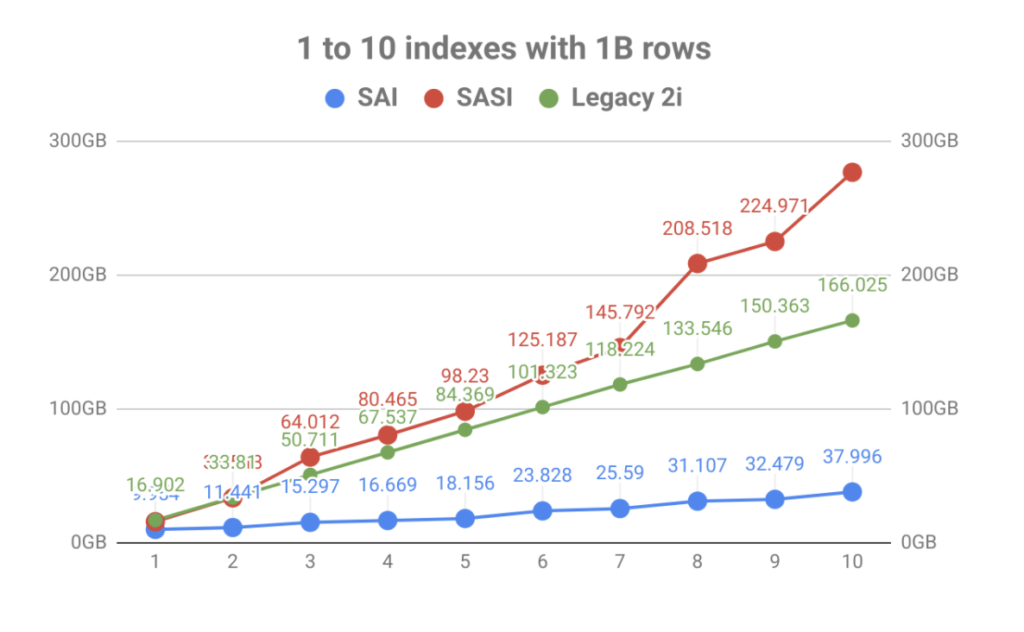
Außerhalb der Schreibverstärkung und Indexgröße ermöglicht die interne Architektur von SAI eine weitere Erweiterung und zusätzliche Funktionalität in der Zukunft. Dies steht im Einklang mit den Projektzielen, in zukünftigen Builds modularer zu sein. Schauen Sie sich einige der anderen Steinpilze an, die noch ausstehen, und Sie können sehen, dass dies nur der Anfang ist.
Wohin geht SAI von hier aus?
DataStax hat dem Apache Cassandra-Projekt ORKB über den Cassandra Enhancement Process als CEP-7 angeboten. Die Diskussion ist jetzt für die Aufnahme in die 4.x Zweig von Cassandra.
Wenn Sie dies jetzt ausprobieren möchten, bevor es Teil des Apache Cassandra-Projekts ist, haben wir ein paar Orte für Sie. Für Betreiber oder Leute, die ein wenig mehr technische Hands-on mögen, können Sie die neueste DataStax Enterprise 6.8 herunterladen. Wenn Sie Entwickler sind, ist SAI jetzt in DataStax Astra, unserem Cassandra as a Service, aktiviert. Sie können eine für immer kostenlose Stufe erstellen, um mit der Syntax und der neuen where-Klausel-Funktionalität herumzuspielen. Erfahren Sie, wie Sie diese Funktion verwenden, indem Sie auf die Seite Cassandra Indexing Skills und die mitgelieferte Dokumentation gehen.