Recentemente, houve uma nova proposta de mudança para Cassandra indexing que tenta reduzir o tradeoff entre usabilidade e estabilidade: tornando a cláusula onde muito mais interessante e útil para os usuários finais. Este novo método é chamado indexação em anexo ao armazenamento (SAI). Não é o nome mais vistoso, mas o que esperavas? Engenheiros não são conhecidos por nomear coisas, mas Tecnologia legal nunca é uma piada. SAI chamou a atenção da Comunidade Cassandra, mas porquê? Os dados de indexação não são um conceito novo no mundo da base de dados.
como indexamos nossos dados podem mudar ao longo do tempo com base nos casos de uso desejados e modelos de implantação. Cassandra foi construída combinando aspectos do Dínamo e mesa grande para reduzir a complexidade de ler e escrever por cima, mantendo as coisas simples. A complexidade de Cassandra tem sido reservada principalmente à sua natureza distribuída e, como resultado, criou um tradeoff para desenvolvedores. Se você quer a incrível escala de Cassandra, você tem que passar o tempo aprendendo como modelar dados. Os índices de banco de dados são destinados a melhorar o seu modelo de dados e tornar as suas consultas mais eficientes. Para Cassandra, eles existem de alguma forma desde os primeiros dias do projeto. A infeliz realidade é que eles não têm correspondido bem com os requisitos do Usuário. Qualquer uso de indexação vem com uma longa lista de tradeoffs e avisos ao ponto de que eles são principalmente evitados e para alguns, apenas um duro não. Como resultado, os usuários aprenderam a modelar dados com consultas básicas para obter o melhor desempenho. Esses dias podem estar ficando para trás e características como SAI estão nos ajudando a chegar lá.
índices secundários em bases de dados distribuídas
nem todos os índices são criados iguais. Os índices primários também são conhecidos como a chave única, ou no vocabulário Cassandra, chave de partição. Como um método de acesso primário no banco de dados, Cassandra utiliza a chave de partição para identificar o nó segurando os dados, em seguida, o arquivo de dados que armazena a partição de dados. O índice primário lê em Cassandra são bastante simples, mas além do escopo deste artigo. Você pode ler mais sobre eles aqui.
os índices secundários criam um desafio completamente diferente e único em uma base de dados distribuída. Vejamos um exemplo de tabela para fazer alguns pontos:
CRIAR TABELA de usuários (
id do longa,
texto nome,
sobrenome de texto,
país de texto,
criado carimbo de data / hora
PRIMARY KEY (id)
);
Um índice primário de pesquisa seria muito simples como este:
SELECT nome, sobrenome FROM utilizadores WHERE id = 100;
o Que se queria encontrar todos na França? Como alguém familiarizado com SQL, você esperaria que esta consulta funcionasse:
seleccione o primeiro nome, o último nome dos utilizadores onde o país = ‘FR’;
sem criar um índice secundário em Cassandra, esta consulta irá falhar. O padrão de acesso fundamental em Cassandra é por chave de partição. Em um banco de dados não distribuído como um RDBMS tradicional, cada coluna da tabela é facilmente visível para o sistema. Você ainda pode acessar a coluna, mesmo que não haja nenhum índice, uma vez que todos eles existem no mesmo sistema e arquivos de dados. Os índices neste caso ajudam a reduzir o tempo de consulta, tornando a pesquisa mais eficiente.
em um sistema distribuído como Cassandra, os valores da coluna estão em cada nó de dados e devem ser incluídos no plano de consulta. Isto configura o que chamamos de “Scatter-Gather” cenário onde uma consulta é enviada para cada nó, os dados são coletados, mesclados e retornados ao usuário. Mesmo que esta operação possa ser feita através de vários nós de uma vez, a gestão de latência é baixo para a velocidade que o nó pode encontrar o valor da coluna.
