this is a step by step guide on how to run k-means cluster analysis on an Excel spreadsheet from start to finish. Por favor, note que existe um modelo Excel que executa automaticamente a análise de cluster disponível para download gratuito neste site. Mas se você quiser saber como executar um K-significa agrupar no Excel você mesmo, então este artigo é para você.
além deste artigo, eu também tenho um vídeo de como executar análise de cluster no Excel.
- Um Passo – Comece com o seu conjunto de dados
- Passo Dois – Se apenas duas variáveis, use um gráfico de dispersão em Excel
- Passo Três-calcular a distância de cada ponto de dados para o centro de um aglomerado
- como funciona o cálculo?
- quarto Passo – Calcular a média (média) de cada conjunto de cluster
- quinto Passo – Repita o Passo 3 – a Distância entre a revista significar
- Etapa Final, o Gráfico e Resumir os Clusters
Um Passo – Comece com o seu conjunto de dados
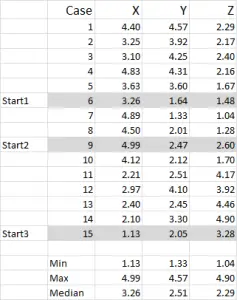
Figura 1
Para este exemplo, eu estou usando 15 casos (ou participantes), onde temos os dados para três variáveis genericamente identificados como X, Y e Z.
Você deve notar que os dados em escala de 1 a 5 neste exemplo. Seus dados podem ser de qualquer forma, exceto por uma escala de dados nominal (por favor, veja o artigo de que dados usar).
nota: eu prefiro usar dados escalados – mas não é obrigatório. A razão para isso é “conter” qualquer estranho. Dizer, por exemplo, eu estou usando a renda (dados demográficos medida) – a maioria dos dados pode ser em torno de us $40.000 us $100.000, mas eu tenho uma pessoa com uma renda de us $5 milhões. É apenas mais fácil para mim para classificar essa pessoa, no “mais de us $250,000” faixa de rendimento e a escala de renda 1-9 – mas o que você consoante os dados que você está trabalhando.
você pode ver a partir deste exemplo definir que três posições de partida foram destacadas – vamos discutir essas no Passo Três abaixo.
Passo Dois – Se apenas duas variáveis, use um gráfico de dispersão em Excel
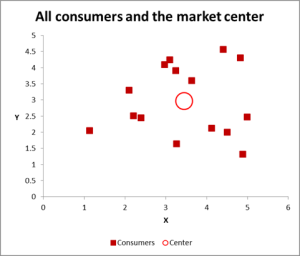
Figura 2
nesta análise de cluster exemplo estamos usando três variáveis, mas se você tiver apenas duas variáveis do cluster e, em seguida, um gráfico de dispersão é uma excelente maneira de começar. E, às vezes, você pode agrupar os dados através de meios visuais.
Como você pode ver neste gráfico de dispersão, cada caso individual (o que eu estou chamando de um consumidor para este exemplo) foi mapeado, juntamente com a média (média aritmética) para todos os casos (o círculo vermelho).
dependendo de como você vê os dados / grafo – parece haver um número de aglomerados. Neste caso, você pode identificar três ou quatro clusters relativamente distintos – como mostrado neste gráfico seguinte.
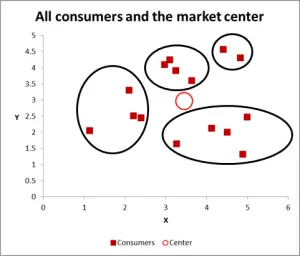
Figura 3
Com este próximo gráfico, tenho visivelmente identificado provável de cluster e circulou-los. Como eu sugeri, uma boa abordagem quando há apenas duas variáveis a considerar – mas é este caso que temos três variáveis (e você poderia ter mais), então esta abordagem visual só vai funcionar para conjuntos de dados básicos – então agora vamos olhar para como fazer o cálculo do Excel para K-significa agrupamento.
Passo Três-calcular a distância de cada ponto de dados para o centro de um aglomerado
para este exemplo de passagem, vamos assumir que queremos identificar apenas três segmentos/aglomerados. Sim, há quatro aglomerados evidentes no diagrama acima, mas que só olha para duas das variáveis. Por favor, note que você pode usar esta abordagem Excel para identificar quantos clusters quiser – basta seguir o mesmo conceito como explicado abaixo.
