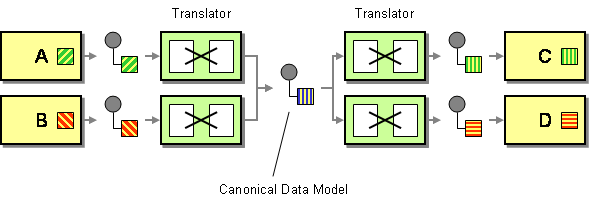
kanoniczny model danych jest zdefiniowany we wzorcach integracji przedsiębiorstwa jako rozwiązanie minimalizujące zależności podczas integracji aplikacji wykorzystujących różne formaty danych. Innymi słowy, komponent (aplikacja lub usługa) powinien komunikować się z innym komponentem za pomocą formatu danych, który byłby niezależny od obu formatów danych komponentu.
dwie rzeczy do podkreślenia tutaj. Najpierw zdefiniowałem komponent jako aplikację lub usługę, ponieważ takie modele są / były używane w kontekście integracji aplikacji i orientacji na usługi. Po drugie, mówimy tu o pojęciu, które powinno być stosowane wyłącznie jako format danych transportowych. Nie należy używać kanonicznego formatu danych jako wewnętrznej struktury magazynu danych.
teoretycznie zalety są dość oczywiste. Kanoniczny format danych zmniejsza sprzężenie między aplikacjami, zmniejsza liczbę tłumaczeń, które należy opracować w celu zintegrowania zestawu komponentów itp. Całkiem interesujące, prawda? Jeden model danych jest zrozumiały dla całego środowiska IT i grupy osób (programistów, analityków systemowych, interesariuszy biznesowych itp.), którzy mogą dzielić tę samą wizję danej koncepcji.
dla celów praktycznych implementacja takich modeli rzadko jest jednak skuteczna.
osoba to nie to samo pojęcie dla Działu Marketingu i wsparcia w firmie ubezpieczeniowej. Lot w systemie zarządzania ruchem lotniczym ma inne znaczenie w zależności od tego, czy został wypełniony przez pilota, czy jest to lot trwający nad przestrzenią powietrzną. Część PLM ma zupełnie inną reprezentację w zależności od tego, czy została zaprojektowana, czy musi być utrzymywana przez zespół wsparcia.
w większości kontekstów projektowanie kanonicznego modelu danych skutkuje dużym modelem danych z pełnym zestawem opcjonalnych atrybutów i bardzo kilkoma obowiązkowymi (takimi jak identyfikatory). Mimo że został zaprojektowany głównie w celu ułatwienia integracji komponentów, po prostu go skomplikować. W międzyczasie twój model stworzy wiele frustracji wśród użytkowników ze względu na jego nieodłączną złożoność (pod względem wykorzystania i zarządzania). Co więcej, jeśli chodzi o problem sprzęgania, po prostu przenosisz go w inne miejsce. Zamiast być połączonym z jednym formatem danych składowych, stajesz się ściśle połączony z jednym wspólnym formatem danych, który będzie używany przez cały krajobraz IT i podlega bardzo częstym zmianom.
w skrócie, w większości kontekstów kanoniczny model danych powinien być uważany za anty-wzorzec. Jaka jest inna opcja niż rozważenie, że nadal powinieneś chcieć zminimalizować zależności między dwoma komponentami wymieniającymi dane?
Domain Driven Design (DDD) zaleca wprowadzenie pojęcia ograniczonego kontekstu. Ograniczony kontekst jest po prostu wyraźnym kontekstem, w którym stosuje się model z wyraźnymi granicami z innymi ograniczonymi kontekstami. W zależności od organizacji Ograniczony kontekst może odnosić się do domeny funkcjonalnej, w której wykorzystywany jest obiekt, może odnosić się do samego stanu obiektu itp.
w takim przypadku kanoniczny model danych jako taki byłby po prostu żółtą częścią poniższego diagramu:
przecięcie A, B I C reprezentuje zbiór atrybutów, które muszą tam być niezależnie od kontekstu (w zasadzie obowiązkowe atrybuty poprzedniego dużego CDM). Ta część nadal powinna być starannie zaprojektowana ze względu na swoją centralną rolę. Ważne jest jednak, aby pozostać pragmatycznym. Jeśli w Twoim kontekście nie ma sensu posiadanie takiego wspólnego modelu, powinieneś go po prostu odrzucić.
