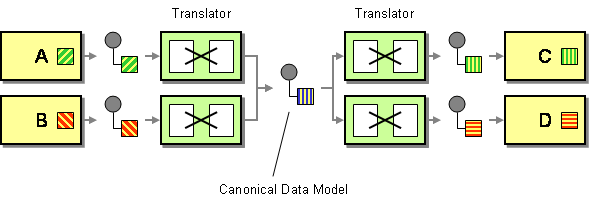
un model de date canonice este definit în modelele de integrare a întreprinderii ca soluție pentru a minimiza dependențele la integrarea aplicațiilor care utilizează diferite formate de date. Cu alte cuvinte, o componentă (o aplicație sau un serviciu) ar trebui să comunice cu o altă componentă printr-un format de date care ar fi independent de ambele formate de date componente.
două lucruri de subliniat aici. Mai întâi am definit o componentă fie ca o aplicație, fie ca un serviciu, deoarece astfel de modele sunt/au fost utilizate în contextul integrării aplicațiilor și orientării către servicii. În al doilea rând, vorbim aici despre un concept care ar trebui utilizat exclusiv ca format de date de transport. Nu trebuie să utilizați un format de date canonice ca structură internă a magazinului dvs. de date.
Teoretic, avantajele sunt destul de evidente. Un format de date canonic reduce cuplarea dintre aplicații, reduce numărul de traduceri care trebuie dezvoltate pentru integrarea unui set de componente etc. Destul de interesant nu? Un singur model de date este ușor de înțeles de întregul peisaj IT și de un set de oameni (Dezvoltatori, analiști de sistem, părți interesate de afaceri etc.) care pot împărtăși aceeași viziune a unui concept dat.
în scopuri practice, implementarea unor astfel de modele este rareori eficientă.
o persoană nu este același concept pentru departamentul de marketing și asistență dintr-o companie de asigurări. Un zbor pentru un sistem de management al traficului aerian are o semnificație diferită în funcție de dacă a fost completat de un pilot sau dacă este un zbor în curs de desfășurare deasupra spațiului aerian. O parte PLM are o reprezentare complet diferită în funcție dacă tocmai a fost proiectată sau dacă trebuie întreținută de o echipă de asistență.
în majoritatea contextelor, proiectarea unui model de date canonice are ca rezultat un model de date mare, cu un set complet de atribute opționale și foarte puține obligatorii (cum ar fi identificatorii). Chiar dacă a fost conceput în primul rând pentru a ușura integrarea componentelor, îl veți complica. Între timp, modelul dvs. va crea o mulțime de frustrare în rândul utilizatorilor din cauza complexității sale inerente (în ceea ce privește utilizarea și gestionarea). În plus, în ceea ce privește problema cuplării, o mutați doar în altă parte. În loc să fiți cuplat la un format de date component, deveniți strâns cuplat la un format de date comun care va fi utilizat de întregul peisaj IT și supus unor modificări foarte frecvente.
pe scurt, în majoritatea contextelor, un model de date canonice ar trebui considerat un anti-model. Care este cealaltă opțiune decât considerând că ar trebui să doriți în continuare să minimalizați dependențele dintre două componente care fac schimb de date?
Domain Driven Design (DDD) recomandă introducerea conceptului de context delimitat. Un context delimitat este pur și simplu un context explicit în care un model se aplică cu limite clare cu alte contexte mărginite. În funcție de organizația dvs., un context delimitat s-ar putea referi la un domeniu funcțional în care este utilizat un obiect, s-ar putea referi la starea obiectului în sine etc.
