nyligen har det varit ett nytt ändringsförslag för Cassandra indexering som försöker minska avvägningen mellan användbarhet och stabilitet: gör where-klausulen mycket mer intressant och användbar för slutanvändare. Denna nya metod kallas Storage-Attached Indexing (SAI). Det är inte det snabbaste namnet, men vad förväntar du dig? Ingenjörer är inte kända för att namnge saker, men cool teknik är aldrig ett skämt. SAI har fångat Cassandra-samhällets uppmärksamhet, men varför? Indexering av data är inte ett nytt koncept i databasvärlden.
hur vi indexerar våra data kan förändras över tid baserat på önskade användningsfall och distributionsmodeller. Cassandra byggdes genom att kombinera aspekter av Dynamo och Big Table för att minska komplexiteten i Läs-och skrivkostnader genom att hålla sakerna enkla. Komplexiteten hos Cassandra har mestadels reserverats för sin distribuerade natur och som ett resultat skapade en avvägning för utvecklare. Om du vill ha den otroliga omfattningen av Cassandra måste du spendera tid på att lära dig datamodell. Databasindex är avsedda att förbättra din datamodell och göra dina frågor mer effektiva. För Cassandra har de funnits i någon form sedan projektets tidiga dagar. Den olyckliga verkligheten är att de inte har matchat bra med användarnas krav. All användning av indexering kommer med en lång lista av kompromisser och varningar till den grad att de oftast undviks och för vissa, bara en hård Nej. Som ett resultat har användarna lärt sig att datamodellera med grundläggande frågor för att få bästa prestanda.
dessa dagar kan komma bakom oss och funktioner som SAI hjälper oss att komma dit.
sekundära index i distribuerade databaser
inte alla index skapas lika. Primära index är också kända som den unika nyckeln, eller i Cassandra-ordförråd, partitionsnyckel. Som en primär åtkomstmetod i databasen använder Cassandra partitionsnyckeln för att identifiera noden som håller data sedan datafilen som lagrar partitionen av data. Primär index läser i Cassandra är ganska enkla men utanför ramen för denna artikel. Du kan läsa mer om dem här.
sekundära index skapar en helt annan och unik utmaning i en distribuerad databas. Låt oss titta på en exempeltabell för att göra några punkter:
skapa TABELLANVÄNDARE (
id lång,
förnamn text,
efternamn text,
land text,
skapad tidsstämpel,
primärnyckel (id)
);
en primär indexuppslag skulle vara ganska enkel så här:
välj förnamn, efternamn från användare där id = 100;
vad händer om jag ville hitta alla i Frankrike? Som någon som är bekant med SQL kan du förvänta dig att den här frågan ska fungera:
välj förnamn, efternamn från användare där country = ’FR’;
utan att skapa ett sekundärt index i Cassandra misslyckas denna fråga. Det grundläggande åtkomstmönstret i Cassandra är av partitionsnyckel. I en icke-distribuerad databas som en traditionell RDBMS är varje kolumn i tabellen lätt synlig för systemet. Du kan fortfarande komma åt kolumnen även om det inte finns något index eftersom de alla finns i samma system-och datafiler. Index i det här fallet hjälper till att minska frågestunden genom att göra sökningen effektivare.
i ett distribuerat system som Cassandra finns kolumnvärdena på varje datanod och måste inkluderas i frågeplanen. Detta ställer in vad vi kallar ”Scatter-Gather” – scenariot där en fråga skickas till varje nod, data samlas in, slås samman och returneras till användaren. Även om denna operation kan göras över flera noder samtidigt, är latenshanteringen nere på hur snabbt noden kan hitta kolumnvärdet.
snabb granskning av Cassandra data skriver
du kanske tänker att lägga till index handlar om att läsa data, vilket verkligen är slutmålet. Men när man bygger en databas är de tekniska utmaningarna vid indexering partiska vid den punkt där data skrivs. Att acceptera data med den snabbaste hastigheten medan du formaterar indexerna i den mest optimala formen för läsningar är en stor utmaning. Det är värt att göra en snabb genomgång av hur data skrivs i en Cassanda-databas på den enskilda nodnivån. Se följande diagram när jag förklarar hur det fungerar.
