Recentemente, c’è stata una nuova proposta di modifica per Cassandra di indicizzazione che tenta di ridurre il compromesso tra usabilità e stabilità: Rendere la clausola WHERE molto più interessante e utile per gli utenti finali. Questo nuovo metodo è chiamato Storage-Attached Indexing (SAI). Non è il nome più appariscente, ma cosa ti aspetti? Gli ingegneri non sono noti per nominare le cose, ma la tecnologia cool non è mai uno scherzo. SAI ha catturato l’attenzione della comunità Cassandra, ma perché? L’indicizzazione dei dati non è un concetto nuovo nel mondo dei database.
Il modo in cui indicizziamo i nostri dati può cambiare nel tempo in base ai casi d’uso e ai modelli di distribuzione desiderati. Cassandra è stato costruito combinando aspetti di Dynamo e Big Table per ridurre la complessità del sovraccarico di lettura e scrittura mantenendo le cose semplici. La complessità di Cassandra è stata per lo più riservata alla sua natura distribuita e, di conseguenza, ha creato un compromesso per gli sviluppatori. Se si desidera che la scala incredibile di Cassandra, si deve passare il tempo a imparare a modello di dati. Gli indici del database hanno lo scopo di migliorare il modello di dati e rendere le query più efficienti. Per Cassandra, sono esistiti in qualche forma fin dai primi giorni del progetto. La sfortunata realtà è che non si sono adattati bene alle esigenze degli utenti. Qualsiasi uso dell’indicizzazione viene fornito con una lunga lista di compromessi e avvertimenti al punto che sono per lo più evitati e per alcuni, solo un duro no. Di conseguenza, gli utenti hanno imparato come modello di dati con query di base per ottenere le migliori prestazioni.
Quei giorni potrebbero essere sempre dietro di noi e caratteristiche come SAI ci stanno aiutando ad arrivarci.
Indici secondari nei database distribuiti
Non tutti gli indici sono creati uguali. Gli indici primari sono noti anche come chiave univoca, o nel vocabolario Cassandra, chiave di partizione. Come metodo di accesso primario sul database, Cassandra utilizza la chiave di partizione per identificare il nodo che contiene i dati, quindi il file di dati che memorizza la partizione dei dati. Le letture dell’indice primario in Cassandra sono abbastanza semplici ma oltre lo scopo di questo articolo. Si può leggere di più su di loro qui.
Gli indici secondari creano una sfida completamente diversa e unica in un database distribuito. Diamo un’occhiata a una tabella di esempio per fare alcuni punti:
CREA utenti DI TABELLE (
id long,
FirstName text,
LastName text,
country text,
creed timestamp,
PRIMARY KEY (id)
);
Una ricerca dell’indice primario sarebbe piuttosto semplice come questa:
SELEZIONA Nome, COGNOME DAGLI utenti DOVE id = 100;
Cosa succede se volessi trovare tutti in Francia? Come qualcuno che ha familiarità con SQL, ci si aspetterebbe che questa query funzioni:
SELEZIONA Nome, COGNOME DAGLI utenti IN CUI country = ‘FR’;
Senza creare un indice secondario in Cassandra, questa query fallirà. Il modello di accesso fondamentale in Cassandra è da partition key. In un database non distribuito come un RDBMS tradizionale, ogni colonna della tabella è facilmente visibile al sistema. È comunque possibile accedere alla colonna anche se non esiste un indice poiché esistono tutti nello stesso sistema e negli stessi file di dati. Gli indici in questo caso aiutano a ridurre il tempo di query rendendo la ricerca più efficiente.
In un sistema distribuito come Cassandra, i valori delle colonne si trovano su ciascun nodo dati e devono essere inclusi nel piano di query. Questo imposta quello che chiamiamo lo scenario “Scatter-Gather” in cui una query viene inviata a ogni nodo, i dati vengono raccolti, uniti e restituiti all’utente. Anche se questa operazione può essere eseguita su più nodi contemporaneamente, la gestione della latenza dipende dalla velocità con cui il nodo può trovare il valore della colonna.
