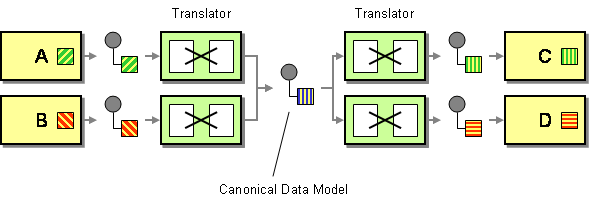
標準的なデータモデルは、異なるデータ形式を使用するアプリケーションを統合するときの依存関係を最小限に抑えるためのソリューションとして、エンタープライズインテグレーションパターンで定義されています。 つまり、コンポーネント(アプリケーションまたはサービス)は、両方のコンポーネントデータ形式から独立したデータ形式を介して別のコンポーネ
ここで強調すべき二つのこと。 このようなモデルは、アプリケーション統合とサービス指向の文脈で使用されているため、最初にコンポーネントをアプリケーションまたはサービスのいず 次に、ここでは、トランスポートデータ形式としてのみ使用すべき概念について説明します。 データストアの内部構造として正規のデータ形式を使用するべきではありません。
理論的には、利点はかなり明白です。 標準的なデータ形式は、アプリケーション間の結合を減らし、コンポーネントのセットを統合するために開発される翻訳の数を減らします。 かなり面白いでしょうか? 単一のデータモデルは、ITランドスケープ全体と一連の人々(開発者、システムアナリスト、ビジネス利害関係者など)によって理解できます。)誰が与えられた概念の同じビジョンを共有することができます。
しかし、実用的な目的のために、そのようなモデルを実装することはめったに効率的ではありません。
保険会社のマーケティング-サポート部門にとって、人は同じ概念ではありません。 航空交通管理システムのための飛行は、それがパイロットによって満たされたか、それがあなたの空域の上に進行中の飛行であるかどうかに応じて異 PLM部品は、設計されたばかりか、サポートチームが保守する必要があるかどうかによって、完全に異なる表現を持っています。
ほとんどのコンテキストでは、標準データモデルを設計すると、オプション属性の完全なセットと必須の属性(識別子など)を持つ大規模なデータモデル 主にコンポーネントの統合を容易にするように設計されていましたが、複雑になるだけです。 その間、あなたのモデルは、その固有の複雑さ(利用と管理の面で)のために、ユーザーの間で多くの欲求不満を引き起こします。 さらに、結合の問題に関しては、あなたはそれをどこか別の場所に移しているだけです。 あるコンポーネントのデータ形式に結合されるのではなく、ITランドスケープ全体で使用される共通のデータ形式に緊密に結合され、非常に頻繁に変更され
一言で言えば、ほとんどのコンテキストでは、標準データモデルはアンチパターンとして考慮されるべきです。 データを交換する2つのコンポーネント間の依存関係を最小限に抑える必要があると考える以外に、他のオプションは何ですか?
ドメイン駆動設計(DDD)は、有界コンテキストの概念を導入することを推奨しています。 有界コンテキストは、モデルが他の有界コンテキストと明確な境界で適用される明示的なコンテキストです。 組織によっては、制限されたコンテキストは、オブジェクトが利用されている機能ドメインを参照したり、オブジェクトの状態自体を参照したり
その場合、次の図のような標準データモデルは単に黄色の部分になります:
A、B、Cの共通部分は、コンテキストに関係なくそこになければならない属性のセットを表します(基本的には以前の大きなCDMの必須属性)。 この部分は、その中心的な役割のために慎重に設計する必要があります。 しかし、実用的なままにすることが重要です。 あなたの文脈でそのような共通のモデルを持つことが意味をなさない場合は、単にそれを破棄する必要があります。
また、重要なのは、2つのコンテキスト(AとB、BとC、CとA)の間の共通部分です。 あるオブジェクト表現をある文脈から別の文脈にマップする方法は? 2つのコンテキスト間で共有する必要がある明示的な属性は何ですか? 2つのコンテキスト間の一般的なビジネス上の制約は何ですか? これらの質問は依然として横断的なチームによって答えられるべきですが、ビジネスの観点からは、それらを上げることは理にかなっています。 それは、潜在的に反対のコンテキストで共有される単一のCDMでは必ずしもそうではありませんでした。
それにもかかわらず、他のコンテキスト(白)と共有されていない部分については、エンタープライズデータモデルの一部であってはなりません。 あなたは実用的でなければなりません。 たとえば、サブセットが特定のドメインに固有のものである場合は、それをモデル化するのはドメインの専門家に任されている必要があります。しかし、1つの重要な課題は、それらの有界な文脈を特定することであり、ここでコンウェイの法則を思い出させる価値があるかもしれません:
システムを設計する組織は、必然的に、その構造が組織の通信構造のコピーである設計を生成します。
境界のあるコンテキストは、必ずしも現在の組織にマッピングされるものではありません。 たとえば、有界コンテキストは複数の部門を包含することができます。 組織のサイロを壊すことはまだほとんどの会社のための目的であるべきである。
また、DDDは、腐敗防止層(ACL)の概念を導入しています。 このパターンは、(データ品質の問題などを防ぐために、古いシステムと新しいシステムの間に仲介層を導入することによって)レガシー移行の解決策を参照). しかし、私たちが腐敗について話すとき、私たちの文脈では、短期的な問題を解決するために導入できるデータモデリング債務に関連しています。
PLM部品の特定の状態を管理するために担当する二つのシステムの例を見てみましょう(部品は、例えばヘリコプターローターのように生産または購入され、 1つのレガシーシステム(SystemAと呼びましょう)が設計段階の管理を担当し、保守段階の管理を担当する新しいシステム(SystemZと呼びましょう)を実装する必 ITアプリケーション全体のランドスケープは、それを認識していないSystemAを除いて、同じ共通部分識別子(partId)を共有します。 PartIdの代わりに、SystemAは独自の識別子systemAIdを管理します。 SystemZはsystemAIdを使用してSystemAを呼び出す必要があるため、ヒューリスティックにsystemAIdをSystemZデータモデルの一部として統合することができます。
これは避けるべきよくある間違いです。 短期的な状況のためにデータモデルが破損しただけです。
ACLパターンはここで解決策だった可能性があります。 SystemZは独自のデータ形式を実装している可能性があります(systemAIdのような外部の破損なし)。 その後、partIdとsystemAIdの間の変換を管理するのは仲介層に任されていたでしょう。
このトピックに適用すると、ACLパターンは二つの異なる境界コンテキストの間にレイヤを実装するように強制されます。 コンポーネントは、独自の境界コンテキストの一部ではない別のコンポーネントを呼び出す方法を認識していません。 代わりに、コンポーネントは、それが属する境界コンテキストのデータ形式に独自のデータ構造をマップする方法のみを認識します。
ちなみに、これは経験則です。 コンポーネントは、1つの有界コンテキストにのみ属します。 これが、DDDがマイクロサービスアーキテクチャに最適な理由でもあります。 細かい粒度のために、このルールに従う方が簡単です。
要約すると、そのような標準的なモデルは、ほとんどの場合、反パターンとして考慮されるべきである。 コンテキスト間の明示的な境界を持つコンテキストごとに1つのモデルを意味するbounded context概念を実装しようとする必要があります。 異なる境界コンテキストの一部である2つのコンポーネントは、データモデリングの破損を防ぐために、破損防止層を介して通信する必要があります。