Optymalizacja to technika transformacji programu, która stara się ulepszyć kod, sprawiając, że zużywa mniej zasobów (tj. CPU, pamięci) i zapewnia dużą szybkość.
w optymalizacji ogólne konstrukcje programowania wysokiego poziomu są zastępowane bardzo wydajnymi kodami programowania niskiego poziomu. Proces optymalizacji kodu musi być zgodny z trzema zasadami podanymi poniżej:
-
kod wyjściowy nie może w żaden sposób zmieniać znaczenia programu.
-
Optymalizacja powinna zwiększyć szybkość programu i jeśli to możliwe, program powinien wymagać mniejszej liczby zasobów.
-
Optymalizacja sama w sobie powinna być szybka i nie powinna opóźniać całego procesu kompilacji.
wysiłki na rzecz zoptymalizowanego kodu mogą być podejmowane na różnych poziomach kompilacji procesu.
-
na początku użytkownicy mogą zmieniać / zmieniać układ kodu lub używać lepszych algorytmów do pisania kodu.
-
po wygenerowaniu kodu pośredniego kompilator może modyfikować kod pośredni poprzez obliczenia adresów i ulepszanie pętli.
-
podczas tworzenia docelowego kodu maszynowego kompilator może korzystać z hierarchii pamięci i rejestrów procesora.
optymalizację można podzielić na dwa typy: niezależne od Maszyny i zależne od maszyny.
Optymalizacja niezależna od Maszyny
w tej optymalizacji kompilator pobiera kod pośredni i przekształca część kodu, która nie obejmuje żadnych rejestrów procesora i/lub lokalizacji pamięci absolutnej. Na przykład:
do{ item = 10; value = value + item; } while(valueThis code involves repeated assignment of the identifier item, which if we put this way:
Item = 10;do{ value = value + item; } while(valueshould not only save the CPU cycles, but can be used on any processor.
Machine-dependent Optimization
Machine-dependent optimization is done after the target code has been generated and when the code is transformed according to the target machine architecture. It involves CPU registers and may have absolute memory references rather than relative references. Machine-dependent optimizers put efforts to take maximum advantage of memory hierarchy.
Basic Blocks
Source codes generally have a number of instructions, which are always executed in sequence and are considered as the basic blocks of the code. These basic blocks do not have any jump statements among them, i.e., when the first instruction is executed, all the instructions in the same basic block will be executed in their sequence of appearance without losing the flow control of the program.
A program can have various constructs as basic blocks, like IF-THEN-ELSE, SWITCH-CASE conditional statements and loops such as DO-WHILE, FOR, and REPEAT-UNTIL, etc.
Basic block identification
We may use the following algorithm to find the basic blocks in a program:
-
Wyszukiwanie poleceń nagłówka wszystkich bloków podstawowych, od których zaczyna się blok podstawowy:
- pierwsze oświadczenie programu.
- polecenia, które są obiektem docelowym dowolnej gałęzi (warunkowe / bezwarunkowe).
- polecenia, które następują po dowolnej instrukcji oddziału.
-
instrukcje nagłówka i następujące po nich instrukcje tworzą podstawowy blok.
-
blok podstawowy nie zawiera instrukcji nagłówka żadnego innego bloku podstawowego.
bloki podstawowe są ważnymi pojęciami zarówno z punktu widzenia generowania kodu, jak i optymalizacji.
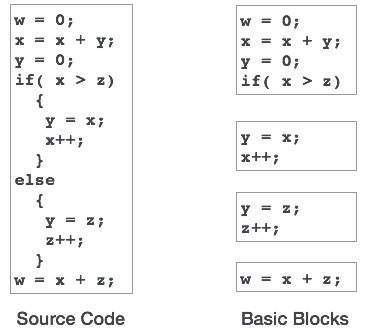
bloki podstawowe odgrywają ważną rolę w identyfikacji zmiennych, które są używane więcej niż raz w jednym bloku podstawowym. Jeśli jakakolwiek zmienna jest używana więcej niż raz, pamięć rejestru przydzielona do tej zmiennej nie musi być opróżniana, chyba że blok zakończy wykonywanie.
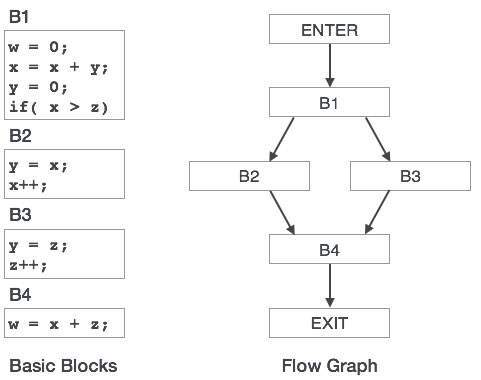
wykres przepływu sterowania
podstawowe bloki w programie mogą być reprezentowane za pomocą wykresów przepływu sterowania. Wykres przepływu sterowania przedstawia sposób przekazywania sterowania programem między blokami. Jest to przydatne narzędzie, które pomaga w optymalizacji, pomagając zlokalizować wszelkie niechciane pętle w programie.