Revisão Rápida de Cassandra data escreve
você pode estar pensando que adicionar índices é sobre a leitura de dados, que é certamente o objetivo final. No entanto, ao construir uma base de dados, os desafios técnicos da indexação são tendenciosos no ponto em que os dados são escritos. Aceitar os dados na velocidade mais rápida enquanto formatar os índices na forma mais ótima para leitura é um grande desafio. Vale a pena fazer uma rápida revisão de como os dados são escritos em uma base de dados Cassanda no nível de nó individual. Consulte o seguinte diagrama à medida que eu explico como ele funciona.
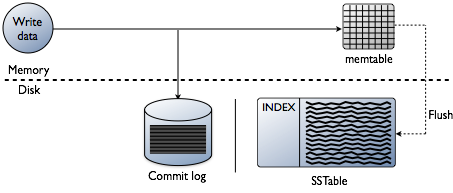
quando os dados são apresentados a um nó, que chamamos de mutação, o caminho de escrita para Cassandra é muito simples e otimizado para essa operação. Isto também é verdade para muitas outras bases de dados baseadas em árvores Log-Structured Merge(LSM).
- validar dados é o formato correcto. Verifique com o esquema.
- escrever dados na cauda de um registo de commit. Não procura, apenas o próximo lugar no ponteiro do arquivo.
- escrever dados em um memtable, que é apenas um hashmap do esquema na memória. Feito! A mutação é reconhecida quando essas coisas acontecem. Adoro o quão simples isto é comparado com outras bases de dados que requerem um bloqueio e procuram realizar uma escrita.
Later, as the memtables fill physical memory, a flush process writes out segments in a single pass on disk to a file called an SSTable (tried Strings Table). O registro de commit que acompanha é apagado agora que a persistência se moveu para o SSTable. Este processo continua repetindo enquanto os dados são escritos no nó.
detalhe importante: SSTables são imutáveis. Uma vez escritos, eles nunca são atualizados, apenas substituídos. Eventualmente, como mais dados são escritos, um processo de fundo chamado compactação se funde e ordena sstables em novos que também são imutáveis. Existem muitos esquemas de compactação, mas fundamentalmente, todos eles desempenham esta função.Agora tens bases básicas suficientes sobre a Cassandra para que possamos ficar suficientemente nerd com os índices. Qualquer profundidade adicional de informação é deixada como um exercício para o leitor.
Issues with previous indexing
Cassandra has had two previous secondary indexing implementations. Armazenamento anexado indexação Secundária (SASI) e índices secundários, que nos referimos como 2i. mais uma vez, meu ponto sobre engenheiros não ser vistoso com nomes se mantém aqui. Os índices secundários têm sido uma parte de Cassandra desde o início, mas as implementações os tornaram problemáticos para os usuários finais com sua longa lista de tradeoffs. As duas principais preocupações que temos constantemente lidado como um projeto são a amplificação de escrita e o tamanho do índice no disco. Como resultado, eles podem ser frustrantemente tentadores para os novos usuários apenas para que eles falham mais tarde na implantação. Vamos olhar para cada um.Secondary Indexes — 2i) – Este trabalho original no projeto começou como uma característica de conveniência para os primeiros modelos de dados de Thrift. Mais tarde, como Cassandra Query Language substituiu Thrift como o método de consulta preferido para Cassandra, funcionalidade 2i foi mantida com a sintaxe “criar índice”. Se você tivesse vindo do SQL, esta era uma maneira realmente fácil de aprender a lei das consequências não intencionais. Assim como na indexação SQL, quanto mais você adiciona mais Você afeta o desempenho de escrita. No entanto, com Cassandra, isso desencadeou o problema maior com a write-amplificação. Referindo-se ao caminho de escrita acima, índices secundários adicionaram um novo passo no caminho. Quando uma mutação em uma coluna indexada ocorre, uma operação de indexação é desencadeada que re-indexa os dados em um arquivo de índice separado. Mais índices em uma tabela podem aumentar dramaticamente a atividade de disco em uma única linha de escrita operação. Quando um nó está tomando uma grande quantidade de mutações, o resultado pode ser a atividade do disco saturado que pode tornar os nós individuais instáveis, dando a 2i a orientação merecida de “usar com moderação”.”O tamanho do índice é bastante linear nesta implementação, mas com a re-indexação, a quantidade de espaço em disco necessária pode ser difícil de planejar em um cluster ativo.
