Hvad er Klyngeanalysen?
klyngeanalyse er en sonderende analyse, der forsøger at identificere strukturer i dataene. Klyngeanalyse kaldes også segmenteringsanalyse eller taksonomianalyse. Mere specifikt forsøger den at identificere homogene grupper af sager, hvis grupperingen ikke tidligere er kendt. Fordi det er sonderende, skelner det ikke mellem afhængige og uafhængige variabler. De forskellige klyngeanalysemetoder, som SPSS tilbyder, kan håndtere binære, nominelle, ordinære og skala (interval eller forhold) data.
klyngeanalyse bruges ofte sammen med andre analyser (såsom diskriminerende analyse). Forskeren skal kunne fortolke klyngeanalysen ud fra deres forståelse af dataene for at afgøre, om resultaterne fra analysen faktisk er meningsfulde.
typiske forskningsspørgsmål klyngeanalysesvarene er som følger:
- medicin-Hvad er de diagnostiske klynger? For at besvare dette spørgsmål ville forskeren udtænke et diagnostisk spørgeskema, der inkluderer mulige symptomer (for eksempel inden for psykologi, angst, depression osv.). Klyngeanalysen kan derefter identificere grupper af patienter, der har lignende symptomer.
- Marketing-Hvad er kundesegmenterne? For at besvare dette spørgsmål kan en markedsforsker foretage en undersøgelse, der dækker kundernes behov, holdninger, demografi og adfærd. Forskeren kan derefter bruge klyngeanalyse til at identificere homogene grupper af kunder, der har lignende behov og holdninger.
- uddannelse – Hvad er studentergrupper, der har brug for særlig opmærksomhed? Forskere kan måle psykologiske, evner og præstationsegenskaber. En klyngeanalyse kan derefter identificere, hvilke homogene grupper der findes blandt studerende (for eksempel højtydende i alle fag eller studerende, der udmærker sig i bestemte fag, men fejler i andre).
- biologi – hvad er arternes taksonomi? Forskere kan indsamle et datasæt af forskellige planter og notere forskellige attributter af deres fænotyper. En klyngeanalyse kan gruppere disse observationer i en række klynger og hjælpe med at opbygge en taksonomi af grupper og undergrupper af lignende planter.
andre teknikker, du måske vil prøve for at identificere lignende grupper af observationer, er K-analyse, multidimensionel skalering (MDS) og latent klasseanalyse.
Klyngeanalysen i SPSS
vores forskningsspørgsmål til dette eksempel klyngeanalyse er som følger:
hvilke homogene klynger af studerende dukker op baseret på standardiserede testresultater i matematik, læsning og skrivning?
i SPSS kan Klyngeanalyser findes i analyser/klassificer…. SPSS tilbyder tre metoder til klyngeanalysen: K-betyder klynge, hierarkisk klynge og totrins klynge.
K-betyder klynge er en metode til hurtigt at klynge store datasæt. Forskeren definerer antallet af klynger på forhånd. Dette er nyttigt at teste forskellige modeller med et andet antaget antal klynger.
hierarkisk klynge er den mest almindelige metode. Det genererer en række modeller med klyngeløsninger fra 1 (alle tilfælde i en klynge) til n (hvert tilfælde er en individuel klynge). Hierarkisk klynge fungerer også med variabler i modsætning til sager; det kan klynge variabler sammen på en måde, der ligner faktoranalyse. Derudover kan hierarkisk klyngeanalyse håndtere nominelle, ordinære og skaladata; det anbefales dog ikke at blande forskellige måleniveauer.
totrins klyngeanalyse identificerer grupperinger ved først at køre præklynger og derefter ved at køre hierarkiske metoder. Fordi den bruger en hurtig klyngealgoritme på forhånd, kan den håndtere store datasæt, der ville tage lang tid at beregne med hierarkiske klyngemetoder. I den henseende er det en kombination af de to foregående tilgange. To-trins klyngedannelse kan håndtere skala og ordinære data i samme model, og det vælger automatisk antallet af klynger.
den hierarkiske klyngeanalyse følger tre grundlæggende trin: 1) Beregn afstande, 2) link klyngerne og 3) Vælg en løsning ved at vælge det rigtige antal klynger.
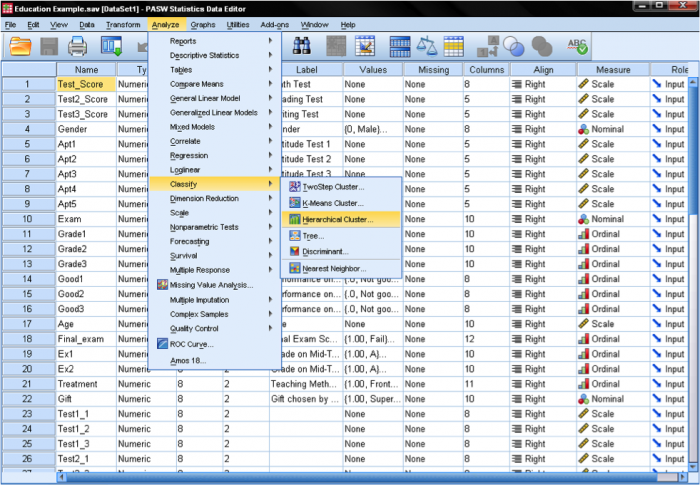
først skal vi vælge de variabler, som vi baserer vores klynger på. I dialogvinduet tilføjer vi matematik -, læse-og skrivetestene til listen over variabler. Da vi ønsker at klynge sager, forlader vi resten af afkrydsningsfelterne som standard.
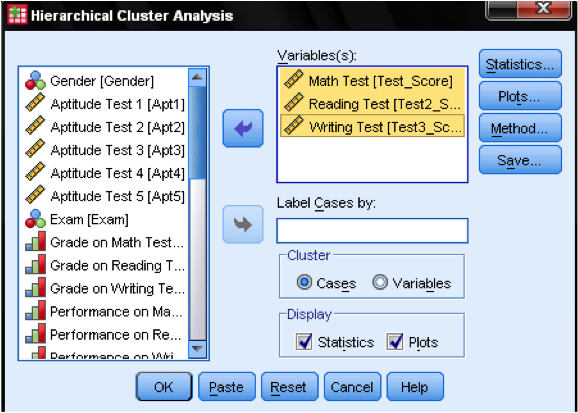
i dialogboksstatistikken … kan vi specificere, om vi vil udsende nærhedsmatricen (dette er afstandene beregnet i det første trin i analysen) og det forudsagte klyngemedlemskab af sagerne i vores observationer. Igen forlader vi alle indstillinger som standard.