Revisione rapida dei dati di Cassandra scrive
Potresti pensare che aggiungere indici riguardi la lettura dei dati, che è certamente l’obiettivo finale. Tuttavia, quando si crea un database, le sfide tecniche sull’indicizzazione sono prevenute nel punto in cui i dati vengono scritti. Accettare i dati alla massima velocità durante la formattazione degli indici nella forma più ottimale per le letture è una sfida enorme. Vale la pena fare una rapida revisione di come i dati sono scritti in un database Cassanda a livello di singolo nodo. Fare riferimento al seguente diagramma mentre spiego come funziona.
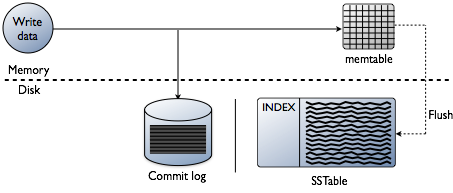
Quando i dati vengono presentati a un nodo, che chiamiamo una mutazione, il percorso di scrittura per Cassandra è molto semplice e ottimizzato per quell’operazione. Questo vale anche per molti altri database basati su alberi LSM(Log-Structured Merge).
- Convalidare i dati è il formato corretto. Digitare check contro lo schema.
- Scrivi i dati nella coda di un registro di commit. Nessuna ricerca, solo il punto successivo sul puntatore del file.
- Scrivi i dati in una memtable, che è solo una hashmap dello schema in memoria.
Fatto! La mutazione è riconosciuta quando queste cose accadono. Mi piace quanto sia semplice rispetto ad altri database che richiedono un blocco e cercano di eseguire una scrittura.
Più tardi, mentre i memtables riempiono la memoria fisica, un processo di flush scrive i segmenti in un singolo passaggio su disco in un file chiamato SSTable (tabella stringhe ordinate). Il registro di commit di accompagnamento viene eliminato ora che la persistenza è stata spostata su SSTable. Questo processo continua a ripetersi mentre i dati vengono scritti sul nodo.
Dettaglio importante: SSTables sono immutabili. Una volta che sono scritti non vengono mai aggiornati, appena sostituiti. Alla fine, man mano che vengono scritti più dati, un processo in background chiamato compattazione si fonde e ordina sstables in nuovi che sono anche immutabili. Ci sono molti schemi di compattazione, ma fondamentalmente, tutti svolgono questa funzione.
Ora hai abbastanza basi di base su Cassandra in modo che possiamo diventare sufficientemente nerd con gli indici. Ogni ulteriore approfondimento delle informazioni è lasciato come un esercizio per il lettore.
Problemi con l’indicizzazione precedente
Cassandra ha avuto due precedenti implementazioni di indicizzazione secondaria. Storage Attached Secondary Indexing (SASI) e indici secondari, a cui ci riferiamo come 2i. Ancora una volta, il mio punto sugli ingegneri che non sono appariscenti con i nomi regge qui. Gli indici secondari hanno fatto parte di Cassandra fin dall’inizio, ma le implementazioni li hanno resi fastidiosi per gli utenti finali con la loro lunga lista di compromessi. Le due principali preoccupazioni che abbiamo costantemente affrontato come progetto sono l’amplificazione in scrittura e la dimensione dell’indice su disco. Di conseguenza, possono essere frustrantemente tentati dai nuovi utenti solo per farli fallire più tardi nella distribuzione. Diamo un’occhiata a ciascuno.
Indici secondari (2i) – Questo lavoro originale nel progetto è iniziato come una caratteristica di convenienza per i primi modelli di dati di risparmio. Successivamente, poiché il linguaggio di query Cassandra ha sostituito la parsimonia come metodo di query preferito per Cassandra, la funzionalità 2i è stata mantenuta con la sintassi “CREATE INDEX”. Se tu fossi venuto da SQL, questo era un modo davvero semplice per imparare la legge delle conseguenze indesiderate. Proprio come nell’indicizzazione SQL, più si aggiunge più si influenzano le prestazioni di scrittura. Tuttavia, con Cassandra, questo ha innescato il problema più grande con l’amplificazione in scrittura. Facendo riferimento al percorso di scrittura sopra, gli indici secondari hanno aggiunto un nuovo passaggio nel percorso. Quando si verifica una mutazione su una colonna indicizzata, viene attivata un’operazione di indicizzazione che riindicizza i dati in un file di indice separato. Più indici su una tabella possono aumentare drasticamente l’attività del disco in un’operazione di scrittura a riga singola. Quando un nodo sta assumendo una quantità elevata di mutazioni, il risultato può essere l’attività del disco saturo che può rendere instabili i singoli nodi, dando a 2i la meritata guida di “usare con parsimonia.”La dimensione dell’indice è abbastanza lineare in questa implementazione, ma con la riindicizzazione, la quantità di spazio su disco necessario può essere difficile da pianificare in un cluster attivo.
