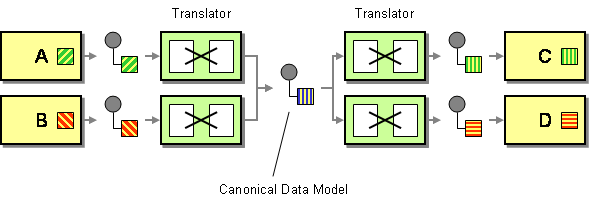
en kanonisk datamodell definieras i Företagsintegrationsmönster som lösningen för att minimera beroenden när man integrerar applikationer som använder olika dataformat. Med andra ord bör en komponent (en applikation eller en tjänst) kommunicera med en annan komponent via ett dataformat som skulle vara oberoende av båda komponentdataformaten.
två saker att lyfta fram här. Först definierade jag en komponent som antingen en applikation eller en tjänst eftersom sådana modeller används/användes i samband med applikationsintegration och serviceorientering. För det andra talar vi här om ett koncept som endast bör användas som ett transportdataformat. Du bör inte använda ett kanoniskt dataformat som den interna strukturen i ditt datalager.
teoretiskt sett är fördelarna ganska uppenbara. Ett kanoniskt dataformat minskar kopplingen mellan applikationer, minskar antalet översättningar som ska utvecklas för att integrera en uppsättning komponenter etc. Ganska intressant rätt? En enda datamodell är förståelig för hela IT-landskapet och en uppsättning människor (Utvecklare, systemanalytiker, affärsintressenter etc.) vem kan dela samma vision av ett givet koncept.
för praktiska ändamål är implementeringen av sådana modeller dock sällan effektiv.
en person är inte samma koncept för marknadsförings-och supportavdelningen i ett försäkringsbolag. En flygning för ett flygledningssystem har en annan betydelse beroende på om den fylldes av en pilot eller om det är en pågående flygning ovanpå ditt luftrum. En PLM-del har en helt annan representation beroende på om den just har designats eller om den måste underhållas av ett supportteam.
i de flesta sammanhang resulterar design av en kanonisk datamodell i en stor datamodell med en full uppsättning valfria attribut och mycket få obligatoriska (som identifierarna). Även om det främst var utformat för att underlätta komponentintegration, kommer du bara att komplicera det. Under tiden kommer din modell att skapa mycket frustration bland användarna på grund av dess inneboende komplexitet (när det gäller användning och hantering). Dessutom, när det gäller kopplingsfrågan, flyttar du bara den någon annanstans. Istället för att kopplas till ett komponentdataformat blir du tätt kopplad till ett gemensamt dataformat som kommer att användas av hela IT-landskapet och utsätts för mycket frekventa förändringar.
i ett nötskal, i de flesta sammanhang, bör en kanonisk datamodell betraktas som ett antimönster. Vad är det andra alternativet än att överväga att du fortfarande vill minimera beroenden mellan två komponenter som utbyter data?
Domain Driven Design (DDD) rekommenderar att man introducerar begreppet avgränsat sammanhang. Ett avgränsat sammanhang är helt enkelt ett uttryckligt sammanhang där en modell gäller med tydliga gränser med andra avgränsade sammanhang. Beroende på din organisation kan ett avgränsat sammanhang hänvisa till en funktionell domän där ett objekt används, det kan hänvisa till själva objekttillståndet etc.
i så fall skulle den kanoniska datamodellen som sådan helt enkelt vara den gula delen i följande diagram:
skärningspunkten mellan A, B och C representerar uppsättningen attribut som måste finnas där oavsett sammanhanget (i princip de obligatoriska attributen för den tidigare stora CDM). Denna del bör fortfarande utformas noggrant på grund av dess centrala roll. Det är viktigt att vara pragmatisk. Om det i ditt sammanhang inte är meningsfullt att ha en sådan gemensam modell, bör du helt enkelt kassera den.
