acesta este un ghid pas cu pas despre cum se execută K-înseamnă analiza cluster pe o foaie de calcul Excel de la început până la sfârșit. Rețineți că există un șablon Excel care rulează automat analiza clusterului disponibil pentru descărcare gratuită pe acest site web. Dar dacă doriți să știți cum să rulați un K-înseamnă clustering pe Excel, atunci acest articol este pentru dvs.
în plus față de acest articol, am și o prezentare video despre cum să rulați analiza clusterului în Excel.
- pasul unu-începeți cu setul de date
- Pasul doi – în cazul în care doar două variabile, utilizați un grafic scatter pe Excel
- Pasul trei – calculați distanța de la fiecare punct de date până la centrul unui cluster
- cum funcționează calculul?
- Pasul patru-calculați media (medie) a fiecărui set de cluster
- Pasul Cinci-repetați Pasul 3-Distanța față de media revizuită
- etapa finală-Grafic și rezuma clusterele
pasul unu-începeți cu setul de date
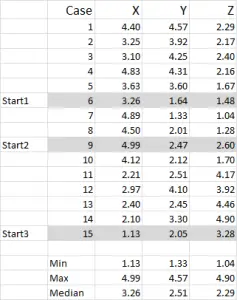
Figura 1
pentru acest exemplu folosesc 15 cazuri (sau respondenți), unde avem datele pentru trei variabile – etichetate generic X, Y și Z.
ar trebui să observați că datele sunt scalate 1-5 în acest exemplu. Datele dvs. pot fi sub orice formă, cu excepția unei scale nominale de date (Consultați articolul despre ce date să utilizați).
notă: prefer să folosesc date scalate-dar nu este obligatoriu. Motivul pentru aceasta este de a „conține” orice valori aberante. Spuneți, de exemplu, că folosesc date privind veniturile (o măsură demografică) – majoritatea datelor ar putea fi în jur de 40.000 până la 100.000 USD, dar am o persoană cu un venit de 5 milioane USD. este mai ușor pentru mine să clasific acea persoană în categoria de venituri „peste 250.000 USD” și să scală venitul 1-9 – dar asta depinde de dvs., în funcție de datele cu care lucrați.
puteți vedea din acest set de exemple că au fost evidențiate trei poziții de pornire – le vom discuta pe cele din Pasul trei de mai jos.
Pasul doi – în cazul în care doar două variabile, utilizați un grafic scatter pe Excel
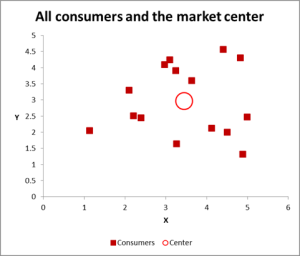
Figura 2
în acest exemplu de analiză a clusterului folosim trei variabile – dar dacă aveți doar două variabile de cluster, atunci o diagramă scatter este o modalitate excelentă de a începe. Și, uneori, puteți cluster datele prin mijloace vizuale.
după cum puteți vedea în acest grafic scatter, fiecare caz individual (ceea ce numesc un consumator pentru acest exemplu) a fost mapat, împreună cu media (medie) pentru toate cazurile (cercul roșu).
în funcție de modul în care vizualizați datele/graficul – se pare că există un număr de clustere. În acest caz, puteți identifica trei sau patru clustere relativ distincte – așa cum se arată în această diagramă următoare.
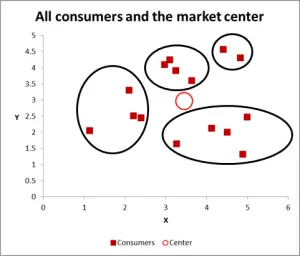
Figura 3
cu acest grafic următor, am identificat în mod vizibil clusterul probabil și le-am încercuit. Așa cum am sugerat, o abordare bună atunci când există doar două variabile de luat în considerare – dar în acest caz avem trei variabile (și ați putea avea mai multe), deci această abordare vizuală va funcționa doar pentru seturile de date de bază – deci acum să ne uităm la cum se face calculul Excel pentru K-înseamnă clustering.
Pasul trei – calculați distanța de la fiecare punct de date până la centrul unui cluster
pentru acest exemplu de trecere, să presupunem că dorim să identificăm doar trei segmente/clustere. Da, există patru clustere evidente în diagrama de mai sus, dar care se uită doar la două dintre variabile. Vă rugăm să rețineți că puteți utiliza această abordare Excel pentru a identifica cât mai multe clustere doriți – trebuie doar să urmați același concept explicat mai jos.
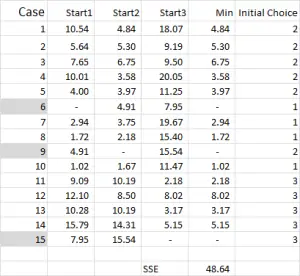
Figura 4
pentru K-înseamnă clustering alegeți de obicei unele cazuri aleatoare (puncte de plecare sau semințe) pentru a obține analiza a început.