Storage Attached Secondary Indexing (SASI) – SASI è stato originariamente progettato da un piccolo team di Apple per risolvere un problema specifico di query e non il problema generale degli indici secondari. Per essere onesti con quella squadra, si è allontanato da loro in un caso d’uso che non è mai stato progettato per risolvere. Benvenuti a tutti open source. I due tipi di query che SASI è stato progettato per affrontare:
- Ricerca di righe in base alla corrispondenza parziale dei dati. Jolly, o COME query.
- Query di intervallo su dati sparsi, in particolare timestamp. Quanti record si inseriscono in una query di tipo intervallo di tempo.
Ha fatto entrambe queste operazioni abbastanza bene e ha anche affrontato il problema dell’amplificazione in scrittura con legacy 2i. Poiché le mutazioni vengono presentate a un nodo Cassandra, i dati vengono indicizzati in memoria durante la scrittura iniziale, proprio come vengono utilizzati i memtables. Nessuna attività del disco è richiesta su una permutazione. Un enorme miglioramento sui cluster con molta attività di scrittura. Quando i memtables vengono scaricati su sstables, l’indice corrispondente per i dati viene scaricato. Ogni file di indice scritto è immutabile e collegato al sstable, da qui il nome di archiviazione allegato. Quando si verifica la compattazione, i dati vengono reindicizzati e scritti in un nuovo file man mano che vengono creati nuovi sstables. Dal punto di vista dell’attività del disco, questo è stato un importante miglioramento. Lo svantaggio di SASI era principalmente nella dimensione degli indici creati. Il formato dell’indice su disco ha causato un’enorme quantità di spazio su disco utilizzato per ogni colonna indicizzata. Questo li rende molto difficili da gestire per gli operatori. Inoltre, SASI è stato contrassegnato come sperimentale e non è successo molto per quanto riguarda il miglioramento delle funzionalità. Molti bug sono stati trovati nel tempo con correzioni costose che hanno portato alla discussione se SASI debba essere rimosso del tutto. Se hai bisogno dell’immersione più profonda su questa funzione, Duy Hai Doan ha fatto un lavoro incredibile di abbattere come funziona SASI.
Ciò che rende SAI migliore
La prima, migliore risposta a questa domanda è che SAI è di natura evolutiva. Gli ingegneri di DataStax si sono resi conto che l’architettura di base dell’indicizzazione secondaria doveva essere affrontata da zero, ma con solide lezioni apprese dalle precedenti implementazioni. Affrontare i problemi dell’amplificazione della scrittura e della dimensione del file di indice durante la creazione di un percorso per migliori miglioramenti delle query in Cassandra è stata la missione principale. In che modo SAI affronta entrambi questi argomenti?
Amplificazione di scrittura — Come abbiamo appreso da SASI, l’indicizzazione in memoria e gli indici di flushing con SSTables erano il modo giusto per rimanere in linea con il funzionamento del percorso di scrittura Cassandra, aggiungendo nuove funzionalità. Con SAI, quando la mutazione è riconosciuta, cioè pienamente impegnata, i dati vengono indicizzati. Con ottimizzazioni e molti test, l’impatto sulle prestazioni di scrittura è notevolmente migliorato. Dovresti vedere meglio di un aumento del 40% del throughput e di oltre il 200% di latenze di scrittura migliori rispetto a 2i. Detto questo, dovresti comunque pianificare un aumento della latenza 2x e del throughput sulle tabelle indicizzate rispetto alle tabelle non indicizzate. Per citare Duy Hai Doan, “Non c’è magia”, solo una buona ingegneria.
Index size-Questo è il miglioramento più drammatico e probabilmente dove la maggior parte del lavoro è stato fatto. Se segui il mondo degli interni del database, sai che l’archiviazione dei dati è ancora un campo vivace pieno di miglioramenti in continua evoluzione. SAI utilizza due diversi tipi di schemi di indicizzazione in base al tipo di dati.
