ostatnio pojawiła się nowa propozycja zmiany indeksowania Cassandra, która próbuje zmniejszyć kompromis między użytecznością a stabilnością: czyniąc klauzulę WHERE znacznie bardziej interesującą i użyteczną dla użytkowników końcowych. Ta nowa metoda nazywa się Storage-Attached Indexing (SAI). To nie jest najfajniejsze imię, ale czego się spodziewasz? Inżynierowie nie są znani z nazywania rzeczy, ale fajna technologia nigdy nie jest żartem. SAI przyciągnął uwagę społeczności Kasandrów, ale dlaczego? Indeksowanie danych nie jest nową koncepcją w świecie baz danych.
sposób, w jaki indeksujemy nasze dane, może się zmieniać w czasie w zależności od pożądanych przypadków użycia i modeli wdrażania. Cassandra została zbudowana z połączenia aspektów Dynamo i Big Table, aby zredukować złożoność odczytu i zapisu, zachowując prostotę. Złożoność Cassandry została zarezerwowana głównie dla jej rozproszonego charakteru i w rezultacie stworzyła kompromis dla programistów. Jeśli chcesz mieć niesamowitą skalę Cassandry, musisz poświęcić czas na naukę modelowania danych. Indeksy baz danych mają na celu ulepszenie modelu danych i zwiększenie wydajności zapytań. Dla Cassandry istnieją one w jakiejś formie od początków projektu. Niefortunną rzeczywistością jest to, że nie zostały one dobrze dopasowane do wymagań użytkownika. Każde użycie indeksowania wiąże się z długą listą kompromisów i ostrzeżeń do tego stopnia, że są one w większości unikane, a dla niektórych po prostu twarde nie. W rezultacie użytkownicy nauczyli się, jak modelować dane za pomocą podstawowych zapytań, aby uzyskać najlepszą wydajność.
te dni mogą być już za nami, a funkcje takie jak SAI pomagają nam tam dotrzeć.
indeksy wtórne w rozproszonych bazach danych
nie wszystkie indeksy są sobie równe. Podstawowe indeksy są również znane jako klucz unikalny, lub w słownictwie Cassandry, klucz partycji. Jako podstawowa metoda dostępu do bazy danych, Cassandra wykorzystuje klucz partycji, aby zidentyfikować węzeł posiadający dane, a następnie plik danych, który przechowuje partycję danych. Podstawowe odczyty indeksu w Cassandrze są dość proste, ale wykraczają poza zakres tego artykułu. Więcej o nich można przeczytać tutaj.
wtórne indeksy tworzą zupełnie inne i unikalne wyzwanie w rozproszonej bazie danych. Spójrzmy na przykładową tabelę, aby uzyskać kilka punktów:
Utwórz użytkowników tabeli (
ID long,
tekst firstName,
tekst lastName,
tekst country,
utworzony znacznik czasu,
klucz podstawowy (id)
);
podstawowe wyszukiwanie indeksu byłoby dość proste:
SELECT firstName, lastName FROM users WHERE id = 100;
co jeśli chciałbym znaleźć wszystkich we Francji? Jako ktoś zaznajomiony z SQL, można oczekiwać, że to zapytanie działa:
wybierz firstName, lastName od users WHERE country = 'FR’;
bez tworzenia dodatkowego indeksu w Cassandrze, to zapytanie nie powiedzie się. Podstawowym wzorcem dostępu w Cassandrze jest klucz partycji. W rozproszonej bazie danych, takiej jak tradycyjny RDBMS, każda kolumna tabeli jest łatwo widoczna dla systemu. Nadal możesz uzyskać dostęp do kolumny, nawet jeśli nie ma indeksu, ponieważ wszystkie istnieją w tym samym systemie i plikach danych. Indeksy w tym przypadku pomagają skrócić czas zapytań, dzięki czemu wyszukiwanie jest bardziej wydajne.
w systemie rozproszonym, takim jak Cassandra, wartości kolumn znajdują się na każdym węźle danych i muszą być uwzględnione w planie zapytań. To ustawia to, co nazywamy scenariuszem „Scatter-Gather”, w którym zapytanie jest wysyłane do każdego węzła, dane są zbierane, scalane i zwracane do użytkownika. Mimo że operacja ta może być wykonywana na wielu węzłach jednocześnie, zarządzanie opóźnieniami ogranicza się do tego, jak szybko węzeł może znaleźć wartość kolumny.
szybki przegląd zapisów danych Cassandry
możesz myśleć, że dodawanie indeksów polega na odczytywaniu danych, co z pewnością jest celem końcowym. Jednak podczas tworzenia bazy danych wyzwania techniczne dotyczące indeksowania są stronnicze w momencie, w którym dane są zapisywane. Przyjęcie danych z największą szybkością przy formatowaniu indeksów w najbardziej optymalnej formie odczytu jest ogromnym wyzwaniem. Warto zrobić szybki przegląd tego, jak dane są zapisywane w bazie Cassanda na poziomie poszczególnych węzłów. Zapoznaj się z poniższym diagramem, jak wyjaśniam, jak to działa.