în acest caz, modelul de date canonice ca atare ar fi pur și simplu partea galbenă din diagrama următoare:
intersecția dintre A, B și C reprezintă setul de atribute care trebuie să fie acolo indiferent de context (practic atributele obligatorii ale CDM-ului mare anterior). Această parte ar trebui totuși proiectată cu atenție datorită rolului său central. Cu toate acestea, este important să rămânem pragmatici. Dacă în contextul dvs. nu are sens să aveți un model atât de comun, ar trebui să îl aruncați pur și simplu.
ceea ce este de asemenea important este o intersecție între două contexte (a și B, B și C, C și a). Cum de a mapa o reprezentare obiect de la un context la altul? Care sunt atributele explicite care ar trebui împărtășite în două contexte? Care sunt constrângerile comune de afaceri între două contexte? Aceste întrebări ar trebui să răspundă în continuare de o echipă transversală, dar din perspectiva afacerii, este logic să le ridicăm. Acest lucru nu a fost întotdeauna cazul cu un singur CDM partajat în contexte potențial opuse.
cu toate acestea, în ceea ce privește părțile care nu sunt partajate cu alte contexte (în alb), nu ar trebui să facă parte dintr-un model de date de întreprindere. Ar trebui să fii pragmatic. De exemplu, dacă un subset este specific unui anumit domeniu, ar trebui să fie la latitudinea experților domeniului să-l modeleze ei înșiși.
o provocare cheie, deși, este de a identifica aceste contexte delimitate și ar putea fi în valoare de amintind aici Legea lui Conway:
orice organizație care proiectează un sistem va produce inevitabil un design a cărui structură este o copie a structurii de comunicare a organizației.
contextele delimitate nu trebuie neapărat mapate pe organizația curentă. De exemplu, un context limitat poate cuprinde mai multe departamente. Ruperea silozurilor organizaționale ar trebui să fie în continuare un obiectiv pentru majoritatea companiilor.
în plus, DDD introduce conceptul de strat Anticorupție (ACL). Acest model se poate referi la o soluție pentru o migrare moștenită (prin introducerea unui strat de intermediere între Vechiul și Noul sistem pentru a preveni problemele de calitate a datelor etc.). Dar în contextul nostru când vorbim despre corupție este legată de modelarea datelor datoriei puteți introduce pentru a rezolva problemele pe termen scurt.
să luăm exemplul a două sisteme responsabile pentru a gestiona o anumită stare a unei părți PLM (o parte este un element fizic produs sau achiziționat și apoi asamblat ca un rotor de elicopter, de exemplu). Un sistem vechi (să-l numim SystemA) este responsabil pentru gestionarea fazei de proiectare și trebuie să implementați un nou sistem (să-l numim SystemZ) responsabil pentru gestionarea fazei de întreținere. Întregul peisaj al aplicației it împărtășește același identificator comun al părții (partId), cu excepția SystemA care nu este conștient de acesta. În loc de partId, SystemA își gestionează propriul identificator, systemAId. Deoarece SystemZ trebuie să fie call SystemA folosind systemAId, o euristică ar putea fi integrarea systemAId ca parte a modelului de date SystemZ.
aceasta este o greșeală obișnuită pe care ar trebui să o evitați. Pur și simplu v-ați corupt modelul de date din cauza unei situații pe termen scurt.
modelul ACL ar fi putut fi o soluție aici. SystemZ ar fi putut implementa propriul format de date (fără nicio corupție externă precum systemAId). Apoi ar fi fost de până la un strat de intermediere pentru a gestiona traducerea între partId și systemAId.
aplicat subiectului nostru, modelul ACL impune implementarea unui strat între două contexte delimitate diferite. O componentă nu știe cum să numească o altă componentă care nu face parte din propriul context delimitat. În schimb, o componentă este conștientă doar de modul de mapare a propriei structuri de date pe formatul de date al contextului delimitat de care aparține.
apropo, aceasta este o regulă generală. O componentă trebuie să aparțină unui singur context delimitat. Acesta este și motivul pentru care DDD este o potrivire excelentă pentru arhitectura microserviciilor. Datorită granularității cu granulație fină, este mai ușor să se respecte această regulă.
pentru a rezuma, un model canonic ca atare ar trebui considerat ca un anti-model în majoritatea cazurilor. Ar trebui să încercați să implementați conceptul de context delimitat, adică un model pe context, cu limite explicite între contexte. Două componente care fac parte din contexte delimitate diferite ar trebui să comunice printr-un strat Anticorupție pentru a preveni corupția modelării datelor.