Vad är Klusteranalysen?
klusteranalys är en undersökande analys som försöker identifiera strukturer i data. Klusteranalys kallas också segmenteringsanalys eller taxonomianalys. Mer specifikt försöker den identifiera homogena grupper av fall om grupperingen inte tidigare är känd. Eftersom det är utforskande gör det ingen skillnad mellan beroende och oberoende variabler. De olika klusteranalysmetoderna som SPSS erbjuder kan hantera binär, nominell, ordinär och skala (intervall eller Förhållande) data.
klusteranalys används ofta tillsammans med andra analyser (såsom diskriminantanalys). Forskaren måste kunna tolka klusteranalysen baserat på deras förståelse av data för att avgöra om resultaten som produceras av analysen faktiskt är meningsfulla.
typiska forskningsfrågor klusteranalysens svar är följande:
- medicin – Vad är diagnostiska kluster? För att svara på denna fråga skulle forskaren utforma ett diagnostiskt frågeformulär som innehåller möjliga symtom (till exempel inom psykologi, ångest, depression etc.). Klusteranalysen kan sedan identifiera grupper av patienter som har liknande symtom.
- marknadsföring – vilka är kundsegmenten? För att svara på denna fråga kan en marknadsundersökare genomföra en undersökning som täcker kundernas behov, attityder, demografi och beteende. Forskaren kan sedan använda klusteranalys för att identifiera homogena grupper av kunder som har liknande behov och attityder.
- utbildning – Vad är studentgrupper som behöver särskild uppmärksamhet? Forskare kan mäta psykologiska, lämplighet, och prestationsegenskaper. En klusteranalys kan då identifiera vilka homogena grupper som finns bland studenter (till exempel högpresterande i alla ämnen eller studenter som utmärker sig i vissa ämnen men misslyckas i andra).
- biologi-Vad är artens taxonomi? Forskare kan samla in en dataset av olika växter och notera olika attribut av deras fenotyper. En klusteranalys kan gruppera dessa observationer i en serie kluster och hjälpa till att bygga en taxonomi av grupper och undergrupper av liknande växter.
andra tekniker som du kanske vill prova för att identifiera liknande grupper av observationer är Q-analys, multidimensionell skalning (MDS) och latent klassanalys.
Klusteranalysen i SPSS
vår forskningsfråga för detta exempel klusteranalys är följande:
vilka homogena kluster av studenter dyker upp baserat på standardiserade testresultat i matematik, läsning och skrivning?
i SPSS kan Klusteranalyser hittas i Analysera / klassificera…. SPSS erbjuder tre metoder för klusteranalysen: K-betyder kluster, hierarkiskt kluster och tvåstegs kluster.
K – betyder kluster är en metod för att snabbt kluster stora datamängder. Forskaren definierar antalet kluster i förväg. Detta är användbart för att testa olika modeller med ett annat antaget antal kluster.
hierarkiskt kluster är den vanligaste metoden. Det genererar en serie modeller med klusterlösningar från 1 (alla fall i ett kluster) till n (varje fall är ett enskilt kluster). Hierarkiskt kluster fungerar också med variabler i motsats till fall; det kan klustera variabler tillsammans på ett sätt som liknar faktoranalys. Dessutom kan hierarkisk klusteranalys hantera nominella, ordinära och skaldata; det rekommenderas dock inte att blanda olika mätnivåer.
tvåstegs klusteranalys identifierar grupperingar genom att köra förklustring först och sedan genom att köra hierarkiska metoder. Eftersom den använder en snabb klusteralgoritm på förhand kan den hantera stora datamängder som skulle ta lång tid att beräkna med hierarkiska klustermetoder. I detta avseende är det en kombination av de två föregående metoderna. Tvåstegs kluster kan hantera skala och ordinära data i samma modell, och det väljer automatiskt antalet kluster.
den hierarkiska klusteranalysen följer tre grundläggande steg: 1) Beräkna avstånden, 2) länka klusterna och 3) Välj en lösning genom att välja rätt antal kluster.
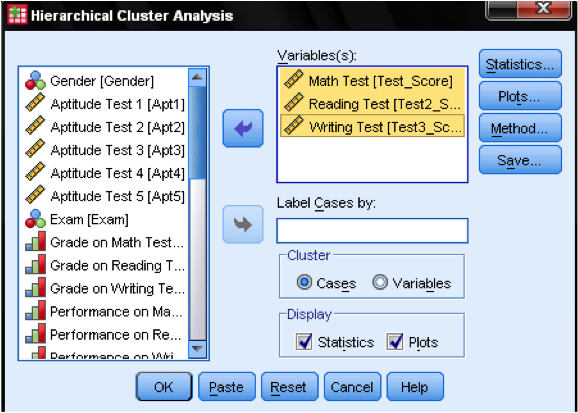
först måste vi välja de variabler som vi baserar våra kluster på. I dialogfönstret lägger vi till matte -, läs-och skrivtest i listan över variabler. Eftersom vi vill klustera fall lämnar vi resten av kryssmarkeringarna på standard.
i dialogrutan statistik … kan vi ange om vi vill mata ut närhetsmatrisen (det här är avstånden som beräknas i analysens första steg) och det förutsagda klustermedlemskapet i fallen i våra observationer. Återigen lämnar vi alla inställningar på standard.