Storage Attached Secondary Indexing (SASI) — SASI was originally designed by a small team at Apple to solve a specific query problem and not the general problem of secondary indexes. Para ser justo com aquela equipa, escapou-lhes num caso de uso que nunca foi concebido para resolver. Bem-vindos ao código aberto. Os dois tipos de consulta que SASI foi projetado para abordar:
- procurar linhas com base na correspondência parcial de dados. Wildcard, ou como consultas.
- Range queries on sparse data, specifically timestamps. Quantos registos se encaixam em consultas de tipo de intervalo de tempo.
fez ambas as operações muito bem e também abordou a questão da amplificação de Escrita com legacy 2i. como as mutações são apresentadas a um nó de Cassandra, os dados são indexados na memória durante a escrita inicial, assim como como como memtables são usados. Não é necessária qualquer actividade de disco numa permutação. Uma enorme melhoria em clusters com muita atividade de escrita. Quando os memtables são despejados para sstables, o índice correspondente para os dados é descarregado. Cada arquivo de índice escrito é imutável e anexado ao sstable, daí o armazenamento de nome anexado. Quando a compactação ocorre, os dados são reindexados e escritos em um arquivo novo como novos sstables são criados. Do ponto de vista da atividade do disco, esta era uma melhoria importante. A desvantagem do SASI estava principalmente no tamanho dos índices criados. O formato de índice no disco causou uma enorme quantidade de espaço em disco usado para cada coluna indexada. Isto torna-os muito difíceis de gerir para os operadores. Além disso, SASI foi marcado como experimental e não muito tem acontecido no que diz respeito à melhoria do recurso. Muitos bugs foram encontrados ao longo do tempo com correções caras que trouxeram a discussão sobre se SASI deve ser removido completamente. Se você precisar do mergulho mais profundo neste recurso, Duy Hai Doan fez um trabalho incrível de quebrar como SASI funciona.
What makes SAI better
the first, best answer to that question is that SAI is evolutionary in nature. Engenheiros da DataStax perceberam que a arquitetura do núcleo da indexação Secundária precisava ser tratada desde o início, mas com sólidas lições que foram aprendidas com implementações anteriores. Abordar as questões de write-amplificação e tamanho de arquivo de índice, ao criar um caminho para melhorias de consulta em Cassandra tem sido a missão principal. Como SAI aborda estes dois temas?Write amplification-As we learned from SASI, in-memory indexing and flushing indexes with SSTables was the right way to keep in line with how the Cassandra write-path works, while adding new functionality. Com SAI, quando a mutação é reconhecida, ou seja, totalmente comprometida, os dados são indexados. Com otimizações e muitos testes, o impacto no desempenho de escrita melhorou muito. Você deve ver melhor do que um aumento de 40% no rendimento e mais de 200% melhor latências de escrita sobre 2i. Dito isto, você ainda deve planejar um aumento de latência 2x e rendimento em tabelas indexadas em comparação com tabelas não indexadas. Para citar Duy Hai Doan,” não há magia”, apenas boa engenharia.
Tamanho do Índice – esta é a melhoria mais dramática e, sem dúvida, onde a maior parte do trabalho foi feito. Se você seguir o mundo dos dados internos, você sabe que o armazenamento de dados ainda é um campo animado cheio de melhorias continuamente em evolução. A SAI utiliza dois tipos diferentes de sistemas de indexação baseados no tipo de dados.
- índices invertidos de texto são criados com termos quebrados em um dicionário. A maior melhoria é a partir do uso de indexação baseada em Trie que oferece uma compressão muito melhor, o que significa tamanhos de índice menores.
