onlangs is er een nieuw wijzigingsvoorstel voor Cassandra indexing geweest dat probeert de afweging tussen bruikbaarheid en stabiliteit te verminderen: waardoor de WHERE-clausule veel interessanter en nuttiger wordt voor eindgebruikers. Deze nieuwe methode heet Storage-Attached Indexing (SAI). Het is niet de meest opzienbarende naam, maar wat verwacht je? Ingenieurs staan niet bekend om het benoemen van dingen, maar coole technologie is nooit een grap. SAI heeft de aandacht van de Cassandra gemeenschap getrokken, maar waarom? Het indexeren van gegevens is geen nieuw concept in de databasewereld.
hoe we onze gegevens indexeren kan in de loop van de tijd veranderen op basis van de gewenste use cases en implementatiemodellen. Cassandra werd gebouwd door aspecten van Dynamo en Big Table te combineren om de complexiteit van lezen en schrijven overhead te verminderen door de dingen eenvoudig te houden. De complexiteit van Cassandra is meestal gereserveerd voor de gedistribueerde aard en als gevolg daarvan, creëerde een afweging voor ontwikkelaars. Als je de ongelooflijke schaal van Cassandra wilt, moet je de tijd besteden aan het leren van datamodellen. Database indexen zijn bedoeld om uw gegevensmodel te verbeteren en uw query ‘ s efficiënter te maken. Voor Cassandra bestaan ze al sinds het begin van het project. De ongelukkige realiteit is dat ze niet goed afgestemd op de eisen van de gebruiker. Elk gebruik van indexering wordt geleverd met een lange lijst van afwegingen en waarschuwingen op het punt dat ze meestal worden vermeden en voor sommigen, gewoon een harde Nee. Als gevolg daarvan, gebruikers hebben geleerd hoe gegevensmodel met basis query ‘ s om de beste prestaties te krijgen.
deze dagen kunnen achter ons liggen en functies zoals SAI helpen ons daar te komen.
secundaire indexen in gedistribueerde databases
niet alle indexen zijn gelijk. Primaire indexen zijn ook bekend als de unieke sleutel, of in Cassandra vocabulaire, partitie sleutel. Als een primaire toegangsmethode op de database gebruikt Cassandra de partitiesleutel om het knooppunt te identificeren dat de gegevens bevat en vervolgens het gegevensbestand dat de partitie van gegevens opslaat. Primaire index leest in Cassandra zijn vrij eenvoudig, maar buiten het toepassingsgebied van dit artikel. U kunt hier meer over lezen.
secundaire indexen creëren een geheel andere en unieke uitdaging in een gedistribueerde database. Laten we eens kijken naar een voorbeeld tabel om een paar punten te maken:
TABELGEBRUIKERS aanmaken (
id lang,
voornaam tekst,
achternaam tekst,
land tekst,
aangemaakt tijdstempel,
primaire sleutel (id)
);
een primaire index opzoeken zou vrij eenvoudig zijn als volgt:
selecteer Voornaam, Achternaam van gebruikers waar id = 100;
wat als ik iedereen in Frankrijk wilde vinden? Als iemand die bekend is met SQL, zou je verwachten dat deze query werkt:
selecteer Voornaam, Achternaam van gebruikers waarbij country = ‘FR’;
zonder een secundaire index aan te maken in Cassandra, zal deze query mislukken. Het fundamentele toegangspatroon in Cassandra is per partitiesleutel. In een niet-gedistribueerde database zoals een traditionele RDBMS, is elke kolom van de tabel gemakkelijk zichtbaar voor het systeem. U kunt nog steeds toegang tot de kolom, zelfs als er geen index, omdat ze allemaal bestaan in hetzelfde systeem en gegevensbestanden. Indexen in dit geval helpen verminderen query tijd door het maken van de lookup efficiënter.
in een gedistribueerd systeem zoals Cassandra bevinden de kolomwaarden zich op elk gegevensknooppunt en moeten ze worden opgenomen in het query-plan. Dit stelt wat we noemen de “Scatter-verzamelen” scenario waarin een query wordt verzonden naar elk knooppunt, gegevens worden verzameld, samengevoegd, en teruggestuurd naar de gebruiker. Hoewel deze bewerking over meerdere knooppunten tegelijk kan worden uitgevoerd, is het latencybeheer beperkt tot hoe snel het knooppunt de kolomwaarde kan vinden.
snel overzicht van Cassandra data schrijft
u denkt misschien dat het toevoegen van indexen gaat over het lezen van gegevens, wat zeker het einddoel is. Echter, bij het bouwen van een database de technische uitdagingen op het indexeren zijn bevooroordeeld op het punt waar de gegevens worden geschreven. Het accepteren van de gegevens op de snelste snelheid, terwijl het formatteren van de indexen in de meest optimale vorm voor leest is een enorme uitdaging. Het is de moeite waard om snel te bekijken hoe gegevens in een Cassanda-database worden geschreven op het niveau van de individuele knooppunten. Refereer naar het volgende diagram als ik uitleg hoe het werkt.
