最近、使いやすさと安定性の間のトレードオフを減らそうとするCassandra indexingの新しい変更提案がありました。WHERE句をエンドユーザーにとってもっと面白くて便利にすることです。 この新しいメソッドは、Storage-Attached Indexing(SAI)と呼ばれます。 それは最も派手な名前ではありませんが、あなたは何を期待していますか? エンジニアは、物事を命名するために知られていないが、クールな技術は冗談ではありません。 SAIはCassandraコミュニティの注目を集めていますが、なぜですか? データの索引付けは、データベースの世界では新しい概念ではありません。
データの索引付け方法は、必要なユースケースと展開モデルに基づいて時間の経過とともに変化する可能性があります。 Cassandraは、物事を単純に保つことによって、読み取りと書き込みのオーバーヘッドの複雑さを軽減するために、DynamoとBig Tableの側面を組み合わせて構築されました。 Cassandraの複雑さは、ほとんどが分散された性質のために確保されており、その結果、開発者にとってトレードオフが生じました。 あなたはCassandraの信じられないほどの規模をしたい場合は、データモデルにどのように学習時間を費やす必要があります。 データベースインデックスは、データモデルを強化し、クエリをより効率的にするためのものです。 Cassandraにとって、彼らはプロジェクトの初期から何らかの形で存在していました。 不幸な現実は、彼らがユーザーの要件とうまく一致していないということです。 インデックス作成の使用には、トレードオフと警告の長いリストが付属しており、ほとんど回避されており、一部の人にとっては難しいことです。 その結果、ユーザーは、最高のパフォーマンスを得るために、基本的なクエリを使用してデータモデルにする方法を学びました。
当時は私たちの後ろになっている可能性があり、SAIのような機能が私たちがそこに着くのを助けています。
分散データベースのセカンダリインデックス
すべてのインデックスが同じに作成されるわけではありません。 プライマリインデックスは、一意キー、またはCassandra語彙ではパーティションキーとも呼ばれます。 データベースの主なアクセス方法として、Cassandraはパーティションキーを使用して、データを保持しているノードを識別し、次にデータのパーティションを格納するデー Cassandraでのプライマリインデックスの読み取りは非常に単純ですが、この記事の範囲を超えています。 あなたはここでそれらについての詳細を読むことができます。
セカンダリインデックスは、分散データベースではまったく異なるユニークな課題を作成します。 いくつかのポイントを作るためにテーブルの例を見てみましょう:
CREATE TABLE users(
id long,
firstName text,
lastname text,
country text,
created timestamp,
PRIMARY KEY(id)
);
プライマリインデックスルックアップは、次のように非常に簡単です。
SELECT firstName,lastName FROM users WHERE id=100;
フランスのすべての人を見つけたい場合はどうなりますか? SQLに精通している人は、このクエリが機能することを期待します:
SELECT firstName,lastName FROM users WHERE country=’FR’;
Cassandraでセカンダリインデックスを作成しないと、このクエリは失敗します。 Cassandraの基本的なアクセスパターンは、パーティションキーによるものです。 従来のRDBMSのような非分散データベースでは、テーブルのすべての列がシステムに簡単に表示されます。 インデックスがない場合でも、それらはすべて同じシステムファイルとデータファイルに存在するため、列にアクセスできます。 この場合のインデックスは、検索をより効率的にすることでクエリ時間を短縮するのに役立ちます。