det som också är viktigt är en korsning mellan två sammanhang (A och B, B och C, C och A). Hur kartlägger man en objektrepresentation från ett sammanhang till ett annat? Vilka är de uttryckliga attributen som ska delas i två sammanhang? Vilka är de gemensamma affärsbegränsningarna mellan två sammanhang? Dessa frågor bör fortfarande besvaras av ett tvärgående team men ur ett affärsperspektiv är det vettigt att höja dem. Det var inte alltid fallet med en enda CDM delad över potentiellt motsatta sammanhang.
men när det gäller de delar som inte delas med andra sammanhang (i vitt) bör det inte ingå i en företagsdatamodell. Du borde vara pragmatisk. Till exempel, om en delmängd är specifik för en viss domän, bör det vara upp till domänexperterna att modellera den själva.
en viktig utmaning är dock att identifiera de begränsade kontexterna och det kan vara värt att påminna här Conways lag:
varje organisation som utformar ett system kommer oundvikligen att producera en design vars struktur är en kopia av organisationens kommunikationsstruktur.
de avgränsade kontexterna ska inte nödvändigtvis mappas på den nuvarande organisationen. Till exempel kan ett avgränsat sammanhang omfatta flera avdelningar. Att bryta organisatoriska silor borde fortfarande vara ett mål för de flesta företag.
dessutom introducerar DDD begreppet Anti-Corruption Layer (ACL). Detta mönster kan hänvisa till en lösning för en äldre migrering (genom att införa ett förmedlingslager mellan det gamla och det nya systemet för att förhindra datakvalitetsproblem etc.). Men i vårt sammanhang när vi talar om korruption är det relaterat till datamodellering skuld Du kan införa för att lösa kortsiktiga problem.
Låt oss ta exemplet med två system som ansvarar för att hantera ett givet tillstånd av en PLM-del (en del är en fysisk artikel som produceras eller köps och sedan monteras som en helikopterrotor till exempel). Ett äldre system (Låt oss kalla det SystemA) ansvarar för att hantera designfasen och du måste implementera ett nytt system (låt oss kalla det SystemZ) som ansvarar för att hantera underhållsfasen. Hela it-applikationslandskapet delar samma gemensamma delidentifierare (partId) förutom SystemA som inte är medveten om det. Istället för partId hanterar SystemA sin egen identifierare, systemAId. Eftersom SystemZ måste anropas SystemA med systemAId, kan en heuristisk vara att integrera systemAId som en del av systemz datamodell.
Detta är ett vanligt misstag du bör undvika. Du skadade helt enkelt din datamodell på grund av en kortsiktig situation.
ACL-mönstret kunde ha varit en lösning här. SystemZ kunde ha implementerat sitt eget dataformat (utan någon extern korruption som systemAId). Då skulle det ha varit upp till ett förmedlingslager att hantera översättningen mellan partId och systemAId.
ACL-mönstret tillämpas på vårt ämne för att implementera ett lager mellan två olika avgränsade sammanhang. En komponent är inte medveten om hur man kallar en annan komponent som inte är en del av sin egen avgränsade sammanhang. Istället är en komponent bara medveten om hur man kartlägger sin egen datastruktur på dataformatet för det avgränsade sammanhanget som det tillhör.
förresten, detta är en tumregel. En komponent ska tillhöra endast ett avgränsat sammanhang. Det är också därför DDD är en bra passform för mikroservicearkitektur. På grund av den finkorniga granulariteten är det lättare att följa denna regel.
Sammanfattningsvis bör en kanonisk modell som sådan betraktas som ett antimönster i de flesta fall. Du bör försöka implementera det begränsade kontextbegreppet som betyder en modell per sammanhang med uttryckliga gränser mellan kontexterna. Två komponenter som ingår i olika avgränsade sammanhang bör kommunicera genom ett Antikorruptionslager för att förhindra korruption av datamodellering.