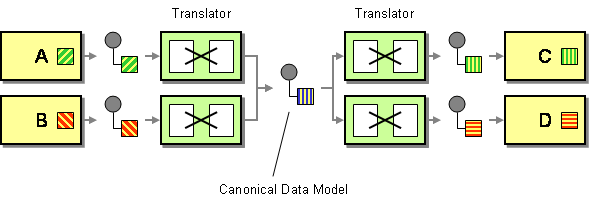
Un modello di dati canonici è definito nell’Enterprise Integration Patterns come la soluzione per ridurre al minimo le dipendenze in caso di integrazione di applicazioni che utilizzano diversi formati di dati. In altre parole, un componente (un’applicazione o un servizio) dovrebbe comunicare con un altro componente attraverso un formato di dati che sarebbe indipendente da entrambi i formati di dati dei componenti.
Due cose da evidenziare qui. Per prima cosa ho definito un componente come un’applicazione o un servizio perché tali modelli sono/sono stati utilizzati nel contesto dell’integrazione dell’applicazione e dell’orientamento al servizio. In secondo luogo, stiamo parlando di un concetto che dovrebbe essere utilizzato esclusivamente come formato di dati di trasporto. Non è consigliabile utilizzare un formato dati canonico come struttura interna dell’archivio dati.
Teoricamente, i vantaggi sono piuttosto evidenti. Un formato dati canonico riduce l’accoppiamento tra le applicazioni, riduce il numero di traduzioni da sviluppare per integrare un insieme di componenti, ecc. Abbastanza interessante giusto? Un singolo modello di dati è comprensibile dall’intero panorama IT e da un insieme di persone (sviluppatori, analisti di sistema, stakeholder aziendali, ecc.) che possono condividere la stessa visione di un determinato concetto.
Per scopi pratici, l’implementazione di tali modelli è raramente efficiente.
Una persona non è lo stesso concetto per il reparto marketing e supporto in una compagnia di assicurazioni. Un volo per un sistema di gestione del traffico aereo ha un significato diverso a seconda se è stato riempito da un pilota o se si tratta di un volo in corso sulla parte superiore del vostro spazio aereo. Una parte PLM ha una rappresentazione completamente diversa a seconda se è stata appena progettata o se deve essere mantenuta da un team di supporto.
Nella maggior parte dei contesti, la progettazione di un modello di dati canonico si traduce in un modello di dati di grandi dimensioni con un set completo di attributi opzionali e pochissimi obbligatori (come gli identificatori). Anche se è stato progettato principalmente per facilitare l’integrazione dei componenti, lo complicherai. Nel frattempo, il tuo modello creerà molta frustrazione tra gli utenti a causa della sua complessità intrinseca (in termini di utilizzo e gestione). Inoltre, per quanto riguarda il problema dell’accoppiamento, lo stai semplicemente spostando da qualche altra parte. Invece di essere accoppiato a un formato di dati componente, si diventa strettamente accoppiato a un formato di dati comune che verrà utilizzato dall’intero panorama IT e soggetto a modifiche molto frequenti.
In poche parole, nella maggior parte dei contesti, un modello di dati canonico dovrebbe essere considerato come un anti-pattern. Qual è l’altra opzione che considerare che si dovrebbe comunque voler ridurre al minimo le dipendenze tra due componenti che scambiano dati?
Domain Driven Design (DDD) consiglia di introdurre il concetto di contesto limitato. Un contesto limitato è semplicemente un contesto esplicito in cui un modello si applica con confini chiari con altri contesti limitati. A seconda dell’organizzazione, un contesto limitato potrebbe fare riferimento a un dominio funzionale in cui viene utilizzato un oggetto, potrebbe fare riferimento allo stato dell’oggetto stesso, ecc.
In tal caso, il modello di dati canonico in quanto tale sarebbe semplicemente la parte gialla nel diagramma seguente:
L’intersezione di A, B e C rappresenta l’insieme di attributi che devono esserci, a prescindere dal contesto (in pratica gli attributi obbligatori del precedente grande CDM). Questa parte dovrebbe ancora essere attentamente progettata a causa del suo ruolo centrale. Eppure è importante rimanere pragmatici. Se nel tuo contesto non ha senso avere un modello così comune, dovresti semplicemente scartarlo.
