Hva er Klyngeanalysen?
Cluster analysis Er en utforskende analyse som prøver å identifisere strukturer i dataene. Cluster analyse kalles også segmenteringsanalyse eller taksonomi analyse. Nærmere bestemt forsøker den å identifisere homogene grupper av tilfeller hvis grupperingen ikke er kjent tidligere. Fordi det er utforskende, skiller det ikke mellom avhengige og uavhengige variabler. De forskjellige cluster analysemetoder SOM SPSS tilbyr kan håndtere binære, nominelle, ordinære og skala (intervall eller forhold) data.
Klyngeanalyse brukes ofte sammen med andre analyser (for eksempel diskriminantanalyse). Forskeren må kunne tolke klyngeanalysen basert på deres forståelse av dataene for å avgjøre om resultatene produsert av analysen faktisk er meningsfulle.
Typiske forskningsspørsmål klyngeanalysens svar er som følger:
- Medisin-Hva er de diagnostiske klyngene? For å svare på dette spørsmålet ville forskeren utarbeide et diagnostisk spørreskjema som inkluderer mulige symptomer(for eksempel i psykologi, angst, depresjon etc.). Klyngeanalysen kan da identifisere grupper av pasienter som har lignende symptomer.
- Markedsføring – hva er kundesegmentene? For å svare på dette spørsmålet kan en markedsforsker gjennomføre en undersøkelse som dekker behov, holdninger, demografi og oppførsel av kunder. Forskeren kan da bruke klyngeanalyse for å identifisere homogene grupper av kunder som har lignende behov og holdninger.
- Utdanning – hva er studentgrupper som trenger spesiell oppmerksomhet? Forskere kan måle psykologiske, evner og prestasjonsegenskaper. En klyngeanalyse kan da identifisere hvilke homogene grupper som eksisterer blant studenter(for eksempel høypresterende i alle fag, eller studenter som utmerker seg i enkelte fag, men mislykkes i andre).
- Biologi – hva er artenes taksonomi? Forskere kan samle et datasett av forskjellige planter og notere forskjellige attributter av deres fenotyper. En klynge analyse kan gruppere disse observasjonene i en rekke klynger og bidra til å bygge en taksonomi av grupper og undergrupper av lignende planter.
Andre teknikker du kanskje vil prøve for å identifisere lignende grupper av observasjoner er Q-analyse, flerdimensjonal skalering (mds) og latent klasseanalyse.
Klyngeanalysen i SPSS
vårt forskningsspørsmål for dette eksempelet klyngeanalyse er som følger:
Hvilke homogene klynger av studenter dukker opp basert på standardiserte testresultater i matematikk, lesing og skriving?
I SPSS Cluster Analyser kan bli funnet I Analysere/Klassifisere…. SPSS tilbyr tre metoder for klyngeanalyse: K – Betyr Klynge, Hierarkisk Klynge og To-Trinns Klynge.
k-betyr klynge er en metode for å raskt klynge store datasett. Forskeren definerer antall klynger på forhånd. Dette er nyttig for å teste forskjellige modeller med et annet antatt antall klynger.
Hierarkisk klynge er den vanligste metoden. Det genererer en serie modeller med klyngeløsninger fra 1 (alle tilfeller i en klynge) til n (hvert tilfelle er en individuell klynge). Hierarkisk klynge fungerer også med variabler i motsetning til tilfeller; det kan klynge variabler sammen på en måte som ligner på faktoranalyse. I tillegg kan hierarkisk klyngeanalyse håndtere nominelle, ordinære og skalerte data, men det anbefales ikke å blande ulike målenivåer.
totrinns klyngeanalyse identifiserer grupperinger ved å kjøre pre-clustering først og deretter ved å kjøre hierarkiske metoder. Fordi den bruker en rask klyngealgoritme på forhånd, kan den håndtere store datasett som vil ta lang tid å beregne med hierarkiske klyngemetoder. I denne forbindelse er det en kombinasjon av de to foregående tilnærmingene. Totrinns clustering kan håndtere skala og ordinære data i samme modell, og den velger automatisk antall klynger.
den hierarkiske klyngeanalysen følger tre grunnleggende trinn: 1) beregn avstandene, 2) koble klyngene, og 3) velg en løsning ved å velge riktig antall klynger.
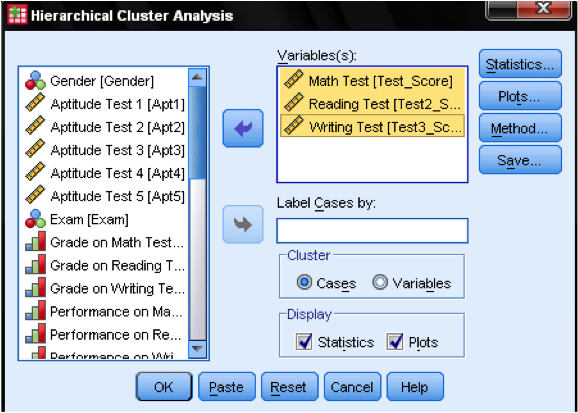
Først må vi velge variablene som vi baserer våre klynger på. I dialogvinduet legger vi til matte -, lese-og skriveprøver i listen over variabler. Siden vi ønsker å klynge tilfeller vi la resten av merkene på standard.
i dialogboksen Statistikk … kan vi spesifisere om vi vil sende ut nærhetsmatrisen (dette er avstandene beregnet i første trinn i analysen) og det forutsagte klyngemedlemskapet i tilfellene i våre observasjoner. Igjen, vi forlater alle innstillinger på standard.