Cassandraのような分散システムでは、列の値は各データノードにあり、クエリプランに含める必要があります。 これは、クエリがすべてのノードに送信され、データが収集され、マージされ、ユーザーに返される”Scatter-Gather”シナリオと呼ばれるものを設定します。 この操作は複数のノードで一度に実行できますが、レイテンシ管理はノードが列値を見つけることができる速度に制限されます。
Cassandra data writesのクイックレビュー
インデックスの追加はデータの読み取りに関するものであると考えているかもしれませんが、これは確かに最終目標です。 しかし、データベースを構築する場合、インデックス作成に関する技術的な課題は、データが書き込まれる時点で偏っています。 読み取りに最適な形式でインデックスをフォーマットしながら、最速の速度でデータを受け入れることは大きな課題です。 個々のノードレベルでCassandaデータベースにデータがどのように書かれているかを簡単にレビューする価値があります。 私はそれがどのように動作するかを説明するように、次の図を参照してくださ
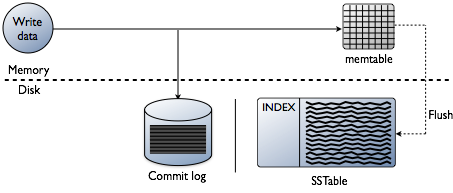
突然変異と呼ばれるノードにデータが提示されると、Cassandraの書き込みパスは非常に簡単で、その操作に最適化されます。 これは、ログ構造化マージ(LSM)ツリーに基づく他の多くのデータベースにも当てはまります。
- データが正しい形式であることを検証します。 スキーマに対する型チェック。
- コミットログの末尾にデータを書き込みます。 ファイルポインタの次の場所だけをシークしません。
- メモリ内のスキーマの単なるhashmapであるmemtableにデータを書き込みます。
完了しました! 突然変異は、それらのことが起こったときに認められます。 私はこれがロックを必要とし、書き込みを実行しようとする他のデータベースと比較してどれほど簡単であるかが大好きです。
その後、memtablesが物理メモリを埋めると、フラッシュプロセスはsstable(ソートされた文字列テーブル)と呼ばれるファイルにディスク上の単一のパスでセグメントを書 永続性がSSTableに移動したので、付随するコミットログは削除されます。 データがノードに書き込まれると、このプロセスは繰り返され続けます。
重要な詳細:Sstableは不変です。 それらが書かれれば決して更新されて、ちょうど取り替えられて得ない。 最終的には、より多くのデータが書き込まれるにつれて、compactionと呼ばれるバックグラウンドプロセスがsstableをマージし、不変の新しいものにソートします。 多くの圧縮方式がありますが、基本的にはすべてこの機能を実行します。
あなたは今、Cassandraに関する十分な基本的な基礎を持っているので、インデックスで十分にオタクになることができます。 情報の任意のさらなる深さは、読者のための練習として残されています。
以前の索引付けに関する問題
Cassandraには、以前の二次索引付けの実装が二つありました。 Storage Attached Secondary Indexing(SASI)とSecondary Indexes,これは2iと呼ばれています。 セカンダリインデックスは最初からCassandraの一部でしたが、実装によってエンドユーザーにとってはトレードオフの長いリストが面倒になりました。 私たちがプロジェクトとして常に対処してきた二つの主な懸念は、ディスク上の書き込み増幅とインデックスサイズです。 その結果、新しいユーザーには、展開の後で失敗させるだけでイライラするように誘惑される可能性があります。 それぞれを見てみましょう。