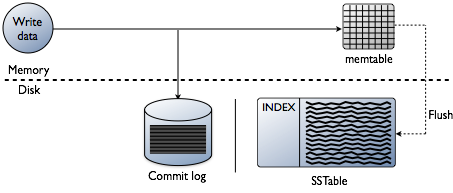
wanneer gegevens worden gepresenteerd aan een knoop, die we een mutatie noemen, is het schrijfpad voor Cassandra zeer eenvoudig en geoptimaliseerd voor die operatie. Dit geldt ook voor veel andere databases gebaseerd op Log-Structured Merge(LSM) bomen.
- gegevens valideren is het juiste formaat. Typ controle op basis van het schema.
- schrijf data in de staart van een commit log. Geen zoekopdrachten, alleen de volgende plek op de file pointer.
- schrijf gegevens in een memtable, wat slechts een hashmap is van het schema in het geheugen.
klaar! De mutatie wordt erkend als die dingen gebeuren. Ik hou van hoe eenvoudig Dit is in vergelijking met andere databases die een slot vereisen en proberen om een schrijven uit te voeren.
later, als de memtables fysiek geheugen vullen, schrijft een spoelproces segmenten uit in een enkele pas op de schijf naar een bestand genaamd een SSTable (gesorteerde Strings Table). De bijbehorende commit log wordt verwijderd nu de persistence is verplaatst naar de SSTable. Dit proces blijft herhalen als gegevens naar het knooppunt worden geschreven.
belangrijk detail: SSTables zijn onveranderlijk. Als ze eenmaal geschreven zijn, worden ze nooit bijgewerkt, alleen vervangen. Uiteindelijk, als meer gegevens worden geschreven, een achtergrond proces genaamd compactie fuseert en sorteert sstables in nieuwe die ook onveranderlijk zijn. Er zijn veel verdichtingsschema ‘ s, maar fundamenteel, ze allemaal deze functie uit te voeren.
je hebt nu genoeg basis basis op Cassandra zodat we voldoende nerdy kunnen worden met indexen. Elke verdere diepte van informatie wordt overgelaten als een oefening voor de lezer.
problemen met eerdere indexering
Cassandra heeft twee eerdere secundaire indexeringsimplementaties gehad. Opslag bijgevoegde secundaire indexering (SASI)en secundaire indexen, die we verwijzen naar 2i. nogmaals, mijn punt over ingenieurs niet flitsend met namen houdt hier. Secundaire indexen zijn vanaf het begin een deel van Cassandra geweest, maar de implementaties hebben ze lastig gemaakt voor eindgebruikers met hun lange lijst van afwegingen. De twee belangrijkste zorgen die we voortdurend hebben behandeld als een project zijn schrijven versterking en index grootte op schijf. Als gevolg daarvan kunnen ze frustrerend verleidelijk zijn voor nieuwe gebruikers alleen om ze later in de implementatie te laten mislukken. Laten we naar elk kijken.
secundaire indexen — 2i) – dit oorspronkelijke werk in het project begon als een comfortfunctie voor vroege Spaargegevens modellen. Later, als Cassandra Query Language vervangen Thrift als de voorkeur query methode voor Cassandra, 2i functionaliteit werd behouden met de “CREATE INDEX” syntaxis. Als je van SQL was gekomen, was dit een heel eenvoudige manier om de wet van onbedoelde gevolgen te leren. Net als in SQL-indexering, hoe meer je toevoegt, hoe meer je schrijfprestaties beïnvloedt. Echter, met Cassandra, dit leidde tot het grotere probleem met schrijf-versterking. Verwijzend naar het schrijfpad hierboven, hebben secundaire indexen een nieuwe stap toegevoegd aan het pad. Wanneer een mutatie op een geïndexeerde kolom optreedt, wordt een indexeringsoperatie geactiveerd die gegevens opnieuw indexeert in een afzonderlijk indexbestand. Meer indexen op een tabel kunnen de schijfactiviteit drastisch verhogen in een enkele rij schrijfbewerking. Wanneer een knoop een hoge hoeveelheid veranderingen neemt, kan het resultaat verzadigde schijfactiviteit zijn die de individuele knopen onstabiel kan maken, gevend 2i de verdiende begeleiding van “gebruik spaarzaam.”Index grootte is vrij lineair in deze implementatie, maar met re-indexering, de hoeveelheid benodigde schijfruimte kan moeilijk te plannen voor in een actieve cluster.
