recent, a existat o nouă propunere de schimbare pentru Cassandra indexare care încearcă să reducă compromisul dintre uzabilitate și stabilitate: ceea ce face clauza WHERE mult mai interesant și util pentru utilizatorii finali. Această nouă metodă se numește indexare atașată la stocare (SAI). Nu este cel mai strălucitor nume, dar la ce te aștepți? Inginerii nu sunt cunoscuți pentru denumirea lucrurilor, dar tehnologia rece nu este niciodată o glumă. SAI a captat atenția comunității Cassandra, dar de ce? Indexarea datelor nu este un concept nou în lumea bazelor de date.
modul în care indexăm datele noastre se poate schimba în timp pe baza cazurilor de utilizare dorite și a modelelor de implementare. Cassandra a fost construită combinând aspecte ale Dynamo și Big Table pentru a reduce complexitatea citirii și scrierii deasupra capului, păstrând lucrurile simple. Complexitatea Cassandra a fost în mare parte rezervată naturii sale distribuite și, ca rezultat, a creat un compromis pentru dezvoltatori. Dacă doriți scara incredibilă a Cassandrei, trebuie să vă petreceți timpul învățând cum să modelați datele. Indexurile bazei de date sunt menite să vă îmbunătățească modelul de date și să vă eficientizeze interogările. Pentru Cassandra, acestea au existat într-o anumită formă încă din primele zile ale proiectului. Realitatea nefericită este că nu s-au potrivit bine cu cerințele utilizatorilor. Orice utilizare a indexării vine cu o listă lungă de compromisuri și avertismente până la punctul în care acestea sunt în mare parte evitate și pentru unii, doar un greu nu. Drept urmare, utilizatorii au învățat cum să modeleze date cu interogări de bază pentru a obține cele mai bune performanțe.
acele zile pot fi obtinerea în spatele nostru și caracteristici cum ar fi SAI ne ajută să ajungem acolo.
indici secundari în bazele de date distribuite
nu toți indicii sunt creați egali. Indicii primari sunt, de asemenea, cunoscuți sub numele de cheie unică, sau în vocabularul Cassandra, cheie de partiție. Ca metodă de acces primar în baza de date, Cassandra utilizează cheia de partiție pentru a identifica nodul care deține datele, apoi fișierul de date care stochează partiția de date. Indicele primar citește în Cassandra sunt destul de simple, dar dincolo de domeniul de aplicare al acestui articol. Puteți citi mai multe despre ele aici.
indexurile secundare creează o provocare complet diferită și unică într-o bază de date distribuită. Să ne uităm la un tabel de exemplu pentru a face câteva puncte:
creați utilizatori de masă (
id lung,
firstName text,
text lastName,
text țară,
marca de timp creat,
cheie primară (id)
);
o căutare index primar ar fi destul de simplu ca aceasta:
selectați firstName, lastName de utilizatori în cazul în care id = 100;
ce se întâmplă dacă am vrut să găsească toată lumea în Franța? Ca cineva familiarizat cu SQL, v – ați aștepta ca această interogare să funcționeze:
selectați firstName, lastName din users WHERE country = ‘FR’;
fără a crea un index secundar în Cassandra, această interogare va eșua. Modelul fundamental de acces în Cassandra este prin cheie de partiție. Într-o bază de date nedistribuită ca un RDBMS tradițional, fiecare coloană a tabelului este ușor vizibilă pentru sistem. Puteți accesa în continuare coloana chiar dacă nu există index, deoarece toate există în același sistem și fișiere de date. Indexurile în acest caz ajută la reducerea timpului de interogare, făcând căutarea mai eficientă.
într-un sistem distribuit precum Cassandra, valorile coloanelor sunt pe fiecare nod de date și trebuie incluse în planul de interogare. Aceasta stabilește ceea ce numim scenariul „Scatter-Gather” în care o interogare este trimisă fiecărui nod, datele sunt colectate, îmbinate și returnate utilizatorului. Chiar dacă această operație se poate face pe mai multe noduri simultan, gestionarea latenței se reduce la cât de repede nodul poate găsi valoarea coloanei.
recenzie rapidă a datelor Cassandra scrie
s-ar putea să vă gândiți că adăugarea de indici este despre citirea datelor, care este cu siguranță obiectivul final. Cu toate acestea, atunci când se construiește o bază de date, provocările tehnice privind indexarea sunt părtinitoare în punctul în care sunt scrise datele. Acceptarea datelor la cea mai rapidă viteză în timp ce formatați indexurile în forma cea mai optimă pentru citire este o provocare uriașă. Merită să faceți o revizuire rapidă a modului în care datele sunt scrise într-o bază de date Cassanda la nivelul nodului individual. Consultați următoarea diagramă așa cum am explica cum funcționează.