Optymalizacja pętli
większość programów działa w systemie jako pętla. Konieczne staje się zoptymalizowanie pętli w celu zapisania cykli procesora i pamięci. Pętle można zoptymalizować za pomocą następujących technik:
-
Kod niezmienny: fragment kodu, który znajduje się w pętli i oblicza tę samą wartość przy każdej iteracji, nazywa się kodem niezmiennym pętli. Kod ten można przenieść poza pętlę, zapisując go do obliczenia tylko raz, a nie przy każdej iteracji.
-
Analiza indukcyjna: zmienna jest nazywana zmienną indukcyjną, jeśli jej wartość jest zmieniana w pętli przez wartość niezmienniczą pętli.
-
redukcja siły: istnieją wyrażenia, które zużywają więcej cykli procesora, czasu i pamięci. Wyrażenia te należy zastąpić tańszymi wyrażeniami bez uszczerbku dla wyniku wyrażenia. Na przykład mnożenie (x * 2) jest kosztowne pod względem cykli procesora niż (x
eliminacja Martwego kodu
martwy kod to jedno lub więcej poleceń kodu, które są:
- albo nigdy nie są wykonywane lub nieosiągalne,
- lub jeśli są wykonywane, ich wyjście nigdy nie jest używane.
tak więc martwy kod nie odgrywa żadnej roli w żadnym działaniu programu i dlatego można go po prostu wyeliminować.
częściowo martwy kod
istnieją pewne instrukcje kodu, których obliczone wartości są używane tylko w pewnych okolicznościach, tzn. czasami wartości są używane, a czasami nie. Takie kody są znane jako częściowo martwy kod.
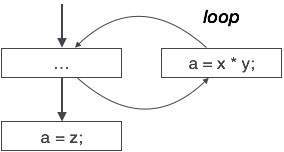
powyższy wykres przepływu sterowania przedstawia fragment programu, w którym zmienna ” a „jest używana do przypisania wyjścia wyrażenia „x * y”. Załóżmy, że wartość przypisana do 'a’ nigdy nie jest używana wewnątrz pętli.Natychmiast po opuszczeniu pętli przez kontrolkę, 'a 'jest przypisywana wartość zmiennej’ z’, która będzie używana później w programie. Wnioskujemy tutaj, że kod przypisania ” a ” nigdy nie jest nigdzie używany, dlatego kwalifikuje się do wyeliminowania.
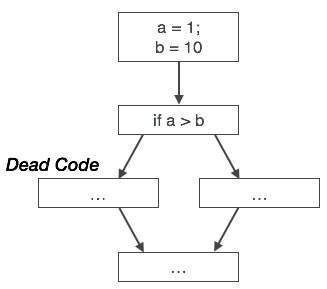
podobnie, powyższy obrazek przedstawia, że instrukcja warunkowa jest zawsze fałszywa, co oznacza, że kod napisany w prawdziwym przypadku nigdy nie zostanie wykonany, dlatego można go usunąć.
redundancja częściowa
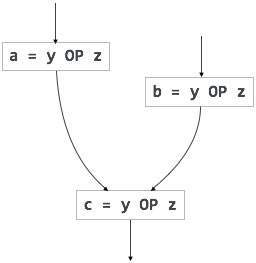
wyrażenia nadmiarowe są obliczane więcej niż jeden raz w ścieżce równoległej, bez żadnych zmian w operandach.podczas gdy wyrażenia częściowo nadmiarowe są obliczane więcej niż raz w ścieżce, bez żadnych zmian w operandach. Na przykład,
|
|
Kod niezmienny pętli jest częściowo redundantny i można go wyeliminować za pomocą techniki code-motion.
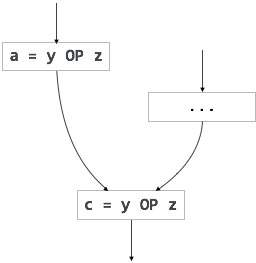
Innym przykładem częściowo nadmiarowego kodu może być:
If (condition){ a = y OP z;}else{ ...}c = y OP z;
Zakładamy, że wartości operandów (y i z) nie są zmieniane z przypisania zmiennej a do zmiennej c. tutaj, jeśli instrukcja condition jest prawdziwa, wtedy y OP Z jest obliczane dwa razy, w przeciwnym razie raz. Code motion może być użyty do wyeliminowania tej redundancji, jak pokazano poniżej:
If (condition){ ... tmp = y OP z; a = tmp; ...}else{ ... tmp = y OP z;}c = tmp;
tutaj, czy warunek jest true czy false; y OP Z należy obliczyć tylko raz.