Ciò che è anche importante è un’intersezione tra due contesti (A e B, B e C, C e A). Come mappare una rappresentazione di un oggetto da un contesto all’altro? Quali sono gli attributi espliciti che dovrebbero essere condivisi tra due contesti? Quali sono i vincoli aziendali comuni tra due contesti? Queste domande dovrebbero ancora essere risolte da un team trasversale, ma dal punto di vista aziendale, ha senso sollevarle. Questo non è sempre stato il caso di un singolo CDM condiviso in contesti potenzialmente opposti.
Tuttavia, per quanto riguarda le parti che non sono condivise con altri contesti (in bianco), non dovrebbe essere parte di un modello di dati aziendali. Dovresti essere pragmatico. Ad esempio, se un sottoinsieme è specifico per un determinato dominio, dovrebbe essere compito degli esperti del dominio modellarlo autonomamente.
Una sfida chiave, tuttavia, è identificare quei contesti delimitati e potrebbe valere la pena ricordare qui la legge di Conway:
Qualsiasi organizzazione che progetta un sistema produrrà inevitabilmente un progetto la cui struttura è una copia della struttura di comunicazione dell’organizzazione.
I contesti delimitati non devono essere necessariamente mappati sull’organizzazione corrente. Ad esempio, un contesto limitato può comprendere diversi reparti. Rompere i silos organizzativi dovrebbe essere ancora un obiettivo per la maggior parte delle aziende.
Inoltre, DDD introduce il concetto di livello anti-corruzione (ACL). Questo modello può riferirsi a una soluzione per una migrazione legacy (introducendo un livello di intermediazione tra il vecchio e il nuovo sistema per prevenire problemi di qualità dei dati, ecc.). Ma nel nostro contesto quando si parla di corruzione è legato alla modellazione dei dati del debito si può introdurre per risolvere i problemi a breve termine.
Prendiamo l’esempio di due sistemi incaricati di gestire un dato stato di una parte PLM (una parte è un elemento fisico prodotto o acquistato e poi assemblato come un rotore di un elicottero per esempio). Un sistema legacy (chiamiamolo SystemA) è incaricato di gestire la fase di progettazione ed è necessario implementare un nuovo sistema (chiamiamolo SystemZ) incaricato di gestire la fase di manutenzione. L’intero panorama dell’applicazione IT condivide lo stesso identificatore di parte comune (partId) ad eccezione di SystemA che non ne è a conoscenza. Invece del partId, SystemA gestisce il proprio identificatore, systemAId. Poiché SystemZ deve essere chiamato SystemA usando systemAId, un’euristica potrebbe essere quella di integrare systemAId come parte del modello di dati SystemZ.
Questo è un errore comune che dovresti evitare. Hai semplicemente corrotto il tuo modello di dati a causa di una situazione a breve termine.
Il modello ACL avrebbe potuto essere una soluzione qui. SystemZ avrebbe potuto implementare il proprio formato di dati (senza alcuna corruzione esterna come systemAId). Quindi sarebbe spettato a un livello di intermediazione gestire la traduzione tra il partId e il systemAId.
Applicato al nostro argomento, il modello ACL impone di implementare un livello tra due diversi contesti delimitati. Un componente non è a conoscenza di come chiamare un altro componente che non fa parte del proprio contesto limitato. Invece, un componente è a conoscenza solo di come mappare la propria struttura dati sul formato dei dati del contesto limitato a cui appartiene.
A proposito, questa è una regola empirica. Un componente deve appartenere a un solo contesto limitato. Questo è anche il motivo per cui DDD è ideale per l’architettura dei microservizi. A causa della granularità a grana fine, è più facile rispettare questa regola.
Per riassumere, un modello canonico in quanto tale dovrebbe essere considerato come un anti-pattern nella maggior parte dei casi. Dovresti provare a implementare il concetto di contesto limitato che significa un modello per contesto con confini espliciti tra i contesti. Due componenti che fanno parte di diversi contesti delimitati dovrebbero comunicare attraverso un livello anti-corruzione per prevenire la corruzione della modellazione dei dati.