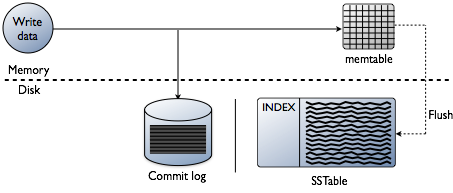
kiedy dane są przedstawiane do węzła, który nazywamy mutacją, ścieżka zapisu dla Cassandry jest bardzo prosta i zoptymalizowana pod kątem tej operacji. Dotyczy to również wielu innych baz danych opartych na drzewach LSM(Log-Structured Merge).
- Sprawdź poprawność danych w odpowiednim formacie. Typ sprawdź według schematu.
- zapisuje dane w ogonie dziennika zmian. Brak poszukiwań, tylko następne miejsce na wskaźniku.
- zapis danych do tabeli pamięci, która jest tylko hashmapą schematu w pamięci.
gotowe! Mutacja jest potwierdzana, gdy takie rzeczy się zdarzają. Uwielbiam to, jak proste jest to w porównaniu do innych baz danych, które wymagają blokady i starają się wykonać zapis.
później, gdy memtables wypełniają fizyczną pamięć, proces flush zapisuje segmenty w jednym przejściu na dysku do pliku o nazwie Sstable (Sorted Strings Table). Dołączony do niego dziennik zmian jest usuwany teraz, gdy trwałość została przeniesiona do SSTable. Proces ten powtarza się, gdy dane są zapisywane do węzła.
ważny szczegół: SSTables są niezmienne. Po ich napisaniu nigdy nie zostaną zaktualizowane, po prostu zastąpione. Ostatecznie, gdy więcej danych jest zapisywanych, proces w tle zwany zagęszczaniem łączy i sortuje sstables do nowych, które również są niezmienne. Istnieje wiele schematów zagęszczania, ale zasadniczo wszystkie pełnią tę funkcję.
masz teraz dość podstaw na Cassandrze, abyśmy mogli uzyskać wystarczająco dużo frajerów z indeksami. Jakakolwiek dalsza głębia informacji pozostaje ćwiczeniem dla czytelnika.
problemy z poprzednim indeksowaniem
Cassandra miała dwie wcześniejsze implementacje wtórnego indeksowania. Storage Attached Secondary Indexing (SASI) i secondary Indexes, które określamy jako 2i. ponownie, mój punkt o Inżynierach nie jest krzykliwy z nazwami trzyma się tutaj. Indeksy wtórne były częścią Cassandry od samego początku, ale implementacje sprawiły, że były kłopotliwe dla użytkowników końcowych z długą listą kompromisów. Dwa główne problemy, którymi stale się zajmujemy jako projekt, to wzmocnienie zapisu i rozmiar indeksu na dysku. W rezultacie mogą one być frustrująco kuszące dla nowych użytkowników tylko po to, aby później nie zawiedli w wdrożeniu. Przyjrzyjmy się każdemu.
indeksy wtórne (2i) — ta oryginalna praca w projekcie rozpoczęła się jako Funkcja wygodna dla wczesnych modeli danych oszczędnościowych. Później, gdy język zapytań Cassandry zastąpił Thrift jako preferowaną metodę zapytań dla Cassandry, funkcjonalność 2i została zachowana ze składnią „CREATE INDEX”. Jeśli pochodzisz z SQL, był to naprawdę łatwy sposób na nauczenie się prawa niezamierzonych konsekwencji. Podobnie jak w indeksowaniu SQL, im więcej dodasz, tym bardziej wpływasz na wydajność zapisu. Jednak w przypadku Cassandry wywołało to większy problem z write-amplification. Odnosząc się do powyższej ścieżki zapisu, indeksy drugorzędne dodały nowy krok do ścieżki. W przypadku wystąpienia mutacji na indeksowanej kolumnie uruchamiana jest operacja indeksowania, która ponownie indeksuje dane w oddzielnym pliku indeksu. Więcej indeksów w tabeli może znacznie zwiększyć aktywność dysku podczas operacji zapisu jednego wiersza. Gdy węzeł przyjmuje dużą ilość mutacji, rezultatem może być nasycona aktywność dysku, która może sprawić, że poszczególne węzły będą niestabilne, dając 2i zasłużone wskazówki „używaj oszczędnie.”Rozmiar indeksu jest dość liniowy w tej implementacji, ale przy ponownym indeksowaniu ilość potrzebnego miejsca na dysku może być trudna do zaplanowania w aktywnym klastrze.
