detta är en stegvis guide om hur du kör k-means klusteranalys på ett Excel-kalkylblad från början till slut. Observera att det finns en Excel-mall som automatiskt kör klusteranalys tillgänglig för gratis nedladdning på denna webbplats. Men om du vill veta hur man kör en k-betyder kluster på Excel själv, då är den här artikeln för dig.
förutom den här artikeln har jag också en video genomgång av hur man kör klusteranalys i Excel.
- steg ett-börja med din dataset
- steg två-om bara två variabler, använd en scatter-graf på Excel
- steg tre-beräkna avståndet från varje datapunkt till mitten av ett kluster
- hur fungerar beräkningen?
- Steg fyra-beräkna medelvärdet (medelvärdet) för varje klusteruppsättning
- Steg fem-Upprepa steg 3-avståndet från det reviderade medelvärdet
- sista steget-graf och sammanfatta kluster
steg ett-börja med din dataset
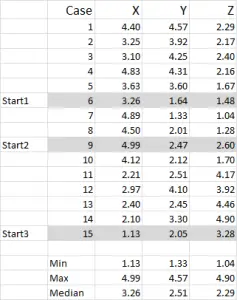
Figur 1
i det här exemplet använder jag 15 fall (eller respondenter), där vi har data för tre variabler – generiskt märkta X, Y och Z.
du bör märka att data skalas 1-5 i det här exemplet. Dina uppgifter kan vara i någon form förutom en nominell dataskala (Se artikel om vilka data som ska användas).
jag föredrar att använda skalad data – men det är inte obligatoriskt. Anledningen till detta är att ”innehålla” eventuella avvikelser. Säg till exempel att jag använder inkomstdata (en demografisk åtgärd) – de flesta uppgifterna kan vara runt $40,000 till $100,000, men jag har en person med en inkomst på $5m. det är bara lättare för mig att klassificera den personen i inkomstgruppen ”över $250,000” och skala inkomst 1-9 – men det är upp till dig beroende på de data du arbetar med.
du kan se från denna exempeluppsättning att tre startpositioner har markerats-vi kommer att diskutera dem i steg tre nedan.
steg två-om bara två variabler, använd en scatter-graf på Excel
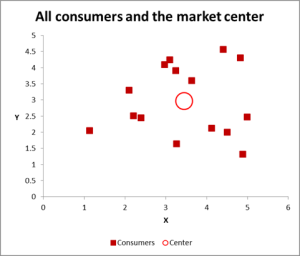
Figur 2
i det här klusteranalysexemplet använder vi tre variabler – men om du bara har två variabler att klustra, är ett scatter-diagram ett utmärkt sätt att börja. Och ibland kan du klustera data via visuella medel.
som du kan se i denna scatter-graf har varje enskilt fall (vad jag kallar en konsument för det här exemplet) kartlagts, tillsammans med genomsnittet (medelvärdet) för alla fall (den röda cirkeln).
beroende på hur du ser data/diagram – det verkar finnas ett antal kluster. I det här fallet kan du identifiera tre eller fyra relativt distinkta kluster – som visas i nästa diagram.
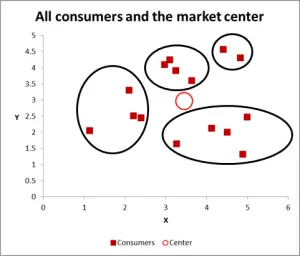
Figur 3
med denna nästa graf har jag synligt identifierat sannolikt kluster och cirkulerat dem. Som jag har föreslagit, ett bra tillvägagångssätt när det bara finns två variabler att överväga – men är det här fallet har vi tre variabler (och du kan ha mer), så det här visuella tillvägagångssättet fungerar bara för grundläggande dataset – så nu ska vi titta på hur man gör Excel-beräkningen för k-betyder clustering.
steg tre-beräkna avståndet från varje datapunkt till mitten av ett kluster
för detta genomgångsexempel, låt oss anta att vi bara vill identifiera tre segment/kluster. Ja, det finns fyra kluster som framgår av diagrammet ovan, men det ser bara på två av variablerna. Observera att du kan använda detta Excel – tillvägagångssätt för att identifiera så många kluster du vill-Följ bara samma koncept som förklaras nedan.