Storage Attached Secondary Indexing — SASI) – SASI is oorspronkelijk ontworpen door een klein team bij Apple om een specifiek query-probleem op te lossen en niet het algemene probleem van secundaire indexen. Om eerlijk te zijn naar dat team, het ontkwam hen in een use case die het nooit was ontworpen om op te lossen. Welkom bij open source iedereen. De twee query types die SASI is ontworpen om aan te pakken:
- rijen vinden op basis van gedeeltelijke gegevensvergelijking. Wildcard, of zoals queries.
- Range queries op schaarse gegevens, in het bijzonder tijdstempels. Hoeveel records passen in een tijdbereik type queries.
het deed beide operaties vrij goed en het behandelde ook het probleem van schrijfversterking met legacy 2i. aangezien mutaties worden gepresenteerd aan een Cassandra node, worden de gegevens geïndexeerd in het geheugen tijdens het eerste schrijven, net als hoe memtables worden gebruikt. Er is geen schijfactiviteit vereist op een permutatie. Een enorme verbetering op clusters met veel schrijfactiviteit. Als memtables naar sstables worden gespoeld, wordt de bijbehorende index voor de data gespoeld. Elk indexbestand geschreven is onveranderlijk en gekoppeld aan de sstable, vandaar de naam opslag bijgevoegd. Wanneer verdichting optreedt, worden gegevens opnieuw geà ndexeerd en naar een nieuw bestand geschreven als nieuwe sstables worden aangemaakt. Vanuit een disk activiteit standpunt, dit was een belangrijke verbetering. Het nadeel van SASI was vooral in de grootte van de indexen gemaakt. De on-disk index formaat veroorzaakt een enorme hoeveelheid schijfruimte gebruikt voor elke geïndexeerde kolom. Dit maakt ze zeer moeilijk te beheren voor exploitanten. Bovendien, SASI werd gemarkeerd als experimenteel en er is niet veel gebeurd met betrekking tot verbetering voorzien. Veel bugs zijn in de loop van de tijd gevonden met dure oplossingen die hebben geleid tot de discussie over de vraag of SASI helemaal moet worden verwijderd. Als je de diepste duik op deze functie nodig hebt, heeft Duy Hai Doan geweldig werk verricht door te breken hoe SASI werkt.
wat SAI beter maakt
het eerste, beste antwoord op die vraag is dat SAI evolutionair van aard is. Ingenieurs van DataStax realiseerden zich dat de kernarchitectuur van secundaire indexering vanaf de grond af moest worden aangepakt, maar met solide lessen die zijn geleerd van eerdere implementaties. Het aanpakken van de problemen van schrijven-versterking en index Bestandsgrootte, terwijl het creëren van een pad voor betere query verbeteringen in Cassandra is de primaire missie geweest. Hoe behandelt SAI beide onderwerpen?
Schrijfversterking – zoals we hebben geleerd van SASI, was het indexeren en spoelen van indexen met SSTables de juiste manier om in lijn te blijven met hoe het Cassandra schrijfpad werkt, terwijl nieuwe functionaliteit werd toegevoegd. Bij SAI worden de gegevens geïndexeerd wanneer de mutatie wordt erkend, wat betekent dat ze volledig zijn gecommitteerd. Met optimalisaties en veel testen is de impact op de schrijfprestaties enorm verbeterd. Je zou beter moeten zien dan een 40% toename in doorvoersnelheid en meer dan 200% betere schrijf latenties over 2i. dat gezegd hebbende, je zou nog steeds moeten plannen op een toename van 2x latentie en doorvoersnelheid op geïndexeerde tabellen in vergelijking met niet-geïndexeerde tabellen. Om Duy Hai Doan te citeren, “er is geen magie,” alleen goede techniek.
Indexgrootte-dit is de meest dramatische verbetering waar het meeste werk is verricht. Als je de wereld van de database internals te volgen, Weet je dat de opslag van gegevens is nog steeds een levendig gebied gevuld met voortdurend evoluerende verbeteringen. SAI maakt gebruik van twee verschillende soorten indexeringsschema ‘ s op basis van het gegevenstype.
