Dette er en trinnvis veiledning om hvordan du kjører k-means cluster analysis på Et Excel-regneark fra start til slutt. Vær oppmerksom på at Det er En Excel-mal som automatisk kjører cluster analysis tilgjengelig for gratis nedlasting på dette nettstedet. Men hvis du vil vite hvordan du kjører en k-means clustering på Excel selv, så er denne artikkelen for deg.
i tillegg til denne artikkelen har jeg også en video gjennomgang av hvordan du kjører klyngeanalyse I Excel.
- Trinn En-Start med datasettet
- Trinn To-hvis bare to variabler, bruk et punktdiagram I Excel
- Trinn Tre-Beregn avstanden fra hvert datapunkt til midten av en klynge
- hvordan fungerer beregningen?
- Trinn Fire – Beregn gjennomsnittet (gjennomsnittet) for hvert klyngesett
- Trinn Fem-Gjenta Trinn 3-Avstanden fra det reviderte gjennomsnittet
- Siste Trinn-Graf Og Oppsummer Klyngene
Trinn En-Start med datasettet
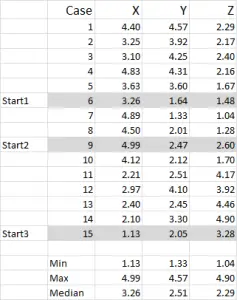
Figur 1
for dette eksemplet bruker jeg 15 tilfeller( eller respondenter), der vi har dataene for tre variabler – generisk merket X, Y Og Z.
du bør legge merke til at dataene er skalert 1-5 i dette eksemplet. Dataene dine kan være i hvilken som helst form bortsett fra en nominell dataskala (se artikkel om hvilke data som skal brukes).
MERK: jeg foretrekker å bruke skalerte data-men det er ikke obligatorisk. Grunnen til dette er å «inneholde» noen uteliggere. Si for eksempel at jeg bruker inntektsdata (et demografisk mål) – de fleste dataene kan være rundt $40.000 til $100.000, men jeg har en person med en inntekt på $5m. det er bare lettere for meg å klassifisere den personen i inntektsbraketten «over $250.000» og skalainntekt 1-9 – men det er opp til deg avhengig av dataene du jobber med.
du kan se fra dette eksempelsettet at tre startposisjoner er uthevet-vi vil diskutere De I Trinn Tre nedenfor.
Trinn To-hvis bare to variabler, bruk et punktdiagram I Excel
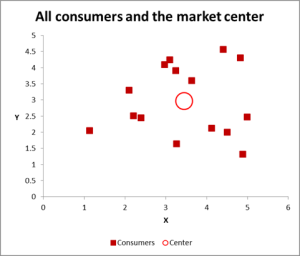
Figur 2
i dette klyngeanalyseeksemplet bruker vi tre variabler-men hvis du bare har to variabler til klynge, er et scatterdiagram en utmerket måte å starte. Og til tider kan du klynge dataene via visuelle midler.
som du kan se i denne scattergrafen, har hvert enkelt tilfelle (det jeg kaller en forbruker for dette eksemplet) blitt kartlagt, sammen med gjennomsnittet (gjennomsnittet) for alle tilfeller (den røde sirkelen).
Avhengig av hvordan du ser dataene / grafen, ser det ut til å være en rekke klynger. I dette tilfellet kan du identifisere tre eller fire relativt forskjellige klynger – som vist i dette neste diagrammet.
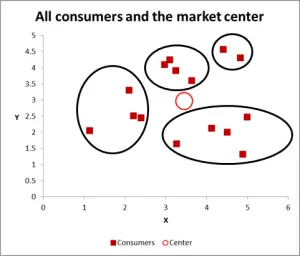
Figur 3
Med denne neste grafen har jeg synlig identifisert sannsynlig klynge og sirklet dem. Som jeg har antydet, en god tilnærming når det bare er to variabler å vurdere-men er dette tilfellet har vi tre variabler (og du kan ha mer), så denne visuelle tilnærmingen vil bare fungere for grunnleggende datasett – så nå la oss se på hvordan Du gjør Excel-beregningen for k-betyr clustering.
Trinn Tre-Beregn avstanden fra hvert datapunkt til midten av en klynge
for dette gjennomgangseksemplet, la oss anta at vi bare vil identifisere tre segmenter / klynger. Ja, det er fire klynger tydelig i diagrammet ovenfor, men det ser bare på to av variablene. Vær oppmerksom på at Du kan bruke Denne Excel-tilnærmingen til å identifisere så mange klynger som du vil-bare følg det samme konseptet som forklart nedenfor.
