Qu’est-ce que l’analyse de grappes?
L’analyse de cluster est une analyse exploratoire qui tente d’identifier les structures dans les données. L’analyse de cluster est également appelée analyse de segmentation ou analyse de taxonomie. Plus précisément, il tente d’identifier des groupes homogènes de cas si le groupement n’est pas connu auparavant. Parce qu’il est exploratoire, il ne fait aucune distinction entre les variables dépendantes et indépendantes. Les différentes méthodes d’analyse de grappes proposées par SPSS peuvent gérer des données binaires, nominales, ordinales et d’échelle (intervalle ou rapport).
L’analyse en grappes est souvent utilisée en conjonction avec d’autres analyses (telles que l’analyse discriminante). Le chercheur doit être en mesure d’interpréter l’analyse en grappes en fonction de sa compréhension des données pour déterminer si les résultats produits par l’analyse sont réellement significatifs.
Questions de recherche typiques les réponses de l’analyse de cluster sont les suivantes:
- Médecine – Quels sont les clusters de diagnostic? Pour répondre à cette question, le chercheur concevrait un questionnaire diagnostique incluant les symptômes possibles (par exemple, en psychologie, anxiété, dépression, etc.). L’analyse en grappes peut ensuite identifier des groupes de patients présentant des symptômes similaires.
- Marketing – Quels sont les segments de clientèle ? Pour répondre à cette question, un chercheur de marché peut mener une enquête couvrant les besoins, les attitudes, les données démographiques et le comportement des clients. Le chercheur peut ensuite utiliser l’analyse de grappes pour identifier des groupes homogènes de clients qui ont des besoins et des attitudes similaires.
- Éducation – Quels sont les groupes d’étudiants qui nécessitent une attention particulière? Les chercheurs peuvent mesurer les caractéristiques psychologiques, d’aptitude et de réussite. Une analyse par grappes peut ensuite identifier quels groupes homogènes existent parmi les élèves (par exemple, les élèves qui réussissent très bien dans toutes les matières ou les élèves qui excellent dans certaines matières mais échouent dans d’autres).
- Biologie – Quelle est la taxonomie des espèces? Les chercheurs peuvent collecter un ensemble de données de différentes plantes et noter différents attributs de leurs phénotypes. Une analyse de grappes peut regrouper ces observations en une série de grappes et aider à établir une taxonomie de groupes et de sous-groupes de plantes similaires.
D’autres techniques que vous voudrez peut-être essayer pour identifier des groupes d’observations similaires sont l’analyse Q, la mise à l’échelle multidimensionnelle (MDS) et l’analyse de classes latentes.
L’analyse en grappes dans SPSS
Notre question de recherche pour cet exemple d’analyse en grappes est la suivante:
Quels grappes homogènes d’étudiants émergent sur la base des résultats de tests standardisés en mathématiques, en lecture et en écriture?
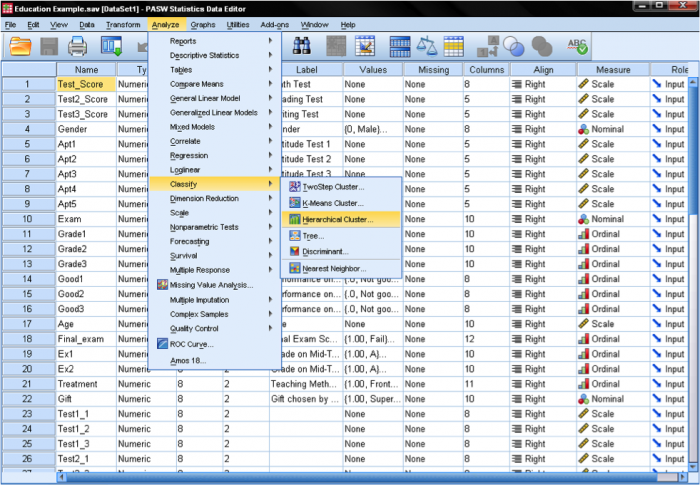
Dans les analyses de cluster SPSS peuvent être trouvées dans Analyser / Classifier…. SPSS propose trois méthodes pour l’analyse de cluster : Cluster K-Means, Cluster Hiérarchique et Cluster en deux étapes.
K-means cluster est une méthode permettant de regrouper rapidement de grands ensembles de données. Le chercheur définit à l’avance le nombre de grappes. Ceci est utile pour tester différents modèles avec un nombre supposé de clusters différent.
Le cluster hiérarchique est la méthode la plus courante. Il génère une série de modèles avec des solutions de cluster de 1 (tous les cas d’un cluster) à n (chaque cas est un cluster individuel). Le cluster hiérarchique fonctionne également avec des variables par opposition aux cas; il peut regrouper des variables d’une manière quelque peu similaire à l’analyse factorielle. De plus, l’analyse de grappes hiérarchiques peut traiter des données nominales, ordinales et d’échelle; cependant, il n’est pas recommandé de mélanger différents niveaux de mesure.
L’analyse de cluster en deux étapes identifie les groupements en exécutant d’abord le pré-clustering, puis en exécutant des méthodes hiérarchiques. Parce qu’il utilise un algorithme de cluster rapide à l’avance, il peut gérer des ensembles de données volumineux qui prendraient beaucoup de temps à calculer avec des méthodes de cluster hiérarchiques. À cet égard, il s’agit d’une combinaison des deux approches précédentes. Le clustering en deux étapes peut gérer les données d’échelle et ordinales dans le même modèle et sélectionne automatiquement le nombre de clusters.
L’analyse hiérarchique des clusters suit trois étapes de base: 1) calculer les distances, 2) lier les clusters et 3) choisir une solution en sélectionnant le bon nombre de clusters.
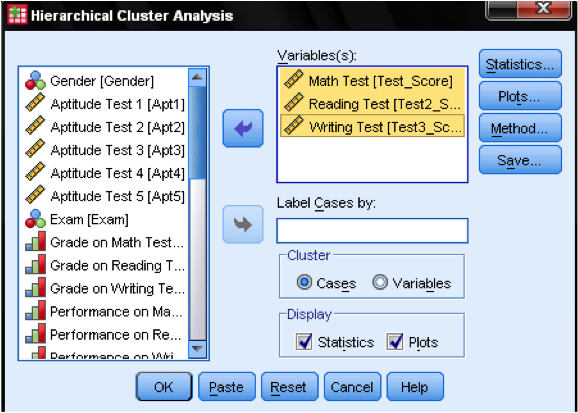
Tout d’abord, nous devons sélectionner les variables sur lesquelles nous basons nos clusters. Dans la fenêtre de dialogue, nous ajoutons les tests de mathématiques, de lecture et d’écriture à la liste des variables. Puisque nous voulons regrouper les cas, nous laissons le reste des graduations sur la valeur par défaut.
Dans la boîte de dialogue Statistiques we, nous pouvons spécifier si nous voulons sortir la matrice de proximité (ce sont les distances calculées dans la première étape de l’analyse) et l’appartenance prévue au cluster des cas dans nos observations. Encore une fois, nous laissons tous les paramètres par défaut.