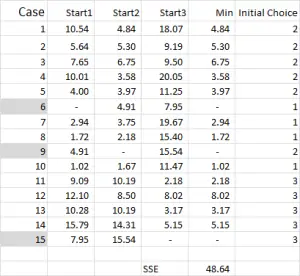
Figur 4
för K-means clustering väljer du vanligtvis några slumpmässiga fall (utgångspunkter eller frön) för att få analysen igång.
i det här exemplet-eftersom jag vill skapa tre kluster, behöver jag tre utgångspunkter. För dessa startpunkter har jag valt fall 6, 9 och 15-men alla slumpmässiga punkter kan också vara lämpliga.
anledningen till att jag valde dessa fall är att – när man bara tittade på variabel X-fall 6 var medianen, Fall 9 var maximalt och fall 15 var minimum. Detta tyder på att dessa tre fall skiljer sig något från varandra, så bra utgångspunkter som de sprids ut.
se artikeln om varför klusteranalys ibland genererar olika resultat.
hänvisar till tabellutgången – det här är vår första beräkning i Excel och det genererar vårt ”initiala val” av kluster. Start 1 är data för fall 6, start 2 är fall 9 och start 3 är fall 15. Du bör notera att skärningspunkten mellan var och en av dessa ger en 0 (-) i tabellen.
hur fungerar beräkningen?
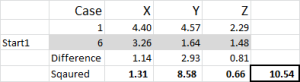
Figur 5
Låt oss titta på det första numret i tabellen – fall 1, Starta 1 = 10.54.
kom ihåg att vi godtyckligt har utsett Fall 6 för att vara vår slumpmässiga startpunkt för kluster 1. Vi vill beräkna avståndet och vi använder metoden summan av kvadrater – som visas här. Vi beräknar skillnaden mellan var och en av de tre datapunkterna i uppsättningen och kvadrerar sedan skillnaderna och summerar dem sedan.
vi kan göra det” mekaniskt ” som visas här – men Excel har en inbyggd formel att använda: SUMXMY2-det här är mycket effektivare att använda.
med hänvisning till Figur 4 hittar vi sedan det minsta avståndet för varje fall från var och en av de tre startpunkterna – detta berättar vilket kluster (1, 2 eller 3) som fallet är närmast – vilket visas i ’initial choice column’.
Steg fyra-beräkna medelvärdet (medelvärdet) för varje klusteruppsättning
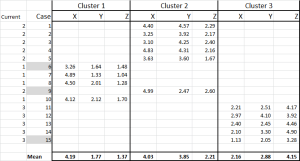
Figur 6
vi har nu tilldelat varje fall till sitt ursprungliga kluster-och vi kan lägga ut det med ett IF-uttalande i en tabell (som visas i Figur 6).
längst ner i tabellen har vi medelvärdet (medelvärdet) för vart och ett av dessa fall. N0w-istället för att förlita sig på bara en ”representativ” datapunkt – har vi en uppsättning fall som representerar var och en.
Steg fem-Upprepa steg 3-avståndet från det reviderade medelvärdet
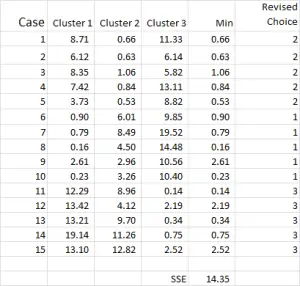
Figur 7
klusteranalysprocessen blir nu en fråga om att upprepa steg 4 och 5 (iterationer) tills klusterna stabiliseras.
varje gång vi använder det reviderade medelvärdet för varje kluster. Därför visar Figur 7 vår andra iteration-men den här gången använder vi de medel som genereras längst ner i Figur 6 (istället för startpunkterna från Figur 1).
du kan nu se att det har skett en liten förändring i klusterapplikationen, med fall 9 – en av våra utgångspunkter – omfördelas.
du kan också se summan av kvadratfel (SSE) beräknat längst ner – vilket är summan av varje minsta avstånd. Vårt mål är att nu upprepa steg 4 och 5 tills SSE bara visar minimal förbättring och/eller klusterallokeringsförändringarna är mindre på varje iteration.
sista steget-graf och sammanfatta kluster
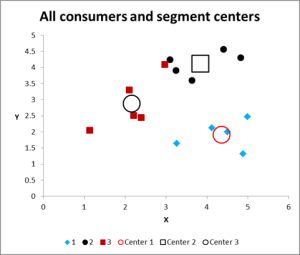
figur 8
efter att ha kört flera iterationer har vi nu utmatningen för att grafera och sammanfatta data.
här är utdatadiagrammet för detta klusteranalys Excel-exempel.
som du kan se visas tre distinkta kluster tillsammans med centroiderna (genomsnittet) för varje kluster – de större symbolerna.
vi kan också presentera dessa data i en tabellform om det behövs, som vi har utarbetat i Excel.
ta en titt på fallet i kluster 3 – den lilla röda torget bredvid den svarta pricken i den övre mitten av diagrammet. Det fallet sitter där på grund av påverkan av den tredje variabeln, som inte visas på detta två variabla diagram.