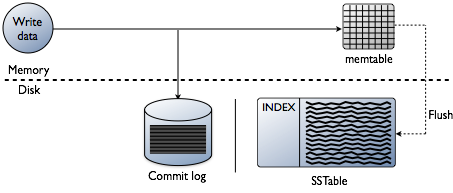
när data presenteras för en nod, som vi kallar en mutation, är skrivvägen för Cassandra mycket enkel och optimerad för den operationen. Detta gäller också för många andra databaser baserade på Log-Structured Merge (LSM) träd.
- validera data är rätt format. Typ kontrollera mot schemat.
- skriv data i svansen på en commit-logg. Ingen söker, bara nästa plats på filpekaren.
- skriv data i en memtable, som bara är en hashmap av schemat i minnet.
klar! Mutationen erkänns när dessa saker händer. Jag älskar hur enkelt detta jämförs med andra databaser som kräver ett lås och försöker utföra en skrivning.
senare, när memtables fyller fysiskt minne, skriver en spolningsprocess ut segment i en enda pass på disk till en fil som heter en Sstable (Sorted Strings Table). Den medföljande begå loggen raderas nu när persistensen har flyttat till SSTable. Denna process fortsätter att upprepas när data skrivs till noden.
viktig detalj: SSTables är oföränderliga. När de är skrivna blir de aldrig uppdaterade, Bara ersatta. Så småningom, när mer data skrivs, sammanfogar en bakgrundsprocess som kallas komprimering och sorterar sstables till nya som också är oföränderliga. Det finns många komprimeringssystem, men i grunden utför de alla denna funktion.
du har nu tillräckligt med grundläggande grund på Cassandra så att vi kan bli tillräckligt nördiga med index. Eventuellt ytterligare djup av information lämnas som en övning för läsaren.
problem med tidigare indexering
Cassandra har haft två tidigare sekundära indexerings implementeringar. Lagring bifogad sekundär indexering (SASI) och sekundära index, som vi hänvisar till som 2i. återigen, min punkt om ingenjörer som inte är prickiga med namn håller här uppe. Sekundära index har varit en del av Cassandra från början, men implementeringarna har gjort dem besvärliga för slutanvändare med sin långa lista över kompromisser. De två huvudsakliga problem som vi ständigt har behandlat som ett projekt är skrivförstärkning och indexstorlek på disken. Som ett resultat kan de vara frustrerande frestande för nya användare bara för att få dem att misslyckas senare i distributionen. Låt oss titta på var och en.
sekundära index (2i) — detta ursprungliga arbete i projektet började som en bekvämlighetsfunktion för tidiga Sparsamhetsdatamodeller. Senare, när Cassandra Query Language ersatte sparsamhet som den föredragna frågemetoden för Cassandra, behölls 2i-funktionalitet med syntaxen ”skapa INDEX”. Om du hade kommit från SQL var detta ett riktigt enkelt sätt att lära sig lagen om oavsiktliga konsekvenser. Precis som i SQL-indexering, ju mer du lägger till desto mer påverkar du skrivprestanda. Men med Cassandra utlöste detta det större problemet med skrivförstärkning. Med hänvisning till skrivvägen ovan lade sekundära index till ett nytt steg i sökvägen. När en mutation i en indexerad kolumn inträffar utlöses en indexeringsoperation som indexerar data i en separat indexfil. Fler index på ett bord kan dramatiskt öka diskaktivitet i en enda rad skrivoperation. När en nod tar en hög mängd mutationer kan resultatet vara mättad diskaktivitet som kan göra de enskilda noderna instabila, vilket ger 2i den förtjänade vägledningen av ”använd sparsamt.”Indexstorleken är ganska linjär i denna implementering men med omindexering kan mängden diskutrymme som behövs vara svårt att planera för i ett aktivt kluster.