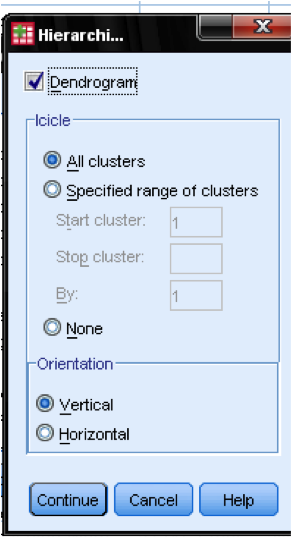
Dans la boîte de dialogue Tracés we nous devrions ajouter le dendrogramme. Le dendrogramme montrera graphiquement comment les clusters sont fusionnés et nous permettra d’identifier le nombre approprié de clusters.
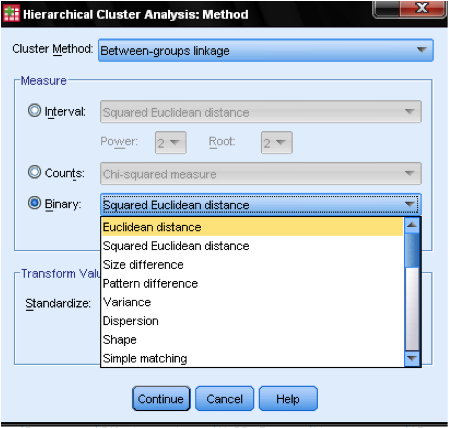
La méthode de la boîte de dialogue Method nous permet de spécifier la mesure de distance et la méthode de clustering. Tout d’abord, nous devons définir la mesure de distance correcte. SPSS propose trois grands blocs de mesures de distance pour les données d’intervalle (échelle), de comptage (ordinal) et de binaire (nominal).
Pour les données d’intervalle, la plus courante est la Distance euclidienne carrée. Il est basé sur la Distance euclidienne entre deux observations, qui est la racine carrée de la somme des distances au carré. Puisque la Distance euclidienne est carrée, elle augmente l’importance des grandes distances, tout en affaiblissant l’importance des petites distances.

Si nous avons des données ordinales (nombres), nous pouvons choisir entre le Chi Carré ou un Chi Carré normalisé appelé Phi-Carré. Pour les données binaires, la Distance Euclidienne au carré est couramment utilisée.

Dans notre exemple, nous choisissons l’Intervalle et la Distance Euclidienne Carrée.
Ensuite, nous devons choisir la méthode de cluster. Typiquement, les choix sont la liaison entre groupes (la distance entre les groupes est la distance moyenne de tous les points de données dans ces groupes), le voisin le plus proche (liaison unique: la distance entre les groupes est la plus petite distance entre deux points de données), le voisin le plus éloigné (liaison complète: la distance est la plus grande distance entre deux points de données) et la méthode de Ward (la distance est la distance de tous les groupes à la moyenne générale de l’échantillon). La liaison simple fonctionne mieux avec de longues chaînes de grappes, tandis que la liaison complète fonctionne mieux avec des blocs denses de grappes. La liaison entre groupes fonctionne avec les deux types de cluster. Il est recommandé d’utiliser d’abord une liaison unique. Bien que la liaison unique ait tendance à créer des chaînes de grappes, elle aide à identifier les valeurs aberrantes. Après avoir exclu ces valeurs aberrantes, nous pouvons passer à la méthode de Ward. La méthode de Ward utilise la valeur F (comme dans ANOVA) pour maximiser la signification des différences entre les clusters.
Une dernière considération est la normalisation. Si les variables ont des échelles et des moyens différents, nous pourrions vouloir standardiser soit les scores Z, soit en centrant l’échelle. Nous pouvons également transformer les valeurs en valeurs absolues si nous avons un ensemble de données où cela pourrait être approprié.