ważne jest również przecięcie dwóch kontekstów (A i B, B I C, C i a). Jak odwzorować reprezentację jednego obiektu z jednego kontekstu do drugiego? Jakie są jawne atrybuty, które powinny być współdzielone w dwóch kontekstach? Jakie są wspólne ograniczenia biznesowe między dwoma kontekstami? Na te pytania nadal powinien odpowiadać zespół poprzeczny, ale z biznesowego punktu widzenia warto je podnieść. Nie zawsze tak było w przypadku jednego CDM współdzielonego w potencjalnie przeciwnych kontekstach.
jednak w odniesieniu do części, które nie są współdzielone z innymi kontekstami (w kolorze białym), nie powinny one być częścią korporacyjnego modelu danych. Powinieneś być pragmatyczny. Na przykład, jeśli podzbiór jest specyficzny dla danej domeny, to eksperci domeny powinni sami go modelować.
jednym z kluczowych wyzwań jest jednak zidentyfikowanie tych ograniczonych kontekstów. warto tu przypomnieć prawo Conwaya:
każda organizacja, która projektuje system, nieuchronnie stworzy projekt, którego struktura jest kopią struktury komunikacji organizacji.
ograniczone konteksty nie muszą być mapowane na bieżącą organizację. Na przykład Ograniczony kontekst może obejmować kilka działów. Łamanie silosów organizacyjnych nadal powinno być celem większości firm.
ponadto DDD wprowadza koncepcję warstwy antykorupcyjnej (ACL). Ten wzorzec może odnosić się do rozwiązania dla legacy migration (poprzez wprowadzenie warstwy pośredniczącej między starym a nowym systemem, aby zapobiec problemom z jakością danych itp.). Ale w naszym kontekście, gdy mówimy o korupcji, jest to związane z modelowaniem danych zadłużenia, które można wprowadzić w celu rozwiązania krótkoterminowych problemów.
weźmy przykład dwóch systemów odpowiedzialnych za zarządzanie danym stanem części PLM (część to przedmiot fizyczny wyprodukowany lub zakupiony, a następnie zmontowany jak na przykład Wirnik śmigłowca). Jeden starszy system (Let 's call It SystemA) jest odpowiedzialny za zarządzanie fazą projektowania i musisz wdrożyć nowy system (Let’ s call It SystemZ) odpowiedzialny za zarządzanie fazą konserwacji. Cały krajobraz aplikacji IT posiada ten sam IDENTYFIKATOR części wspólnej (partId), z wyjątkiem systemu, który nie jest tego świadomy. Zamiast partyd, SystemA zarządza własnym identyfikatorem, systemAId. Ponieważ SystemZ musi być wywołany SystemA za pomocą systemAId, heurystyka może być zintegrowana systemAId jako część modelu danych SystemZ.
jest to częsty błąd, którego powinieneś unikać. Po prostu uszkodziłeś swój model danych z powodu krótkoterminowej sytuacji.
wzór ACL mógł być tutaj rozwiązaniem. SystemZ mógł zaimplementować własny format danych (bez jakiejkolwiek zewnętrznej korupcji jak systemAId). Wtedy do warstwy pośredniczącej należało zarządzanie tłumaczeniem między partidem a systemem.
zastosowany w naszym temacie wzorzec ACL wymusza implementację warstwy pomiędzy dwoma różnymi ograniczonymi kontekstami. Komponent nie jest świadomy, jak wywołać inny komponent, który nie jest częścią jego własnego ograniczonego kontekstu. Zamiast tego komponent jest świadomy tylko tego, jak mapować własną strukturę danych na format danych ograniczonego kontekstu, do którego należy.
nawiasem mówiąc, to jest zasada kciuka. Komponent należy tylko do jednego ograniczonego kontekstu. Dlatego też DDD doskonale pasuje do architektury mikrousług. Ze względu na drobnoziarnistą ziarnistość łatwiej jest przestrzegać tej zasady.
podsumowując, model kanoniczny jako taki powinien być uważany za anty-wzór w większości przypadków. Powinieneś spróbować zaimplementować koncepcję kontekstu ograniczonego, co oznacza jeden model na kontekst z wyraźnymi granicami między kontekstami. Dwa komponenty, które są częścią różnych ograniczonych kontekstów, powinny komunikować się za pośrednictwem warstwy antykorupcyjnej, aby zapobiec korupcji w modelowaniu danych.