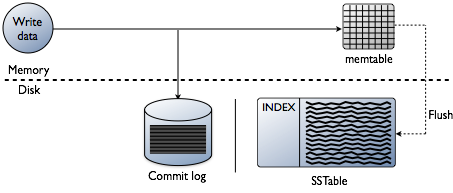
când datele sunt prezentate unui nod, pe care îl numim mutație, calea de scriere pentru Cassandra este foarte simplă și optimizată pentru acea operație. Acest lucru este valabil și pentru multe alte baze de date bazate pe arbori log-Structured Merge(LSM).
- validarea datelor este formatul corect. Tipul de verificare împotriva schemei.
- scrieți date în coada unui jurnal de comitere. Nu caută, doar următorul loc pe indicatorul de fișier.
- scrie date într-un memtable, care este doar un hashmap al schemei în memorie.
terminat! Mutația este recunoscută atunci când se întâmplă aceste lucruri. Îmi place cât de simplu acest lucru este în comparație cu alte baze de date care necesită o blocare și să încerce să efectueze o scriere.
mai târziu, pe măsură ce memtables umple memoria fizică, un proces de spălare scrie segmente într-o singură trecere pe disc într-un fișier numit Sstable (tabel de șiruri sortate). Jurnalul de comitere însoțitor este șters acum că persistența s-a mutat în SSTable. Acest proces continuă să se repete pe măsură ce datele sunt scrise în nod.
detaliu Important: SSTables sunt imuabile. Odată ce sunt scrise, nu se actualizează niciodată, ci doar se înlocuiesc. În cele din urmă, pe măsură ce sunt scrise mai multe date, un proces de fundal numit compactare fuzionează și sortează sstables în altele noi, care sunt, de asemenea, imuabile. Există o mulțime de scheme de compactare, dar, în principiu, toate îndeplinesc această funcție.
acum aveți suficientă bază de bază pe Cassandra, astfel încât să putem obține suficient de tocilar cu indici. Orice profunzime suplimentară a informațiilor este lăsată ca un exercițiu pentru cititor.
probleme cu indexarea anterioară
Cassandra a avut două implementări anterioare de indexare secundară. Stocare atașat indexare secundar (SASI) și indici secundari, care ne referim ca 2i. din nou, punctul meu despre ingineri nu sunt ostentative cu nume deține aici. Indicii secundari au făcut parte din Cassandra de la început, dar implementările le-au făcut supărătoare pentru utilizatorii finali cu lista lor lungă de compromisuri. Cele două preocupări principale pe care le-am tratat în mod constant ca proiect sunt amplificarea scrierii și dimensiunea indexului pe disc. Ca urmare, ele pot fi frustrant tentante pentru utilizatorii noi doar pentru a le eșua mai târziu în implementare. Să ne uităm la fiecare.
indici secundari (2i) — această lucrare originală din proiect a început ca o caracteristică de confort pentru modelele de date timpurii. Mai târziu, pe măsură ce Cassandra Query Language a înlocuit Thrift ca metodă de interogare preferată pentru Cassandra, funcționalitatea 2i a fost păstrată cu sintaxa „creare INDEX”. Dacă ați fi venit de la SQL, aceasta a fost o modalitate foarte ușoară de a învăța legea consecințelor neintenționate. La fel ca în indexarea SQL, cu cât adăugați mai mult, cu atât afectați mai mult performanța de scriere. Cu toate acestea, cu Cassandra, acest lucru a declanșat problema mai mare cu amplificarea scrierii. Referindu-se la calea de scriere de mai sus, indexurile secundare au adăugat un nou pas în cale. Când apare o mutație pe o coloană indexată, se declanșează o operație de indexare care reindexează datele într-un fișier index separat. Mai multe indexuri pe un tabel poate crește dramatic activitatea disc într-un singur rând operație de scriere. Atunci când un nod ia o cantitate mare de mutații, rezultatul poate fi o activitate de disc saturată, care poate face nodurile individuale instabile, oferind 2i îndrumarea meritată de „utilizare cu ușurință.”Dimensiunea indexului este destul de liniară în această implementare, dar cu re-indexarea, cantitatea de spațiu pe disc necesară poate fi greu de planificat într-un cluster activ.