- Numeric-Utilizing a data structure called block kd-trees, taken from Lucene, which offers excellent range query performance. Uma lista de ID de linha separada é mantida para otimizar para consultas de ordem de token.
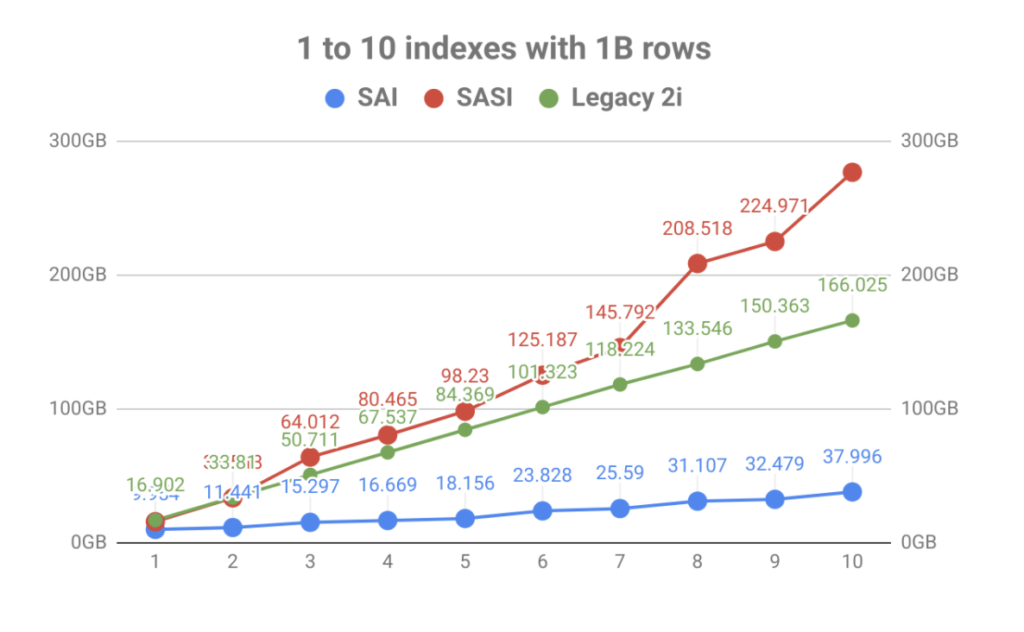
com forte ênfase no armazenamento de índice, o resultado foi uma melhoria maciça no volume vs o número de índices de tabela. Como você pode ver no gráfico abaixo, a indexação rápida trazida por SASI foi rapidamente eclipsada pela explosão do uso do disco. Não só faz do Planejamento Operacional uma dor, mas os arquivos de índice tiveram que ser lidos durante eventos de compactação que poderiam saturar discos levando a problemas de desempenho do nó.
fora da amplificação de escrita e do tamanho do índice, a arquitetura interna da SAI permite uma maior expansão e funcionalidade adicionada no futuro. Isto está em linha com os objetivos do projeto para ser mais modular em futuras construções. Dê uma olhada em alguns dos outros CEPs que estão pendentes e você pode ver que este é apenas o começo. Para onde vai SAI daqui?DataStax ofereceu SAI ao projeto Apache Cassandra através do processo Cassandra Enhancement como CEP-7. A discussão está agora a ser incluída na 4.ramo x da Cassandra.Se você quiser tentar isso agora antes de fazer parte do projeto Apache Cassandra, temos alguns lugares para você ir. Para os operadores ou pessoas que gostam de um pouco mais técnico mãos-on, você pode baixar a última DataStax Enterprise 6.8. Se você é um desenvolvedor, SAI está agora habilitado em DataStax Astra, nossa Cassandra como um serviço. Você pode criar uma lista livre-para-sempre para brincar com sintaxe e nova funcionalidade de cláusula onde. Com isso, aprenda a usar este recurso indo para a Página de habilidades de indexação Cassandra e incluiu documentação.