storage Attached Secondary Indexing (SASI) — SASI został pierwotnie zaprojektowany przez mały zespół w Apple w celu rozwiązania konkretnego problemu zapytania, a nie ogólnego problemu drugorzędnych indeksów. Aby być uczciwym wobec tego zespołu, uciekł im w przypadku użycia, którego nigdy nie został zaprojektowany do rozwiązania. Witamy wszystkich w open source. Dwa typy zapytań, które SASI został zaprojektowany do adresowania:
- znajdowanie wierszy na podstawie częściowego dopasowania danych. Wieloznaczne lub podobne zapytania.
- zapytania o zakresy dotyczące rzadkich danych, w szczególności znaczników czasu. Ile rekordów mieści się w zapytaniach typu zakres czasu.
wykonał obie te operacje dość dobrze, a także zajął się problemem amplifikacji zapisu z legacy 2i. ponieważ mutacje są prezentowane w węźle Cassandra, dane są indeksowane w pamięci podczas początkowego zapisu, podobnie jak w przypadku memtables. Podczas permutacji nie jest wymagana aktywność dysku. Ogromna poprawa na klastrach z dużą aktywnością zapisu. Gdy memtables są opróżniane do sstables, opróżniany jest odpowiedni Indeks dla danych. Każdy zapisany plik indeksu jest niezmienny i dołączony do sstable, stąd nazwa Storage Attached. Gdy dochodzi do kompakcji, dane są ponownie zaznaczane i zapisywane do nowego pliku w miarę tworzenia nowych sstables. Z punktu widzenia aktywności dyskowej była to znaczna poprawa. Minusem SASI była przede wszystkim wielkość tworzonych indeksów. Format indeksu na dysku spowodował ogromną ilość miejsca na dysku używanego dla każdej indeksowanej kolumny. To sprawia, że zarządzanie nimi jest bardzo trudne dla operatorów. Ponadto SASI został oznaczony jako eksperymentalny i niewiele się wydarzyło w odniesieniu do poprawy funkcji. Wiele błędów zostało znalezionych z czasem wraz z kosztownymi poprawkami, które wywołały dyskusję, czy SASI należy całkowicie usunąć. Jeśli potrzebujesz głębszego zanurzenia w tej funkcji, Duy Hai Doan wykonał niesamowitą robotę, rozbijając działanie SASI.
to, co czyni SAI lepszym
pierwszą, najlepszą odpowiedzią na to pytanie jest to, że SAI ma ewolucyjną naturę. Inżynierowie z DataStax zdali sobie sprawę, że podstawowa Architektura indeksowania wtórnego musi być rozwiązana od podstaw, ale z solidnymi lekcjami, które zostały wyciągnięte z poprzednich wdrożeń. Rozwiązywanie problemów z amplifikacją zapisu i rozmiarem pliku indeksu podczas tworzenia ścieżki dla lepszych ulepszeń zapytań w Cassandrze było podstawową misją. W jaki sposób SAI odnosi się do obu tych tematów?
wzmocnienie zapisu — jak dowiedzieliśmy się z SASI, indeksowanie w pamięci i płukanie indeksów za pomocą SSTables było właściwym sposobem, aby zachować zgodność z tym, jak działa ścieżka zapisu Cassandra, dodając jednocześnie nową funkcjonalność. W przypadku SAI, kiedy mutacja jest potwierdzona, co oznacza, że jest w pełni zaangażowana, dane są indeksowane. Dzięki optymalizacjom i wielu testom wpływ na wydajność zapisu znacznie się poprawił. Powinieneś zobaczyć lepszy niż 40% wzrost przepustowości i ponad 200% lepsze opóźnienia zapisu powyżej 2i. mając to na uwadze, powinieneś nadal planować wzrost opóźnienia i przepustowości 2x w tabelach indeksowanych w porównaniu do tabel nie indeksowanych. Cytując Duy Hai Doan, „nie ma magii”, po prostu dobra Inżynieria.
rozmiar indeksu-jest to najbardziej dramatyczna poprawa i prawdopodobnie tam, gdzie większość pracy została wykonana. Jeśli śledzisz świat wewnętrznych baz danych, wiesz, że przechowywanie danych jest wciąż żywym polem wypełnionym stale rozwijającymi się ulepszeniami. SAI używa dwóch różnych typów schematów indeksowania opartych na typie danych.