- geïnverteerde indexen worden gemaakt met termen die in een woordenboek zijn opgesplitst. De grootste verbetering is van het gebruik van Trie gebaseerde indexering die biedt veel betere compressie wat betekent kleinere indexgroottes.
- numeriek-gebruikmakend van een datastructuur genaamd blok KD-trees, afkomstig van Lucene, die uitstekende prestaties biedt op het gebied van range query. Er wordt een aparte rij-ID-lijst onderhouden om tokenvolgorde-query ‘ s te optimaliseren.
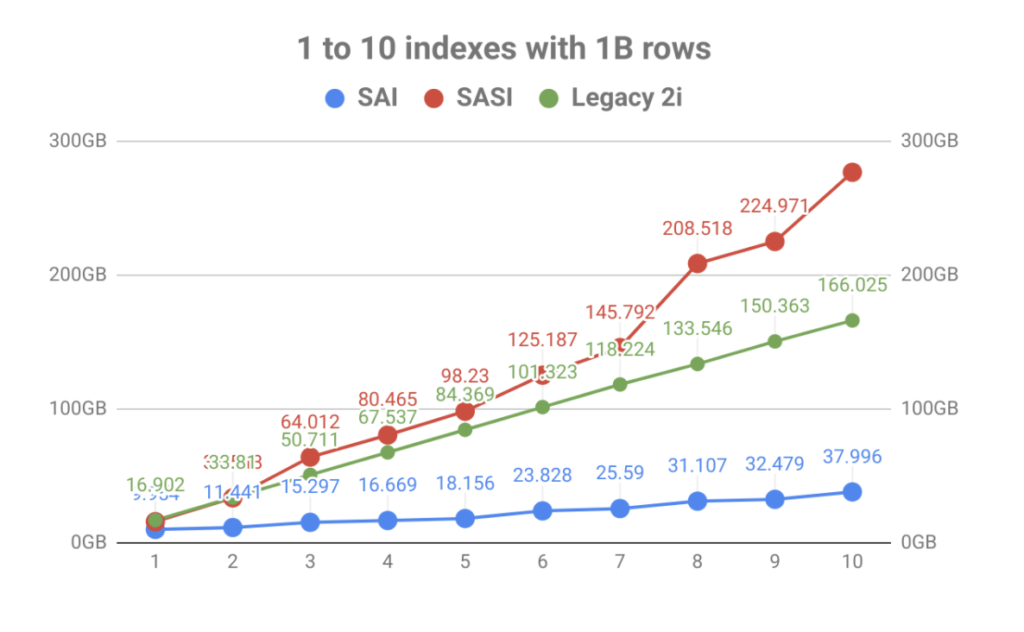
met een sterke nadruk op indexopslag was het resultaat een enorme verbetering van het volume ten opzichte van het aantal tabelindexen. Zoals u in de grafiek hieronder kunt zien, werd de snelle indexering gebracht door SASI snel overschaduwd door de explosie van schijfgebruik. Niet alleen maakt het operationele planning een pijn, maar de index bestanden moesten worden gelezen tijdens verdichting gebeurtenissen die kon verzadigen schijven leiden tot node prestaties problemen.
Buiten write amplification en index grootte, de interne architectuur van SAI zorgt voor verdere uitbreiding en toegevoegde functionaliteit in de toekomst. Dit is in lijn met de projectdoelstellingen om meer modulair te zijn in toekomstige builds. Neem een kijkje op een aantal van de andere CEP ‘ s die in behandeling zijn en je kunt zien dat dit nog maar het begin.
Waar gaat SAI heen vanaf hier?
DataStax heeft SAI aangeboden aan het Apache Cassandra project via het Cassandra Enhancement proces als CEP-7. De discussie is nu voor opname in de 4.x tak van Cassandra.
als je dit nu wilt proberen voordat het deel uitmaakt van het Apache Cassandra project, hebben we een paar plaatsen waar je naartoe kunt. Voor operators of mensen die graag een beetje meer technische hands-on, kunt u de nieuwste DataStax Enterprise 6.8 downloaden. Als u een ontwikkelaar bent, is SAI nu ingeschakeld in DataStax Astra, onze Cassandra as a Service. U kunt een free-forever tier maken om te spelen met syntaxis en nieuwe where-clausule functionaliteit. Hiermee, leer hoe u deze functie te gebruiken door te gaan naar de Cassandra Indexing Skills pagina en opgenomen documentatie.