Storage attached Secondary Indexing (SASI) — SASI a fost proiectat inițial de către o echipă mică de la Apple pentru a rezolva o problemă de interogare specifică și nu problema generală a indexurilor secundare. Pentru a fi corect față de acea echipă, a scăpat de ei într-un caz de utilizare pe care nu a fost niciodată conceput să-l rezolve. Bine ați venit la Open source toată lumea. Cele două tipuri de interogare pe care SASI a fost proiectat să le abordeze:
- găsirea rândurilor pe baza potrivirii parțiale a datelor. Wildcard, sau ca interogări.
- interogări interval de date rare, în special marcajele de timp. Câte înregistrări se potrivesc într-un interval de timp interogări de tip.
a făcut ambele operații destul de bine și a abordat și problema amplificării scrierii cu legacy 2i. pe măsură ce mutațiile sunt prezentate unui nod Cassandra, datele sunt indexate în memorie în timpul scrierii inițiale, la fel ca modul în care sunt utilizate memtables. Nici o activitate de disc este necesară pe o permutare. O îmbunătățire uriașă a clusterelor cu multă activitate de scriere. Când memtables sunt spălate la sstables, indicele corespunzător pentru datele este spălată. Fiecare fișier index scris este imuabil și atașat la sstable, de unde și numele de stocare atașat. Când are loc compactarea, datele sunt reindexate și scrise într-un fișier nou pe măsură ce sunt create noi sstables. Din punct de vedere al activității discului, aceasta a fost o îmbunătățire majoră. Dezavantajul SASI a fost în primul rând în dimensiunea indexurilor create. Formatul indexului pe disc a provocat o cantitate enormă de spațiu pe disc utilizat pentru fiecare coloană indexată. Acest lucru le face foarte dificil de gestionat pentru operatori. În plus, SASI a fost marcat ca experimental și nu s-au întâmplat prea multe în ceea ce privește îmbunătățirea caracteristicilor. Multe bug-uri au fost găsite de-a lungul timpului cu remedieri scumpe care au adus discuția dacă SASI ar trebui eliminat cu totul. Dacă aveți nevoie de cea mai profundă scufundare pe această caracteristică, Duy Hai Doan a făcut o treabă uimitoare de a descompune modul în care funcționează SASI.
ceea ce face SAI mai bun
primul, cel mai bun răspuns la această întrebare este că SAI este de natură evolutivă. Inginerii de la DataStax și-au dat seama că arhitectura de bază a indexării secundare trebuie abordată de la bază, dar cu lecții solide care au fost învățate din implementările anterioare. Abordarea problemelor de amplificare a scrierii și dimensiunea fișierului index în timp ce creați o cale pentru îmbunătățiri mai bune ale interogării în Cassandra a fost misiunea principală. Cum abordează SAI ambele subiecte?
Write amplification — după cum am aflat de la SASI, indexarea în memorie și indici de spălare cu SSTables a fost modalitatea corectă de a păstra în conformitate cu modul în care funcționează Cassandra write-path, adăugând în același timp noi funcționalități. Cu SAI, atunci când mutația este recunoscută, adică pe deplin angajată, datele sunt indexate. Cu optimizări și multe teste, impactul asupra performanței de scriere s-a îmbunătățit considerabil. Ar trebui să vedeți mai bine decât o creștere de 40% a debitului și peste 200% latențe de scriere mai bune peste 2i. acestea fiind spuse, ar trebui să planificați în continuare o creștere de 2x latență și debit pe tabelele indexate în comparație cu tabelele neindexate. Pentru a-l cita pe Duy Hai Doan, „nu există magie”, doar inginerie bună.
Dimensiunea indexului — aceasta este cea mai dramatică îmbunătățire și, fără îndoială, unde s-au făcut cele mai multe lucrări. Dacă urmați lumea Internelor bazei de date, știți că stocarea datelor este încă un câmp plin de viață, plin de îmbunătățiri în continuă evoluție. SAI utilizează două tipuri diferite de scheme de indexare bazate pe tipul de date.