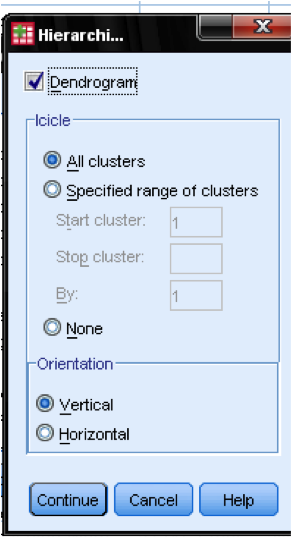
i dialogboksen Plott … bør vi legge Til Dendrogrammet. Dendrogrammet vil grafisk vise hvordan klyngene slås sammen og lar oss identifisere hva riktig antall klynger er.
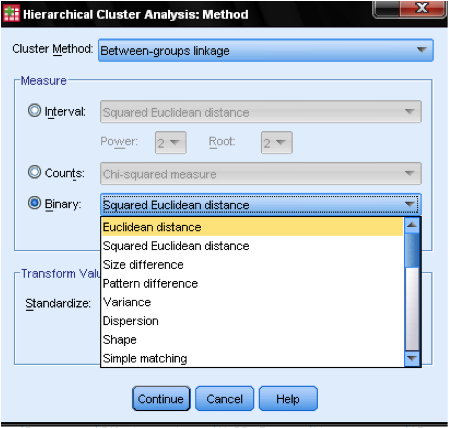
dialogboksmetoden … lar oss spesifisere avstandsmålet og klyngemetoden. Først må vi definere riktig avstandsmåling. SPSS tilbyr tre store blokker av avstandsmål for intervall( skala), teller (ordinal) og binære (nominelle) data.
For intervalldata er Den vanligste Kvadratiske Euklidiske Avstanden. Den er Basert På Euklidsk Avstand mellom to observasjoner, som er kvadratroten av summen av kvadrerte avstander. Siden Den Euklidiske Avstanden er kvadrert, øker den betydningen av store avstander, samtidig som den svekker betydningen av små avstander.

hvis vi har ordenstall (teller) kan vi velge Mellom Chi-Kvadrat eller en standardisert Chi-Kvadrat kalt Phi-Square. For binære data brukes Den Kvadrerte Euklidske Avstanden ofte.

I vårt eksempel velger Vi Intervall Og Kvadratisk Euklidisk Avstand.
Deretter må vi velge Klyngemetoden. Vanligvis er valgene mellom-grupper kobling (avstand mellom klynger er gjennomsnittlig avstand for alle datapunkter innenfor disse klyngene), nærmeste nabo (enkelt kobling: avstand mellom klynger er den minste avstanden mellom to datapunkter), lengst nabo (komplett kobling: avstand er den største avstanden mellom to datapunkter) og Wards metode (avstand er avstanden til alle klynger til det store gjennomsnittet av prøven). Enkelt kobling fungerer best med lange kjeder av klynger, mens komplett kobling fungerer best med tette klumper av klynger. Mellom-grupper kobling fungerer med begge klyngetyper. Det anbefales er å bruke enkelt kobling først. Selv om enkelt kobling har en tendens til å skape kjeder av klynger, hjelper det med å identifisere uteliggere. Etter å ha ekskludert disse uteliggere, kan Vi gå videre Til Wards metode. Wards metode bruker F-verdien (som I ANOVA) for å maksimere betydningen av forskjeller mellom klynger.
en siste vurdering er standardisering. Hvis variablene har forskjellige skalaer og betyr at vi kanskje vil standardisere Enten Til Z-score eller ved å sentrere skalaen. Vi kan også omdanne verdiene til absolutte verdier hvis vi har et datasett der dette kan være hensiktsmessig.