ce este analiza Cluster?
analiza Cluster este o analiză exploratorie care încearcă să identifice structurile din date. Analiza clusterului se mai numește analiză de segmentare sau analiză taxonomică. Mai precis, încearcă să identifice grupuri omogene de cazuri dacă gruparea nu este cunoscută anterior. Deoarece este exploratorie, nu face nicio distincție între variabilele dependente și cele independente. Diferitele metode de analiză a clusterului pe care SPSS le oferă pot gestiona date binare, nominale, ordinale și la scară (interval sau raport).
analiza Cluster este adesea utilizată împreună cu alte analize (cum ar fi analiza discriminantă). Cercetătorul trebuie să poată interpreta analiza clusterului pe baza înțelegerii datelor pentru a determina dacă rezultatele produse de analiză sunt de fapt semnificative.
întrebări tipice de cercetare răspunsurile la analiza clusterului sunt următoarele:
- medicină-care sunt grupurile de diagnosticare? Pentru a răspunde la această întrebare, cercetătorul ar elabora un chestionar de diagnostic care să includă posibile simptome (de exemplu, în psihologie, anxietate, depresie etc.). Analiza clusterului poate identifica apoi grupuri de pacienți care au simptome similare.
- Marketing – care sunt segmentele de clienți? Pentru a răspunde la această întrebare, un cercetător de piață poate efectua un sondaj care acoperă nevoile, atitudinile, datele demografice și comportamentul clienților. Cercetătorul poate utiliza apoi analiza clusterului pentru a identifica grupuri omogene de clienți care au nevoi și atitudini similare.
- educație-care sunt grupurile de studenți care au nevoie de o atenție specială? Cercetătorii pot măsura caracteristicile psihologice, de aptitudine și de realizare. O analiză a clusterului poate identifica apoi ce grupuri omogene există în rândul studenților (de exemplu, cu rezultate ridicate la toate disciplinele sau studenți care excelează la anumite discipline, dar nu reușesc la altele).
- biologie – care este taxonomia speciilor? Cercetătorii pot colecta un set de date de plante diferite și pot nota diferite atribute ale fenotipurilor lor. O analiză a clusterelor poate grupa aceste observații într-o serie de clustere și poate ajuta la construirea unei taxonomii a grupurilor și subgrupurilor de plante similare.
alte tehnici pe care ați putea dori să le încercați pentru a identifica grupuri similare de observații sunt analiza Q, scalarea multidimensională (MDS) și analiza clasei latente.
analiza clusterului în SPSS
întrebarea noastră de cercetare pentru acest exemplu de analiză a clusterului este următoarea:
ce grupuri omogene de studenți apar pe baza scorurilor standardizate la matematică, citire și scriere?
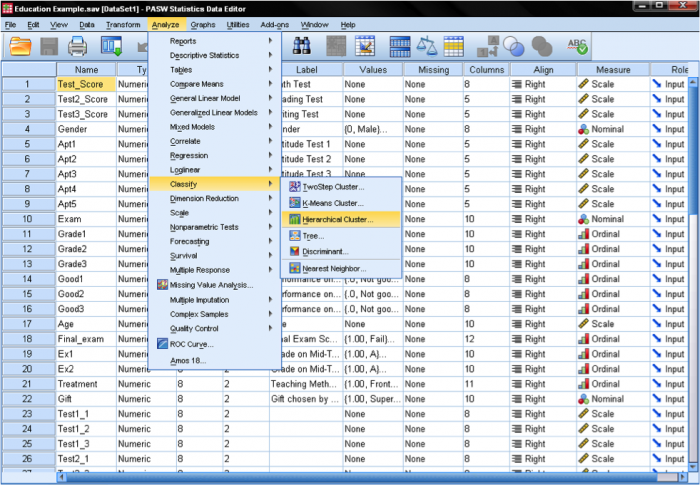
în SPSS analize Cluster pot fi găsite în analiza / clasifica…. SPSS oferă trei metode pentru analiza clusterului: K-înseamnă Cluster, Cluster ierarhic și Cluster în doi pași.
K-înseamnă cluster este o metodă de cluster rapid seturi mari de date. Cercetătorul definește numărul de clustere în avans. Acest lucru este util pentru a testa diferite modele cu un număr presupus diferit de clustere.
cluster ierarhic este cea mai comună metodă. Generează o serie de modele cu soluții de cluster de la 1 (toate cazurile dintr-un cluster) la n (fiecare caz este un cluster individual). Cluster ierarhic funcționează, de asemenea, cu variabile, spre deosebire de cazuri; se poate cluster variabile împreună într-un mod oarecum similar cu analiza factorilor. În plus, analiza ierarhică a clusterului poate gestiona datele nominale, ordinale și la scară; cu toate acestea, nu se recomandă amestecarea diferitelor niveluri de măsurare.
analiza cluster în doi pași identifică grupările rulând mai întâi pre-clustering și apoi rulând metode ierarhice. Deoarece folosește un algoritm de cluster rapid în avans, poate gestiona seturi mari de date care ar dura mult timp pentru a calcula cu metode de cluster ierarhice. În acest sens, este o combinație a celor două abordări anterioare. Gruparea în doi pași poate gestiona datele la scară și ordinale în același model și selectează automat numărul de clustere.
analiza ierarhică a clusterului urmează trei pași de bază: 1) Calculați distanțele, 2) legați clusterele și 3) Alegeți o soluție selectând numărul corect de clustere.
în primul rând, trebuie să selectăm variabilele pe care ne bazăm clusterele. În fereastra de dialog adăugăm testele de matematică, citire și scriere la lista variabilelor. Deoarece dorim să grupăm cazuri, lăsăm restul marcajelor de bifare în mod implicit.
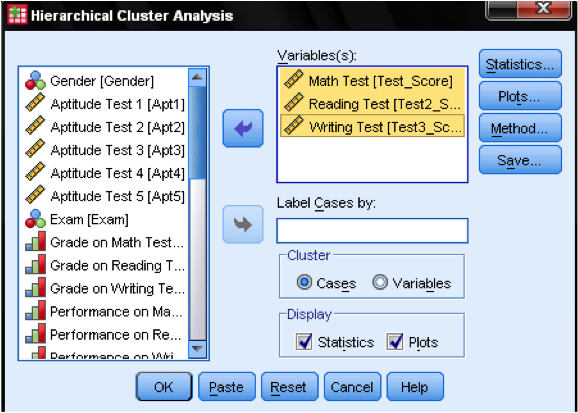
în caseta de dialog statistici … putem specifica dacă dorim să scoatem matricea de proximitate (acestea sunt distanțele calculate în prima etapă a analizei) și apartenența clusterului prezis a cazurilor din observațiile noastre. Din nou, lăsăm toate setările implicite.