i dialogrutan tomter … bör vi lägga till Dendrogrammet. Dendrogrammet visar grafiskt hur klusterna slås samman och låter oss identifiera vad lämpligt antal kluster är.
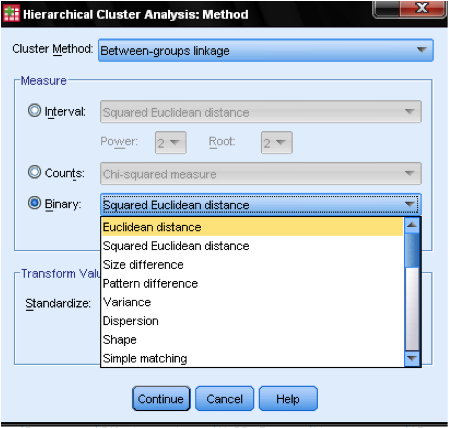
dialogrutan metod … tillåter oss att ange avståndsmått och klustringsmetod. Först måste vi definiera rätt avståndsåtgärd. SPSS erbjuder tre stora block av avståndsåtgärder för intervall (skala), räkningar (ordinära) och binära (nominella) data.
för intervalldata är det vanligaste kvadratiska euklidiska avståndet. Det är baserat på det euklidiska avståndet mellan två observationer, vilket är kvadratroten av summan av kvadrerade avstånd. Eftersom det euklidiska avståndet är kvadratiskt ökar det vikten av stora avstånd, samtidigt som vikten av små avstånd försvagas.

om vi har ordinära data (räkningar) kan vi välja mellan Chi-kvadrat eller en standardiserad Chi-kvadrat som kallas Phi-kvadrat. För binära data används det kvadrerade euklidiska avståndet vanligtvis.

i vårt exempel väljer vi intervall och kvadratiskt euklidiskt avstånd.
Därefter måste vi välja Klustermetoden. Vanligtvis är val mellan grupper koppling (avståndet mellan kluster är det genomsnittliga avståndet för alla datapunkter inom dessa kluster), närmaste granne (enkel koppling: avståndet mellan kluster är det minsta avståndet mellan två datapunkter), längst granne (komplett koppling: avståndet är det största avståndet mellan två datapunkter) och Ward metod (avstånd är avståndet för alla kluster till det stora genomsnittet av provet). Enkel koppling fungerar bäst med långa kedjor av kluster, medan fullständig koppling fungerar bäst med täta klumpar av kluster. Koppling mellan grupper fungerar med båda klustertyperna. Det rekommenderas är att använda enda koppling först. Även om enstaka koppling tenderar att skapa kedjor av kluster, hjälper det att identifiera avvikare. Efter att ha uteslutit dessa avvikare kan vi gå vidare till Wards metod. Wards metod använder F-värdet (som i ANOVA) för att maximera betydelsen av skillnader mellan kluster.
ett sista övervägande är standardisering. Om variablerna har olika skalor och betyder att vi kanske vill standardisera antingen till Z-poäng eller genom att centrera skalan. Vi kan också omvandla värdena till absoluta värden om vi har en datamängd där detta kan vara lämpligt.