- Gli indici invertiti di testo vengono creati con termini suddivisi in un dizionario. Il più grande miglioramento deriva dall’uso dell’indicizzazione basata su Trie che offre una compressione molto migliore, il che significa dimensioni dell’indice più piccole.
- Numerico-Utilizzando una struttura di dati chiamata block kd-trees, presa da Lucene, che offre eccellenti prestazioni di query di intervallo. Viene mantenuto un elenco ID riga separato per ottimizzare le query degli ordini token.
Con una forte enfasi sull’archiviazione degli indici, il risultato è stato un enorme miglioramento del volume rispetto al numero di indici delle tabelle. Come puoi vedere nel grafico qui sotto, la rapida indicizzazione portata da SASI è stata rapidamente eclissata dall’esplosione dell’utilizzo del disco. Non solo rende la pianificazione operativa un problema, ma i file di indice dovevano essere letti durante eventi di compattazione che potevano saturare i dischi portando a problemi di prestazioni del nodo.
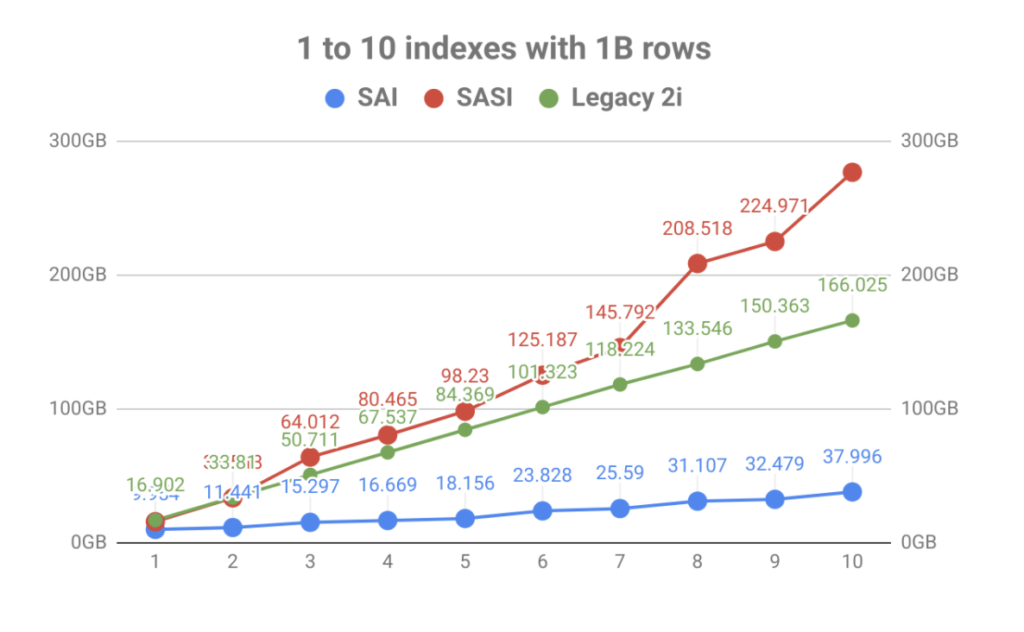
Al di fuori dell’amplificazione in scrittura e della dimensione dell’indice, l’architettura interna di SAI consente un’ulteriore espansione e funzionalità aggiuntive in futuro. Questo è in linea con gli obiettivi del progetto per essere più modulare nelle build future. Date un’occhiata ad alcuni degli altri porcini che sono in sospeso e si può vedere che questo è solo l’inizio.
Dove va SAI da qui?
DataStax ha offerto SAI al progetto Apache Cassandra attraverso il processo di miglioramento Cassandra come CEP-7. La discussione è ora per l’inclusione nel 4.x ramo di Cassandra.
Se vuoi provarlo ora prima che faccia parte del progetto Apache Cassandra, abbiamo un paio di posti dove andare. Per gli operatori o le persone che amano un po ‘ più tecnico hands-on, è possibile scaricare l’ultima DataStax Enterprise 6.8. Se sei uno sviluppatore, SAI è ora abilitato in DataStax Astra, il nostro Cassandra as a Service. Puoi creare un livello gratuito per sempre per giocare con la sintassi e la nuova funzionalità della clausola where. Con questo, impara come usare questa funzione andando alla pagina delle competenze di indicizzazione di Cassandra e alla documentazione inclusa.