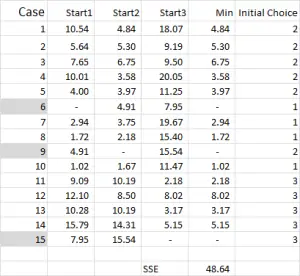
Figur 4
for k-betyr clustering velger du vanligvis noen tilfeldige tilfeller (utgangspunkt eller frø) for å få analysen startet.
i dette eksemplet – da jeg vil lage tre klynger, trenger jeg tre utgangspunkt. For disse startpunktene har jeg valgt tilfeller 6, 9 og 15 – men noen tilfeldige poeng kan også være egnet.
grunnen til at jeg valgte disse tilfellene er fordi – når man ser på variabel x bare-case 6 var medianen, case 9 var maksimum og case 15 var minimum. Dette tyder på at disse tre sakene er noe forskjellig fra hverandre, så gode utgangspunkt som de er spredt ut.
vennligst se artikkelen om hvorfor klyngeanalyse noen ganger genererer forskjellige resultater.
Refererer til tabellutgangen-dette er vår første beregning I Excel, og det genererer vårt «første valg» av klynger. Start 1 er dataene for sak 6, start 2 er sak 9 og start 3 er sak 15. Du bor merke seg at krysset mellom hver av disse gir en 0 (-) i tabellen.
hvordan fungerer beregningen?
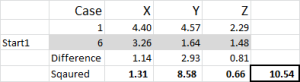
Figur 5
La oss se på det første nummeret i tabellen-sak 1, start 1 = 10,54.
Husk at Vi har vilkårlig utpekt Sak 6 til å være vårt tilfeldige startpunkt For Klynge 1. Vi ønsker å beregne avstanden og vi bruker summen av kvadrater metode-som vist her. Vi beregner forskjellen mellom hver av de tre datapunktene i settet, og deretter kvadrerer forskjellene, og summerer dem deretter.
Vi kan gjøre det «mekanisk» som vist her – Men Excel har en innebygd formel å bruke: SUMXMY2 – DETTE er langt mer effektivt å bruke.
Når Vi refererer Tilbake Til Figur 4, finner vi da minimumsavstanden for hver sak fra hvert av de tre startpunktene – dette forteller oss hvilken klynge (1, 2 eller 3) som saken er nærmest – som er vist i ‘initial choice column’.
Trinn Fire – Beregn gjennomsnittet (gjennomsnittet) for hvert klyngesett
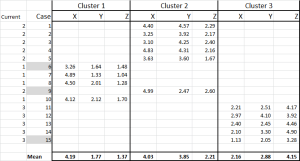
Figur 6
vi har nå tildelt hver sak til sin første klynge-og vi kan legge det ut ved HJELP AV EN IF-setning i en tabell (som vist i Figur 6).
nederst i tabellen har vi gjennomsnittet (gjennomsnittet) av hvert av disse tilfellene. N0w-i stedet for å stole på bare ett» representativt » datapunkt-har vi et sett med saker som representerer hver.
Trinn Fem-Gjenta Trinn 3-Avstanden fra det reviderte gjennomsnittet
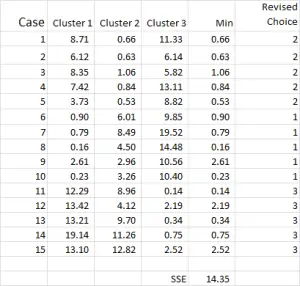
Figur 7
klyngeanalyseprosessen blir nå et spørsmål om å gjenta Trinn 4 og 5 (iterasjoner) til klyngene stabiliserer seg.
hver gang vi bruker det reviderte gjennomsnittet for hver klynge. Derfor Viser Figur 7 vår andre iterasjon – men denne gangen bruker vi midler generert nederst i Figur 6 (i stedet for startpunktene Fra Figur 1).
Du kan nå se at det har vært en liten endring i klyngeprogrammet, med sak 9-et av våre utgangspunkt – blir omfordelt.
du kan også se summen av kvadrert feil (SSE) beregnet nederst-som er summen av hver av minimumsavstandene. Vårt mål er å nå gjenta Trinn 4 og 5 til SSE bare viser minimal forbedring og / eller klyngeallokeringsendringene er små på hver iterasjon.
Siste Trinn-Graf Og Oppsummer Klyngene
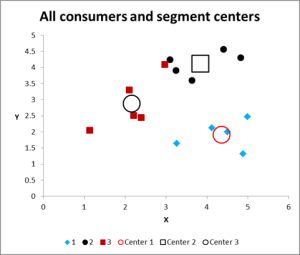
Figur 8
Etter å ha kjørt flere iterasjoner, har vi nå utdataene for å graf og oppsummere dataene.
her er utdatagrafen for denne klyngen analyse Excel eksempel.
som du kan se, er det tre forskjellige klynger vist, sammen med sentroidene (gjennomsnittet) for hver klynge – de større symbolene.
vi kan også presentere disse dataene i en tabellform om nødvendig, da vi har utarbeidet Det i Excel.
ta en titt på saken I Klynge 3 – den lille røde firkanten rett ved siden av den svarte prikken øverst i midten av grafen. Det tilfellet sitter der på grunn av påvirkning av den tredje variabelen, som ikke er vist på dette to variabeldiagrammet.