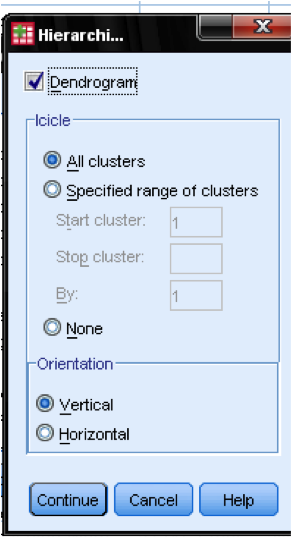
i dialogboksen Plots … skal vi tilføje Dendrogrammet. Dendrogrammet viser grafisk, hvordan klyngerne flettes og giver os mulighed for at identificere, hvad det passende antal klynger er.
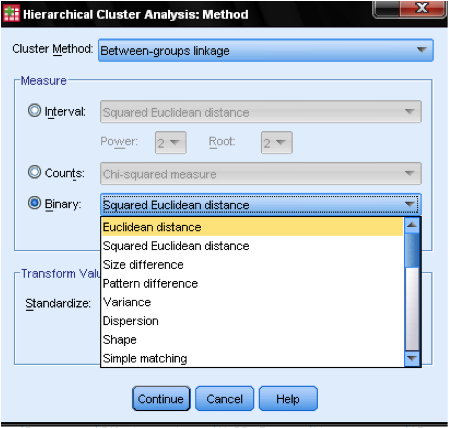
dialogboksmetoden … giver os mulighed for at specificere afstandsmålet og klyngemetoden. Først skal vi definere den korrekte afstandsmåling. SPSS tilbyder tre store blokke af afstandsmålinger for interval (skala), tællinger (ordinære) og binære (nominelle) data.
for intervaldata er den mest almindelige kvadratiske euklidiske afstand. Det er baseret på den euklidiske afstand mellem to observationer, som er kvadratroden af summen af kvadrerede afstande. Da den euklidiske afstand er kvadreret, øger den vigtigheden af store afstande, mens den svækker vigtigheden af små afstande.

hvis vi har ordinære data (tæller), kan vi vælge mellem Chi-firkant eller en standardiseret Chi-firkant kaldet Phi-firkant. For binære data er den kvadrerede euklidiske afstand almindeligt anvendt.

i vores eksempel vælger vi Interval og firkantet euklidisk afstand.
Dernæst skal vi vælge Klyngemetoden. Typisk er valg mellem grupper kobling (afstand mellem klynger er den gennemsnitlige afstand for alle datapunkter inden for disse klynger), nærmeste nabo (enkelt kobling: afstand mellem klynger er den mindste afstand mellem to datapunkter), længst nabo (komplet kobling: afstand er den største afstand mellem to datapunkter) og afdelingens metode (afstand er afstanden for alle klynger til det store gennemsnit af prøven). Enkelt kobling fungerer bedst med lange kæder af klynger, mens komplet kobling fungerer bedst med tætte klatter af klynger. Mellem-grupper kobling arbejder med begge klynge typer. Det anbefales at bruge en enkelt kobling først. Selvom enkeltforbindelse har tendens til at skabe kæder af klynger, hjælper det med at identificere outliers. Efter at have udelukket disse outliers, kan vi gå videre til afdelingens metode. Menighedens metode bruger f-værdien (som i ANOVA) for at maksimere betydningen af forskelle mellem klynger.
en sidste overvejelse er standardisering. Hvis variablerne har forskellige skalaer og midler, vil vi måske standardisere enten til scoren eller ved at centrere skalaen. Vi kan også omdanne værdierne til absolutte værdier, hvis vi har et datasæt, hvor dette kan være passende.