Secondary Indexes(2i)—このプロジェクトのオリジナルの作業は、初期のThriftデータモデルの便利な機能として始まりました。 その後、Cassandraクエリ言語がCassandraの優先クエリメソッドとしてThriftに取って代わったため、2iの機能は”CREATE INDEX”構文で保持されました。 あなたがSQLから来たのであれば、これは意図しない結果の法則を学ぶための本当に簡単な方法でした。 SQLインデックス作成と同様に、追加するほど書き込みパフォーマンスに影響します。 しかし、Cassandraでは、これは書き込み増幅の大きな問題を引き起こしました。 上記の書き込みパスを参照すると、セカンダリインデックスはパスに新しいステップを追加しました。 インデックス付き列の変更が発生すると、別のインデックスファイル内のデータを再インデックス化するインデックス操作がトリガーされます。 テーブル上のインデックスが増えると、単一行の書き込み操作でディスクアクティビティが劇的に増加します。 ノードが大量の突然変異を取っているとき、結果は個々のノードを不安定にさせることができる飽和させたディスク活動である場合もあり、2iに”控えめに使用しなさい”の当然の指導を与える。”この実装ではインデックスサイズはかなり線形ですが、インデックスを再作成すると、アクティブなクラスターで必要なディスク領域の量を計画するのが困難になる可能性があります。
Storage Attached Secondary Indexing(SASI)—SASIは元々、セカンダリインデックスの一般的な問題ではなく、特定のクエリの問題を解決するためにAppleの小さなチームによって設計されました。 そのチームにとって公平であるために、それは解決するために設計されたことのないユースケースで彼らから離れました。 オープンソースの皆さんへようこそ。 SASIが対処するために設計された2つのクエリタイプ:
- 部分的なデータ一致に基づいて行を検索します。 ワイルドカード、またはクエリのように。
- スパースデータ、特にタイムスタンプに対するクエリの範囲。 時間範囲タイプのクエリに収まるレコードの数。
これらの操作の両方を非常にうまく行い、レガシー2iでの書き込み増幅の問題にも対処しました。cassandraノードに突然変異が提示されるので、memtableの使用方法と同じように、データは最初の書き込み中にメモリ内で索引付けされます。 順列ではディスクアクティビティは必要ありません。 多くの書き込みアクティビティを持つクラスターの大幅な改善。 Memtableがsstableにフラッシュされると、データの対応するインデックスがフラッシュされます。 書き込まれるすべてのインデックスファイルは不変であり、sstableに添付されているため、Storage Attachedという名前になります。 圧縮が発生すると、新しいsstableが作成されると、データのインデックスが再作成され、新しいファイルに書き込まれます。 ディスク活動の観点からは、これは大きな改善でした。 SASIの欠点は、主に作成されたインデックスのサイズにありました。 ディスク上のインデックス形式では、インデックス付けされた各列に使用されるディスク領域が膨大になりました。 これはオペレータのためにそれらを管理すること非常に困難にする。 さらに、SASIは実験的なものとしてマークされており、機能改善に関してはあまり起こっていませんでした。 多くのバグは、SASIを完全に削除する必要があるかどうかの議論をもたらした高価な修正で時間をかけて発見されています。 この機能で最も深いダイビングが必要な場合は、Duy Hai DoanはSASIがどのように機能するかを分解する素晴らしい仕事をしました。
SAIをより良くするのは
その質問に対する最初の、最良の答えは、SAIは本質的に進化的であるということです。 DataStaxのエンジニアは、セカンダリインデックスのコアアーキテクチャはゼロから対処する必要があることに気付きましたが、以前の実装から学んだ確 Cassandraのクエリ機能強化のためのパスを作成しながら、書き込みの増幅とインデックスファイルのサイズの問題に対処することが、主な使命でした。 SAIはこれらのトピックの両方にどのように対処していますか?