- Text – indexurile inversate sunt create cu termeni rupți într-un dicționar. Cea mai mare îmbunătățire este de la utilizarea de indexare bazate pe Trie, care oferă compresie mult mai bine, ceea ce înseamnă dimensiuni mai mici de index.
- Numeric-folosind o structură de date numită block KD-trees, preluată de la Lucene, care oferă performanțe excelente de interogare a intervalului. O listă separată id rând este menținută pentru a optimiza pentru interogări de ordine token.
cu un accent puternic pe stocarea indexului, rezultatul a fost o îmbunătățire masivă a volumului față de numărul de indici de tabel. După cum puteți vedea în graficul de mai jos, indexarea rapidă adusă de SASI a fost rapid eclipsată de explozia utilizării discului. Nu numai că face planificarea operațională o durere, dar fișierele index trebuiau citite în timpul evenimentelor de compactare care ar putea satura discurile care duceau la probleme de performanță a nodului.
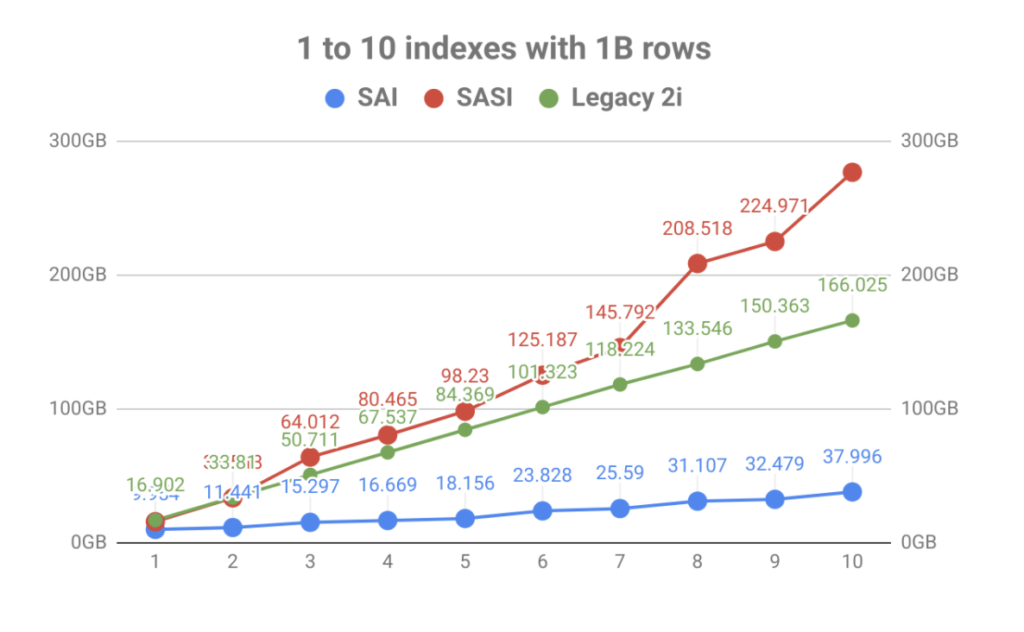
în afara amplificării scrierii și a dimensiunii indexului, arhitectura internă a SAI permite extinderea și adăugarea de funcționalități în viitor. Acest lucru este în conformitate cu obiectivele proiectului de a fi mai modulare în construcțiile viitoare. Aruncați o privire la unele dintre celelalte CEPs care sunt în așteptare și puteți vedea că acesta este doar începutul.
unde se duce SAI de aici?
DataStax a oferit SAI proiectului Apache Cassandra prin procesul de îmbunătățire Cassandra ca CEP-7. Discuția este acum pentru includerea în 4.x ramură a Cassandrei.
dacă doriți să încercați acest lucru acum înainte de a face parte din proiectul Apache Cassandra, avem câteva locuri unde să mergeți. Pentru operatorii sau persoanele cărora le place un pic mai tehnic hands-on, puteți descărca cele mai recente DataStax Enterprise 6.8. Dacă sunteți Dezvoltator, SAI este acum activat în DataStax Astra, Cassandra noastră ca serviciu. Puteți crea un nivel gratuit pentru totdeauna pentru a vă juca cu sintaxa și noua funcționalitate a clauzei where. Cu aceasta, aflați cum să utilizați această caracteristică accesând pagina Cassandra Indexing Skills și documentația inclusă.