最適化は、より少ないリソース(すなわち、CPU、メモリ)を消費し、高速を提供することによってコードを改善しようとするプログラム変換技術です。
最適化では、高レベルの一般的なプログラミング構造は非常に効率的な低レベルプログラミングコードに置き換えられます。 コードの最適化プロセスは、以下の3つのルールに従う必要があります:
-
出力コードは、どのような方法でも、プログラムの意味を変更してはなりません。
-
最適化は、プログラムの速度を増加させる必要があり、可能であれば、プログラムは、リソースの少ない数を要求する必要があります。
-
最適化自体は高速であり、コンパイルプロセス全体を遅らせるべきではありません。
最適化されたコードのための努力は、プロセスのコンパイルの様々なレベルで行うことができます。
-
最初に、ユーザーはコードを変更/再配置したり、より良いアルゴリズムを使用してコードを記述することができます。
-
中間コードを生成した後、コンパイラはアドレス計算とループの改善によって中間コードを変更することができます。
-
ターゲットマシンコードの生成中に、コンパイラはメモリ階層とCPUレジスタを使用できます。
最適化は大きく二つのタイプに分類することができます:機械独立と機械依存。
マシンに依存しない最適化
この最適化では、コンパイラは中間コードを取り込み、CPUレジスタや絶対メモリ位置を含まないコードの一部を変換します。 例えば:
do{ item = 10; value = value + item; } while(valueThis code involves repeated assignment of the identifier item, which if we put this way:
Item = 10;do{ value = value + item; } while(valueshould not only save the CPU cycles, but can be used on any processor.
Machine-dependent Optimization
Machine-dependent optimization is done after the target code has been generated and when the code is transformed according to the target machine architecture. It involves CPU registers and may have absolute memory references rather than relative references. Machine-dependent optimizers put efforts to take maximum advantage of memory hierarchy.
Basic Blocks
Source codes generally have a number of instructions, which are always executed in sequence and are considered as the basic blocks of the code. These basic blocks do not have any jump statements among them, i.e., when the first instruction is executed, all the instructions in the same basic block will be executed in their sequence of appearance without losing the flow control of the program.
A program can have various constructs as basic blocks, like IF-THEN-ELSE, SWITCH-CASE conditional statements and loops such as DO-WHILE, FOR, and REPEAT-UNTIL, etc.
Basic block identification
We may use the following algorithm to find the basic blocks in a program:
-