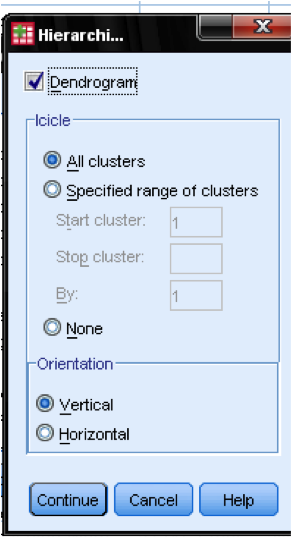
în caseta de dialog Ploturi … ar trebui să adăugăm Dendrograma. Dendrograma va arăta grafic modul în care clusterele sunt îmbinate și ne permite să identificăm care este numărul adecvat de clustere.
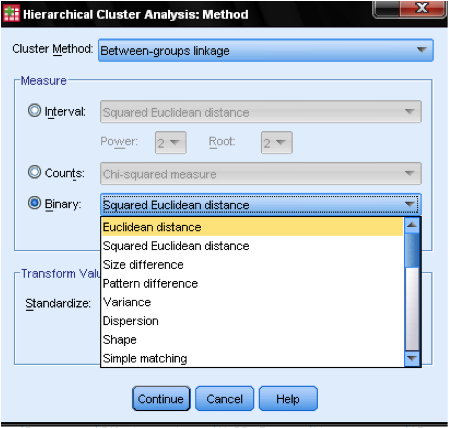
metoda casetei de dialog … ne permite să specificăm măsura distanței și metoda de grupare. În primul rând, trebuie să definim măsura corectă a distanței. SPSS oferă trei blocuri mari de măsuri de distanță pentru interval (scară), numărătoare (ordinal) și date binare (nominale).
pentru datele de interval, cea mai comună este distanța euclidiană pătrată. Se bazează pe distanța euclidiană dintre două observații, care este rădăcina pătrată a sumei distanțelor pătrate. Deoarece distanța euclidiană este pătrată, crește importanța distanțelor mari, slăbind în același timp importanța distanțelor mici.

dacă avem date ordinale (numărătoare) putem selecta între Chi-pătrat sau un Chi-pătrat standardizat numit Phi-pătrat. Pentru datele binare, distanța euclidiană pătrată este frecvent utilizată.

în exemplul nostru, alegem intervalul și distanța euclidiană pătrată.
apoi, trebuie să alegem metoda clusterului. De obicei, alegerile sunt legătura între grupuri (distanța dintre clustere este distanța medie a tuturor punctelor de date din aceste clustere), cel mai apropiat vecin (legătură unică: distanța dintre clustere este cea mai mică distanță dintre două puncte de date), cel mai îndepărtat vecin (legătură completă: distanța este cea mai mare distanță dintre două puncte de date) și metoda lui Ward (distanța este distanța tuturor clusterelor până la Marea medie a eșantionului). Legătura unică funcționează cel mai bine cu lanțuri lungi de clustere, în timp ce legătura completă funcționează cel mai bine cu pete dense de clustere. Legătura între grupuri funcționează cu ambele tipuri de cluster. Este recomandat să utilizați mai întâi o singură legătură. Deși legătura unică tinde să creeze lanțuri de clustere, ajută la identificarea valorilor aberante. După excluderea acestor valori aberante, putem trece la metoda lui Ward. Metoda lui Ward folosește valoarea F (ca în ANOVA) pentru a maximiza semnificația diferențelor dintre clustere.
o ultimă considerație este standardizarea. Dacă variabilele au scări diferite și înseamnă că am putea dori să standardizăm fie scorurile Z, fie prin centrarea scalei. De asemenea, putem transforma valorile în valori absolute dacă avem un set de date unde acest lucru ar putea fi adecvat.