書き込み増幅—SASIから学んだように、新しい機能を追加しながら、Cassandraの書き込みパスの仕組みに沿って維持するための正しい方法は、Sstableを使用したインメ SAIでは、突然変異が認識されると、完全にコミットされることを意味し、データが索引付けされます。 最適化と多くのテストにより、書き込みパフォーマンスへの影響は大幅に改善されました。 つまり、インデックス付きテーブルのレイテンシとスループットを、インデックス付きテーブル以外のテーブルと比較して2倍に増やすことを計画する必要があります。 Duy Hai Doanを引用するには、”魔法はありません”だけで良いエンジニアリング。
インデックスサイズ—これは最も劇的な改善であり、おそらくほとんどの作業が行われている場所です。 データベース内部の世界に従えば、データストレージはまだ継続的に進化する改善で満たされた活発な分野であることを知っています。 SAIは、データ型に基づいて2つの異なるタイプの索引付けスキームを使用します。
- テキスト反転インデックスは、用語を辞書に分割して作成されます。 最大の改善は、より小さなインデックスサイズを意味し、はるかに優れた圧縮を提供していますトライベースのインデクシングの使用からです。
- 数値–Luceneから取得したブロックkdツリーと呼ばれるデータ構造を利用し、優れた範囲クエリのパフォーマンスを提供します。 トークン順序クエリ用に最適化するために、別の行IDリストが維持されます。
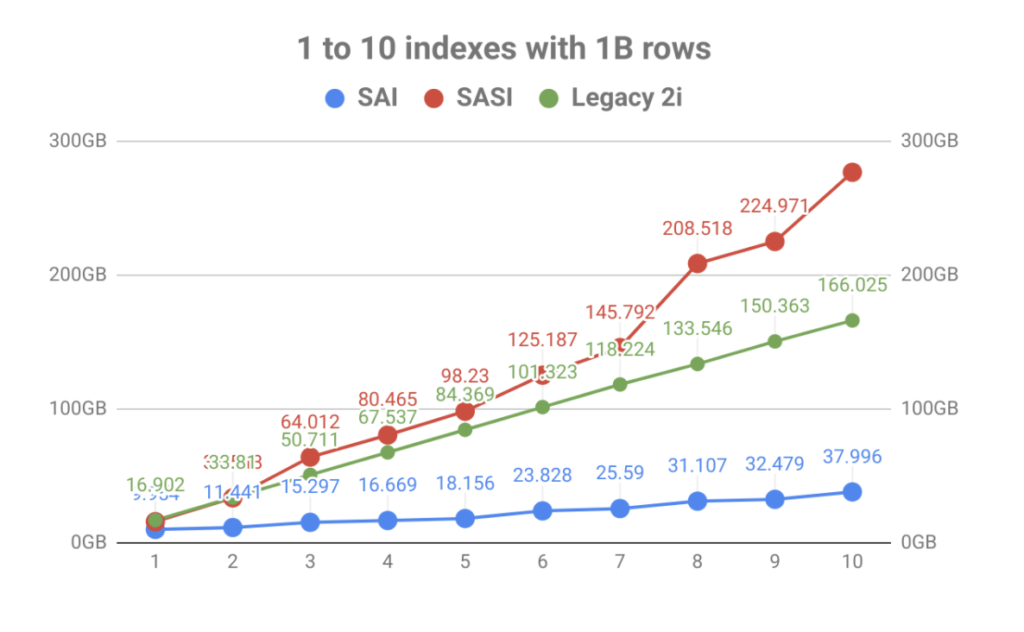
インデックスストレージに重点を置いた結果、ボリュームとテーブルインデックスの数が大幅に改善されました。 下のグラフでわかるように、SASIによってもたらされた高速インデックスは、ディスク使用量の爆発によってすぐに覆されました。 運用計画が困難になるだけでなく、圧縮イベント中にインデックスファイルを読み取る必要があり、ディスクが飽和してノードのパフォーマンスの問題が発生する可能性がありました。
saiの内部アーキテクチャは、書き込み増幅とインデックスサイズ以外では、将来的にさらなる拡張と機能の追加を可能にします。 これは、将来のビルドでよりモジュール化するプロジェクトの目標に沿ったものです。 保留中の他のCepのいくつかを見てみましょう、あなたはこれが始まりに過ぎないことを見ることができます。
サイはここからどこに行くのですか?
DataStaxはCASSANDRA拡張プロセスを通じてCEP-7としてAPACHE CassandraプロジェクトにSAIを提供しました。 議論は4に含めるために今にあります。Cassandraのxブランチ。
Apache Cassandraプロジェクトの一部になる前にこれを試してみたいのであれば、私たちはあなたが行くためのいくつかの場所を持っています。 オペレーターやもう少し技術的なハンズオンが好きな人のために、最新のDataStax Enterprise6.8をダウンロードすることができます。 あなたが開発者であれば、SAIはDataStax Astra、Cassandra as a Serviceで有効になりました。 フリーフォーエバー層を作成して、構文と新しいwhere句機能を使用することができます。 この機能を使用するには、Cassandra Indexing Skillsページと付属のドキュメントを参照してください。