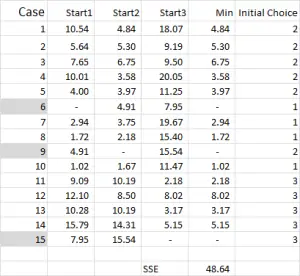
Figura 4
Para o k-means clustering você costuma pegar algumas aleatória de casos (pontos de partida ou sementes) para obter a análise passou.
neste exemplo-como eu estou querendo criar três aglomerados, então eu vou precisar de três pontos de partida. Para estes pontos de partida, seleccionei casos 6, 9 e 15-mas quaisquer pontos aleatórios também poderiam ser adequados.
a razão pela qual selecionei estes casos é porque – ao olhar para a variável X apenas – Caso 6 foi a mediana, o caso 9 foi o máximo e o caso 15 foi o mínimo. Isto sugere que estes três casos são um pouco diferentes uns dos outros, tão bons pontos de partida como eles são espalhados.
por favor, consulte o artigo sobre por que a análise de clusters às vezes gera resultados diferentes.
referindo – se à saída da tabela-Este é o nosso primeiro cálculo no Excel e ele gera a nossa “escolha inicial” de clusters. Start 1 é os dados para o caso 6, start 2 é o caso 9 e start 3 é o caso 15. Você deve notar que a intersecção de cada um destes dá um 0 (-) na tabela.
como funciona o cálculo?
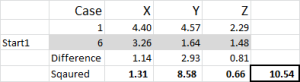
Figura 5
Vamos olhar para o primeiro número na tabela de caso 1, 1 = 10.54.
lembre-se que designamos arbitrariamente o caso 6 para ser o nosso ponto de partida aleatório para o Cluster 1. Queremos calcular a distância e usamos o método da soma dos quadrados-como mostrado aqui. Nós calculamos a diferença entre cada um dos três pontos de dados no conjunto, e então quadramos as diferenças, e então as somamos.
podemos fazê – lo” mecanicamente ” como mostrado aqui-mas o Excel tem uma fórmula incorporada para usar: SUMXMY2 – isto é muito mais eficiente de usar.
referindo – se à figura 4, então encontramos a distância mínima para cada caso de cada um dos três pontos de partida – isto nos diz qual conjunto (1, 2 ou 3) que o caso é mais próximo-que é mostrado na “coluna de escolha inicial”.
quarto Passo – Calcular a média (média) de cada conjunto de cluster
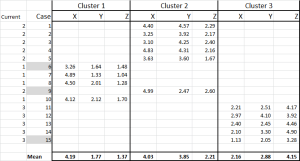
Figura 6
temos agora atribuídos em cada caso para o seu cluster inicial – e podemos estabelecer esse limite usando uma instrução SE uma tabela (como mostrado na Figura 6).
na parte inferior da tabela, Temos a média (média) de cada um destes casos. N0w-em vez de depender apenas de um ponto de dados “representativo” – temos um conjunto de casos representando cada um.
quinto Passo – Repita o Passo 3 – a Distância entre a revista significar
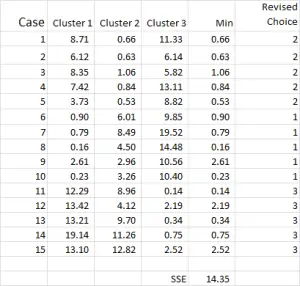
Figura 7
A análise de cluster processo torna-se agora uma questão de repetir os Passos 4 e 5 (iterações), até os clusters estabilizar.
cada vez que usamos a média revista para cada aglomerado. Portanto, a Figura 7 mostra nossa segunda iteração-mas desta vez estamos usando os meios gerados na parte inferior da Figura 6 (em vez dos pontos de partida da Figura 1).
pode agora ver que houve uma ligeira alteração na aplicação de clusters, com o caso 9 – um dos nossos pontos de partida – a ser redistribuído.
você também pode ver a soma do erro quadrado (SSE) calculado na parte inferior – que é a soma de cada uma das distâncias mínimas. Nosso objetivo é agora repetir os passos 4 e 5 até que o SSE só mostra melhoria mínima e/ou as mudanças de alocação de cluster são menores em cada iteração.
Etapa Final, o Gráfico e Resumir os Clusters
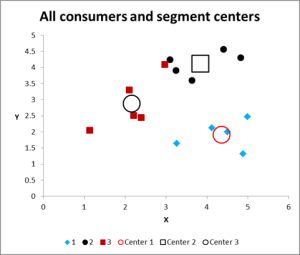
Figura 8
Após a execução de várias iterações, agora temos a saída para o gráfico e resumir os dados.
aqui está o grafo de saída para este exemplo de análise de aglomerado Excel.
como podem ver, existem três aglomerados distintos mostrados, juntamente com os centroids (média) de cada aglomerado – os símbolos maiores.
também podemos apresentar estes dados em uma forma de tabela, se necessário, como temos trabalhado no Excel.
por favor, dê uma olhada no caso no Cluster 3 – o pequeno quadrado vermelho à direita ao lado do ponto preto no meio superior do grafo. Esse caso fica ali por causa da influência da terceira variável, que não é mostrada neste gráfico de duas variáveis.