în acest exemplu – deoarece doresc să creez trei clustere, atunci voi avea nevoie de trei puncte de plecare. Pentru aceste puncte de pornire am selectat cazurile 6, 9 și 15 – dar orice puncte aleatorii ar putea fi, de asemenea, potrivite.
motivul pentru care am selectat aceste cazuri este că – atunci când ne uităm doar la variabila X – cazul 6 a fost mediana, cazul 9 a fost maximul și cazul 15 a fost minimul. Acest lucru sugerează că aceste trei cazuri sunt oarecum diferite între ele, puncte de plecare atât de bune pe cât sunt răspândite.
vă rugăm să consultați articolul despre motivul pentru care analiza clusterului generează uneori rezultate diferite.
referindu – ne la ieșirea tabelului-acesta este primul nostru calcul în Excel și generează „alegerea inițială” a clusterelor. Start 1 este datele pentru cazul 6, start 2 este cazul 9 și start 3 este cazul 15. Trebuie să rețineți că intersecția fiecăruia dintre acestea dă un 0 (-) în tabel.
cum funcționează calculul?
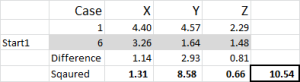
Figura 5
să ne uităm la primul număr din tabel – cazul 1, Începeți 1 = 10,54.
amintiți-vă că am desemnat în mod arbitrar cazul 6 ca fiind punctul nostru de pornire aleatoriu pentru Clusterul 1. Vrem să calculăm distanța și folosim metoda suma pătratelor – așa cum se arată aici. Calculăm diferența dintre fiecare dintre cele trei puncte de date din set, apoi pătrăm diferențele și apoi le însumăm.
o putem face „mecanic” așa cum se arată aici – dar Excel are o formulă încorporată de utilizat: SUMXMY2-aceasta este mult mai eficientă de utilizat.
revenind la figura 4, găsim apoi Distanța minimă pentru fiecare caz de la fiecare dintre cele trei puncte de pornire – aceasta ne spune ce cluster (1, 2 sau 3) este cel mai apropiat de caz – care este prezentat în coloana ‘alegere inițială’.
Pasul patru-calculați media (medie) a fiecărui set de cluster
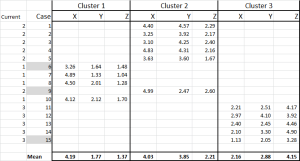
Figura 6
acum am alocat fiecare caz clusterului său inițial-și îl putem stabili folosind o declarație IF într-un tabel (așa cum se arată în Figura 6).
în partea de jos a tabelului, avem media (medie) a fiecăruia dintre aceste cazuri. N0w – în loc să ne bazăm pe un singur punct de date” reprezentativ ” – avem un set de cazuri care reprezintă fiecare.
Pasul Cinci-repetați Pasul 3-Distanța față de media revizuită
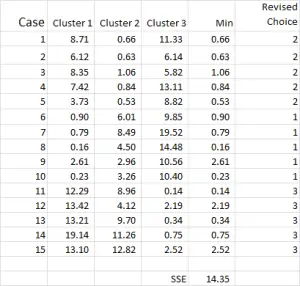
Figura 7
procesul de analiză a clusterului devine acum o chestiune de repetare a pașilor 4 și 5 (iterații) până când clusterele se stabilizează.
de fiecare dată când folosim media revizuită pentru fiecare cluster. Prin urmare, figura 7 arată a doua noastră iterație – dar de data aceasta folosim mijloacele generate în partea de jos a figurii 6 (în loc de punctele de pornire din Figura 1).
acum Puteți vedea că a existat o ușoară schimbare în aplicația cluster, cazul 9 – unul dintre punctele noastre de plecare – fiind realocat.
puteți vedea, de asemenea, suma erorii pătrate (SSE) calculată în partea de jos – care este suma fiecărei distanțe minime. Scopul nostru este să repetăm acum pașii 4 și 5 până când SSE arată doar o îmbunătățire minimă și/sau modificările de alocare a clusterului sunt minore la fiecare iterație.
etapa finală-Grafic și rezuma clusterele
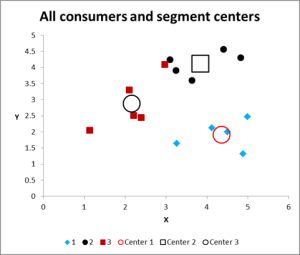
figura 8
după rularea mai multor iterații, avem acum ieșirea pentru Grafic și rezumarea datelor.
aici este graficul de ieșire pentru acest exemplu de analiză cluster Excel.
după cum puteți vedea, există trei clustere distincte prezentate, împreună cu centroizii (media) fiecărui cluster – simbolurile mai mari.
de asemenea, putem prezenta aceste date într-o formă de tabel, dacă este necesar, așa cum am elaborat-o în Excel.
vă rugăm să aruncați o privire la cazul din Cluster 3 – micul pătrat roșu chiar lângă punctul negru din mijlocul de sus al graficului. Acest caz se află acolo din cauza influenței celei de-a treia variabile, care nu este afișată pe această diagramă cu două variabile.