Storage Attached Secondary Indexing (SASI) — SASI designades ursprungligen av ett litet team på Apple för att lösa ett specifikt frågeproblem och inte det allmänna problemet med sekundära index. För att vara rättvis mot det laget kom det ifrån dem i ett användningsfall som det aldrig var utformat för att lösa. Välkommen till open source alla. De två frågetyper som SASI har utformats för att ta itu med:
- hitta rader baserat på partiell datamatchning. Jokertecken, eller liknande frågor.
- Range frågor om glesa data, specifikt tidsstämplar. Hur många poster passar i en tidsintervall typ frågor.
det gjorde båda dessa operationer ganska bra och det tog också upp frågan om skrivförstärkning med legacy 2i. eftersom mutationer presenteras för en Cassandra-nod indexeras data i minnet under den första skrivningen, ungefär som hur memtables används. Ingen diskaktivitet krävs på en permutation. En enorm förbättring på kluster med mycket skrivaktivitet. När memtables spolas till sstables spolas motsvarande index för data. Varje indexfil som skrivs är oföränderlig och kopplad till sstable, därav namnet Storage bifogat. När kompaktering sker omdexeras data och skrivs till en ny fil när nya sstables skapas. Ur en diskaktivitetssynpunkt var detta en stor förbättring. Nackdelen med SASI var främst i storleken på de skapade indexen. Formatet på diskindexet orsakade en enorm mängd diskutrymme som användes för varje indexerad kolumn. Detta gör dem mycket svåra att hantera för operatörer. För övrigt, SASI markerades som experimentell och inte mycket har hänt när det gäller funktionsförbättring. Många buggar har hittats över tid med dyra korrigeringar som har fört diskussionen om SASI bör tas bort helt och hållet. Om du behöver det djupaste dyket på den här funktionen gjorde Duy Hai Doan ett fantastiskt jobb med att bryta ner hur SASI fungerar.
Vad gör SAI bättre
det första, bästa svaret på den frågan är att SAI är evolutionär i naturen. Ingenjörer på DataStax insåg att kärnarkitekturen för sekundär indexering behövde åtgärdas från grunden men med solida lärdomar som har lärt sig från tidigare implementeringar. Att ta itu med problemen med skrivförstärkning och indexfilstorlek samtidigt som man skapar en sökväg för bättre frågeförbättringar i Cassandra har varit det primära uppdraget. Hur behandlar SAI båda dessa ämnen?
Skrivförstärkning-som vi lärde oss från SASI var in-memory indexering och spolningsindex med SSTables det rätta sättet att hålla sig i linje med hur Cassandra write-path fungerar, samtidigt som vi lägger till ny funktionalitet. Med SAI, när mutationen erkänns, vilket betyder helt engagerad, indexeras data. Med optimeringar och mycket testning har påverkan på skrivprestanda förbättrats avsevärt. Du borde se bättre än en 40% ökning av genomströmningen och över 200% bättre skriv latenser över 2i. med det sagt bör du fortfarande planera en ökning med 2x latens och genomströmning på indexerade tabeller jämfört med icke-indexerade tabeller. För att citera Duy Hai Doan, ”det finns ingen magi”, bara bra teknik.
Indexstorlek-Detta är den mest dramatiska förbättringen och utan tvekan där mest arbete har gjorts. Om du följer världen av databasinternaler vet du att datalagring fortfarande är ett livligt fält fyllt med ständigt utvecklande förbättringar. SAI använder två olika typer av indexeringsscheman baserat på datatypen.
- Text – inverterade index skapas med termer uppdelade i en ordbok. Den största förbättringen är från användningen av Trie baserad indexering som erbjuder mycket bättre komprimering vilket innebär mindre indexstorlekar.