- indeksy tekstowe są tworzone z wyrażeniami podzielonymi na słownik. Największą poprawą jest zastosowanie indeksowania opartego na Trie, które oferuje znacznie lepszą kompresję, co oznacza mniejsze rozmiary indeksów.
- Numeric-wykorzystując strukturę danych o nazwie block KD-trees, zaczerpniętą z Lucene, która oferuje doskonałą wydajność zapytań zakresu. Osobna lista ID wiersza jest utrzymywana w celu optymalizacji dla zapytań token order.
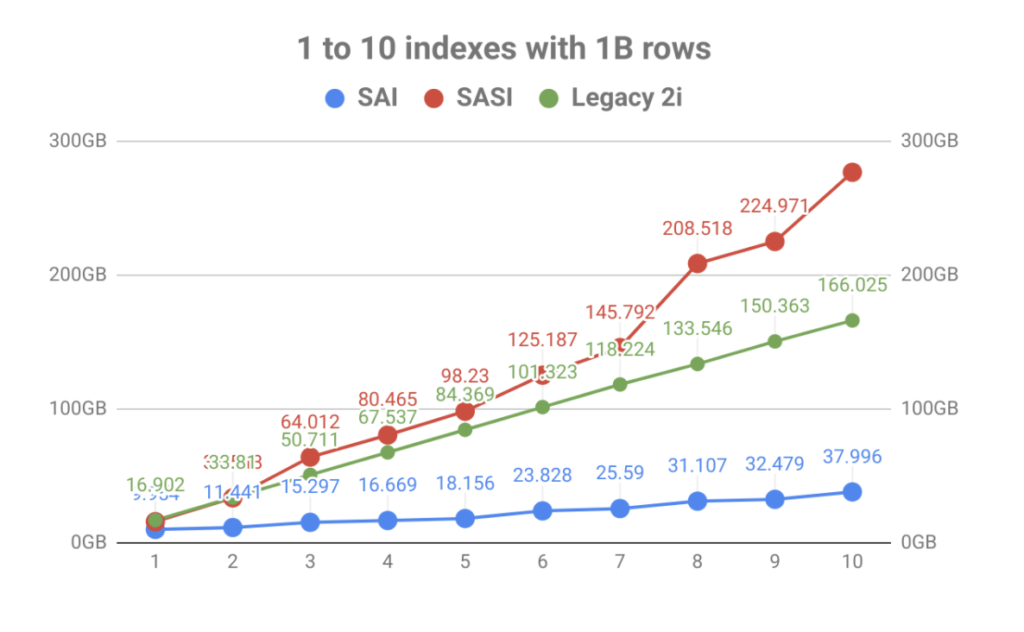
z silnym naciskiem na przechowywanie indeksów, rezultatem była znaczna poprawa wolumenu w stosunku do liczby indeksów tabel. Jak widać na poniższym wykresie, szybkie indeksowanie wprowadzone przez SASI zostało szybko przyćmione przez eksplozję użycia dysku. Nie tylko utrudniało to planowanie operacyjne, ale pliki indeksów musiały być odczytywane podczas zdarzeń zagęszczania, które mogły nasycić dyski, co prowadziło do problemów z wydajnością węzła.
poza wzmocnieniem zapisu i rozmiarem indeksu, wewnętrzna Architektura SAI pozwala na dalszą rozbudowę i dodanie funkcjonalności w przyszłości. Jest to zgodne z celami projektu, które mają być bardziej modułowe w przyszłych kompilacjach. Spójrz na niektóre inne CEPs, które są w toku i widać, że to dopiero początek.
dokąd idzie SAI?
DataStax zaoferował SAI projektowi Apache Cassandra poprzez proces ulepszania Cassandry jako CEP-7. Dyskusja jest teraz do włączenia do 4.X Oddział Cassandry.
jeśli chcesz wypróbować to teraz, zanim stanie się częścią projektu Apache Cassandra, mamy dla Ciebie kilka miejsc do odwiedzenia. Dla operatorów lub osób, które lubią nieco bardziej techniczne praktyczne, możesz pobrać najnowszą wersję DataStax Enterprise 6.8. Jeśli jesteś programistą, SAI jest teraz włączony w DataStax Astra, naszej Cassandra jako usługa. Możesz utworzyć warstwę free-forever, aby bawić się składnią i nową funkcjonalnością klauzuli where. Dzięki temu dowiedz się, jak korzystać z tej funkcji, przechodząc do strony umiejętności indeksowania Cassandry i dołączonej dokumentacji.