基本ブロックの開始位置からすべての基本ブロックのヘッダーステートメントを検索します:
- プログラムの最初の文。
- 任意の分岐の対象となるステートメント(条件付き/無条件)。
- 任意のbranch文に続く文。
-
ヘッダ文とそれに続く文は、基本ブロックを形成します。
-
基本ブロックには、他の基本ブロックのヘッダーステートメントは含まれません。
基本ブロックは、コード生成と最適化の両方の観点から重要な概念です。
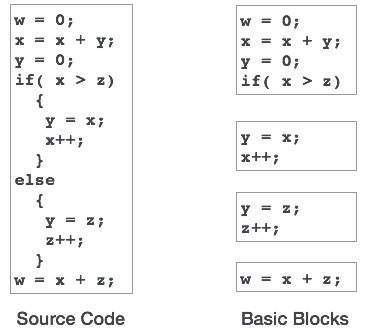
基本ブロックは、単一の基本ブロックで複数回使用されている変数を識別する上で重要な役割を果たします。 変数が複数回使用されている場合、ブロックの実行が終了しない限り、その変数に割り当てられたレジスタメモリを空にする必要はありません。
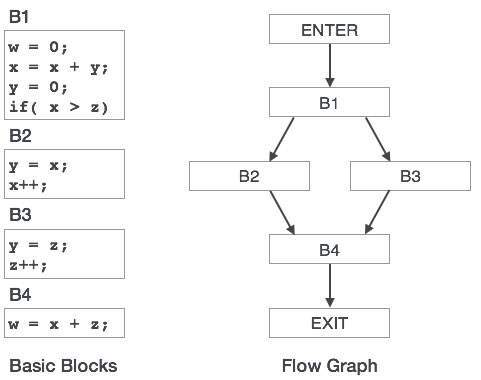
制御フローグラフ
プログラム内の基本ブロックは、制御フローグラフで表すことができます。 制御フローグラフは、プログラム制御がブロック間でどのように渡されているかを示しています。 これは、プログラム内の不要なループを見つけるのを助けることによって最適化に役立つ便利なツールです。
ループ最適化
ほとんどのプログラムはシステム内でループとして実行されます。 CPUサイクルとメモリを節約するために、ループを最適化する必要があります。 ループは、次の手法で最適化できます:
-
不変コード:ループ内に存在し、各反復で同じ値を計算するコードの断片は、ループ不変コードと呼ばれます。 このコードは、反復ごとではなく、一度だけ計算されるように保存することで、ループの外に移動できます。
-
帰納法解析:変数は、その値がループ不変値によってループ内で変更された場合、帰納法変数と呼ばれます。
-
強度の低下:より多くのCPUサイクル、時間、およびメモリを消費する式があります。 これらの式は、expressionの出力を損なうことなく、安価な式に置き換える必要があります。 たとえば、乗算(x*2)は、(x)よりもCPUサイクルの点で高価です
デッドコード除去
デッドコードは、一つ以上のコードステートメントです。:
- 実行されないか到達できないか、
- 、または実行された場合、その出力は使用されません。
したがって、デッドコードはどのプログラム操作でも何の役割も果たさないため、単純に排除することができます。
部分的にデッドコード
計算値が特定の状況下でのみ使用されるコードステートメントがいくつかあります。 このようなコードは、部分的にデッドコードとして知られています。
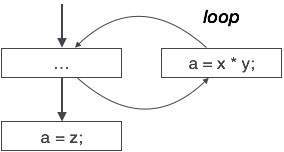
上記の制御フローグラフは、変数’a’が式’x*y’の出力を割り当てるために使用されるプログラムのチャンクを示しています。 ‘A’に割り当てられた値がループ内で使用されることはないと仮定しましょう。コントロールがループを終了した直後に、’a’には変数’z’の値が割り当てられます。 ここでは、’a’の割り当てコードはどこにも使用されないため、排除する資格があると結論づけています。
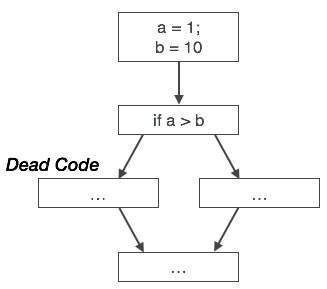
同様に、上の図は条件文が常に偽であることを示しており、真の場合に書かれたコードは実行されないため、削除することができます。
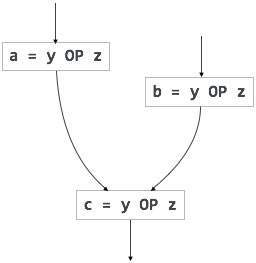
部分冗長性
冗長式は、オペランドを変更することなく、並列パスで複数回計算されます。一方、部分冗長式は、オペランドを変更することなく、パス内で複数回計算されます。 例えば,
|
|
ループ不変符号は部分的に冗長であり,符号運動技術を使用することによって除去することができる。
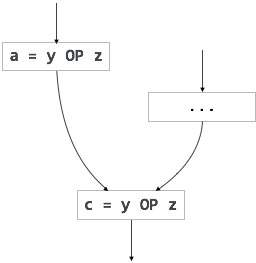
部分的に冗長なコードの別の例は次のようになります:
If (condition){ a = y OP z;}else{ ...}c = y OP z;
オペランド(yとz)の値は、変数aの代入から変数cへの変更されていないと仮定します。 以下に示すように、Code motionを使用してこの冗長性を排除できます:
If (condition){ ... tmp = y OP z; a = tmp; ...}else{ ... tmp = y OP z;}c = tmp;
ここでは、条件が真か偽かにかかわらず、y OP zは一度だけ計算する必要があります。