- numeriskt – med hjälp av en datastruktur som kallas block kd-träd, taget från Lucene, som erbjuder utmärkt intervallfrågeprestanda. En separat rad-ID-lista upprätthålls för att optimera för frågor om tokenorder.
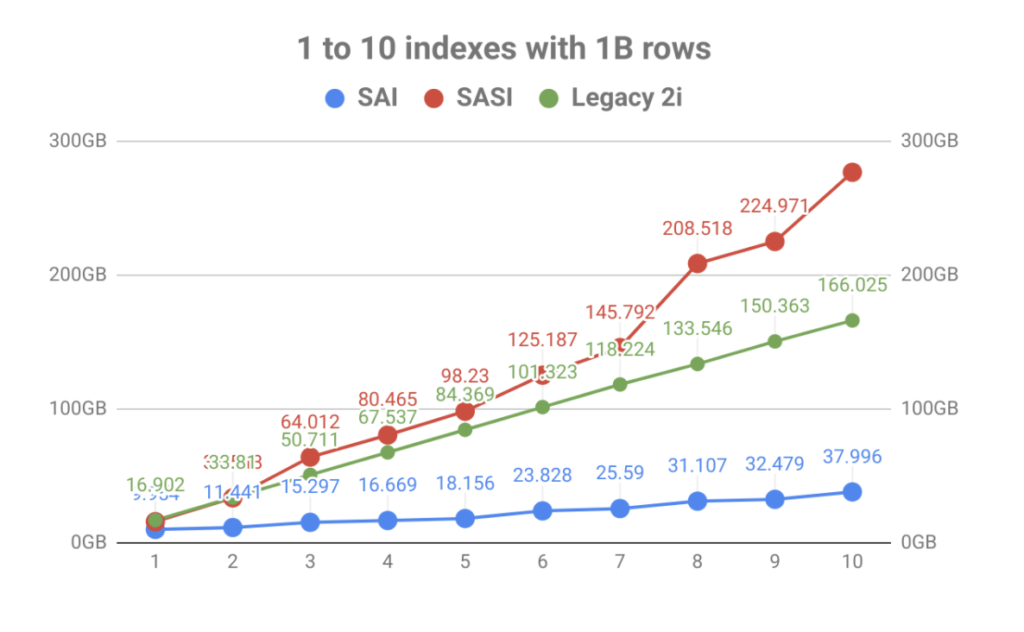
med en stark betoning på indexlagring var resultatet en massiv förbättring av volymen jämfört med antalet tabellindex. Som du kan se i diagrammet nedan förmörkades den snabba indexeringen av SASI snabbt av explosionen av diskanvändning. Det gör inte bara operativ planering en smärta, men indexfilerna måste läsas under komprimeringshändelser som kan mätta skivor som leder till nodprestandaproblem.
utanför skrivförstärkning och indexstorlek möjliggör sai: s interna arkitektur ytterligare expansion och extra funktionalitet i framtiden. Detta är i linje med projektmålen att vara mer modulära i framtida byggnader. Ta en titt på några av de andra Cep: erna som väntar och du kan se att detta bara är början.
Var går SAI härifrån?
DataStax har erbjudit SAI till Apache Cassandra-projektet genom Cassandra-förbättringsprocessen som CEP-7. Diskussionen pågår nu för att ingå i 4.X gren av Cassandra.
om du vill prova detta nu innan det är en del av Apache Cassandra-projektet, har vi ett par platser för dig att gå. För operatörer eller personer som gillar lite mer teknisk hands-on kan du ladda ner den senaste DataStax Enterprise 6.8. Om du är utvecklare är SAI nu aktiverat i DataStax Astra, vår Cassandra som en tjänst. Du kan skapa en free-forever-nivå för att leka med syntax och ny where-klausulfunktionalitet. Med det lär du dig hur du använder den här funktionen genom att gå till sidan Cassandra Indexing Skills och inkludera dokumentation.